

目前硕士搬砖,老师给了个任务,下载700篇相关文献,并且把每篇文献按照 *年份-期刊名称-文章题目* 格式来重命名,未处理之前如图:
处理完成之后如图:

对于700篇的文献整理,每一篇要依次点开,寻找对应 “年份 期刊名称 文章题目” ;这个工作量显然是灾难, 且重复操作没有营养,想写一个程序自动完成。
第一步:获取每一篇文献的相关信息。若用程序直接读取pdf文件,寻找信息是相当困难的,因为我的这700篇文献中“年份 期刊名称 文章题目”出现位置极不规律,可以说一篇一个样,随便贴两张图:


可以看出,*“年份 期刊名称 文章题目”*出现很不一样,无法通过一种固定的方法获取,在“哥们”的帮助之下,获得了一个神奇的软件:Zotero,下载链接(https://www.zotero.org/download/),把文章导入之后可以自动获得一系列信息,如图:
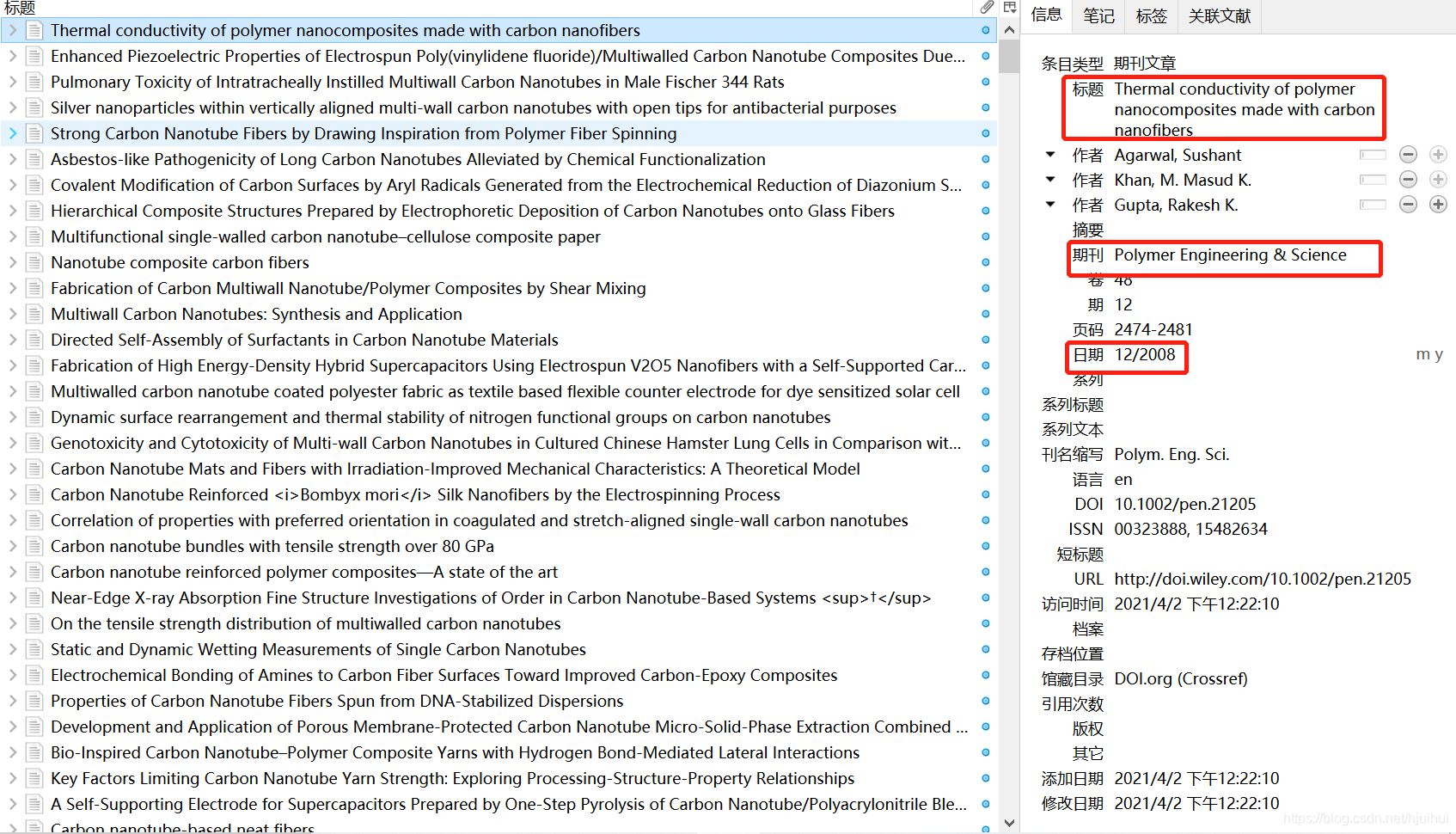
通过导入的操作,可以获得每一篇的相关信息,此软件可以将这些信息输出为.csv文件,如图:

第二步:从这里选择需要的信息,然后再通过python代码,就可以批量命名啦,源程序直接上:
import os,csv
path = "C:/Users/e2164\Desktop/2"+"/" #文献文件所在位置
new_name = csv.reader(open(r'C:\Users\e2164\Desktop\wenxin.csv', encoding='utf-8')) #导出的excel文件所在位置
New=[]
for i in new_name: #获取表格想要信息,我这里选择的是 “年份 期刊名称 文章题目“
name=i[0]+'-'+i[1]+'-'+i[2] #这是把这些信息整合在一起
New.append(name)
print('导入完成')
# 获取该目录下所有文件,存入列表中
f = os.listdir(path)
print(len(f))
print(f[0])
n = 0
i = 0
j = 1
for i in f:
# 设置旧文件名(就是路径+文件名)
oldname = f[n]
# 设置新文件名
newname = New[n]+'.pdf'
# 用os模块中的rename方法对文件改名
try:
os.rename(path+oldname, path+newname)
print(oldname, '======>', newname) #命名成功的
except:
os.rename(path + oldname, path + 'error'+str(j)+'.pdf')
print(j)
j += 1 #命名失败的
n += 1
注意:
1、有些文献的题目中含有“/ \ < > * ? : ”,这样的字符是不允许出现的,所以在表格中把这些符号预先替换掉,从而大大提高成功率。
2、excel文件中的文献排列顺序要和文献文件顺序排列一致,否则出现“张冠李戴”。

说明 本章主要说明如何使用Magicodes.IE.Csv进行Csv导入导出. 关于Magicodes.IE ...
1.信任就像一张纸,皱了,即使抚平,也恢复不了原样了。 2.慢慢的发现,爱一个...
简言 在做用户实名验证时,常会用到身份证号码的正则表达式及校验方案。本文列举...
想了解更多内容,请访问: 51CTO和华为官方战略合作共建的鸿蒙技术社区 https://...
简介 “ 大家好我是帅哥欢迎来到帅哥的程序人生我会把经历分享出来助你了解圈内...
作者:MarkVogels 翻译:黯魂[S.S.T] 在这篇文档中,我将会试着为你提供一个对于...
php语言是一种脚本语言,它能够做很多事情比如说它可以用来与数据库交互开发web...
在讲网页表格的结构化标记之前,还是先看几幅图片。 Html表格的结构化 所谓的结...
文章目录 Java基础语法三——运算符 一、算术运算符 1.基本四则运算符 1练习 2注...
写在前面 微软在更新.Net Core版本的时候,动作往往很大,使得每次更新版本的时...

