—需求:爬取校花网中全部图片的名称
http://www.521609.com/meinvxiaohua/
实现方式:
将所有页面的ur L添加到start_ urls列表(不推荐)
自行手动进行请求发送(推荐)
手动请求发送: yield scrapy. Request (url, callback) : callback专用做于数据解析
创建scrapy以及基于管道的持久化存储:请点击此处查看
import scrapy
from meinvNetwork.items import MeinvnetworkItem
class MnspiderSpider(scrapy.Spider):
name = 'mnSpider'
#allowed_domains = ['www.xxx.com']
start_urls = ['http://www.521609.com/meinvxiaohua/']
url = 'http://www.521609.com/meinvxiaohua/list12%d.html'
page_num = 2
def parse(self, response):
li_list = response.xpath('//*[@id="content"]/div[2]/div[2]/ul/li')
for li in li_list:
name = li.xpath('./a[2]/b/text() | ./a[2]/text()').extract_first()
item = MeinvnetworkItem(name=name)
yield item
if self.page_num <= 11:
new_url = format(self.url%self.page_num)
self.page_num += 1
yield scrapy.Request(url=new_url,callback=self.parse)
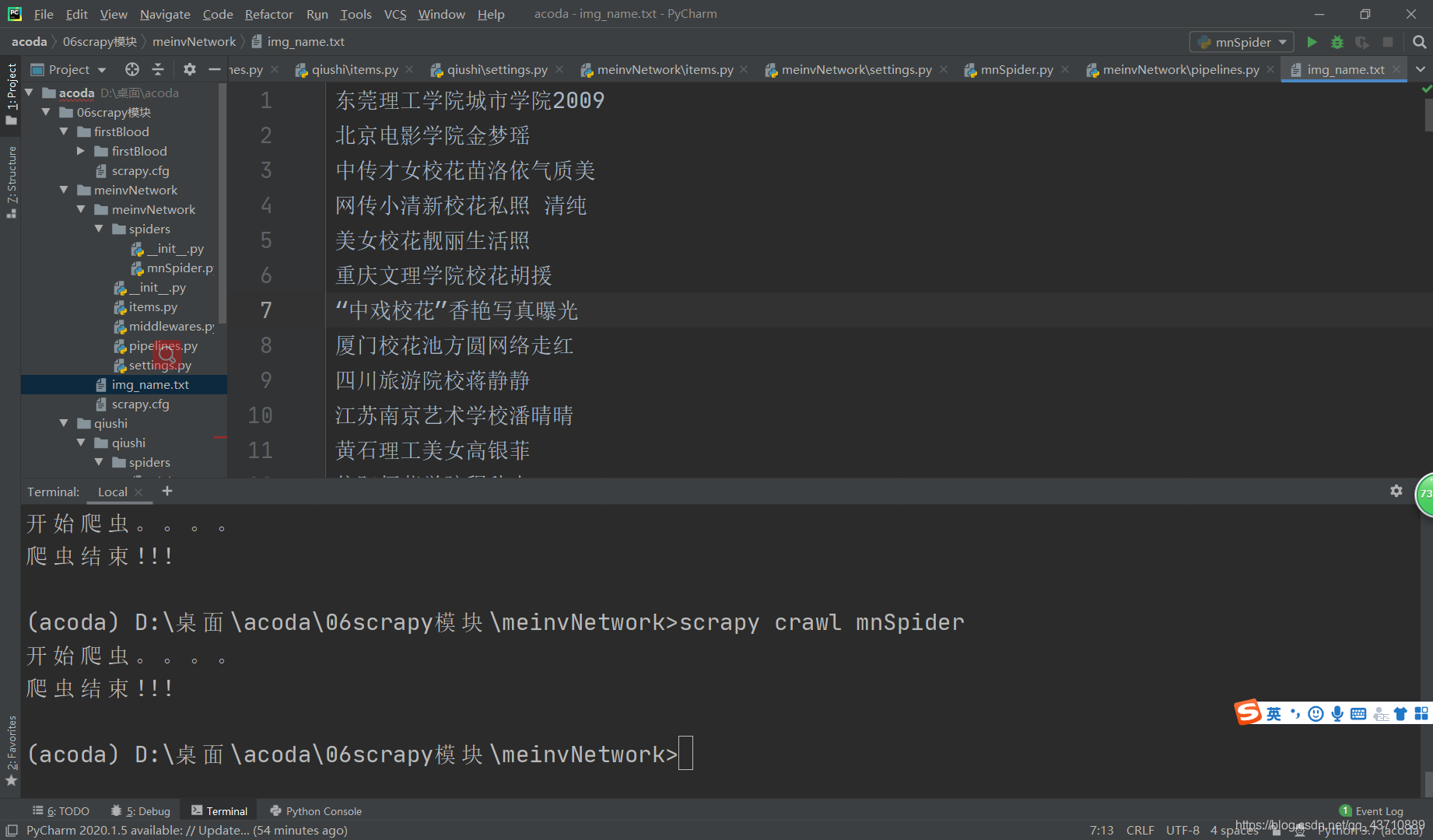
使用终端命令执行项目:scrapy crawl mnSpider
效果图

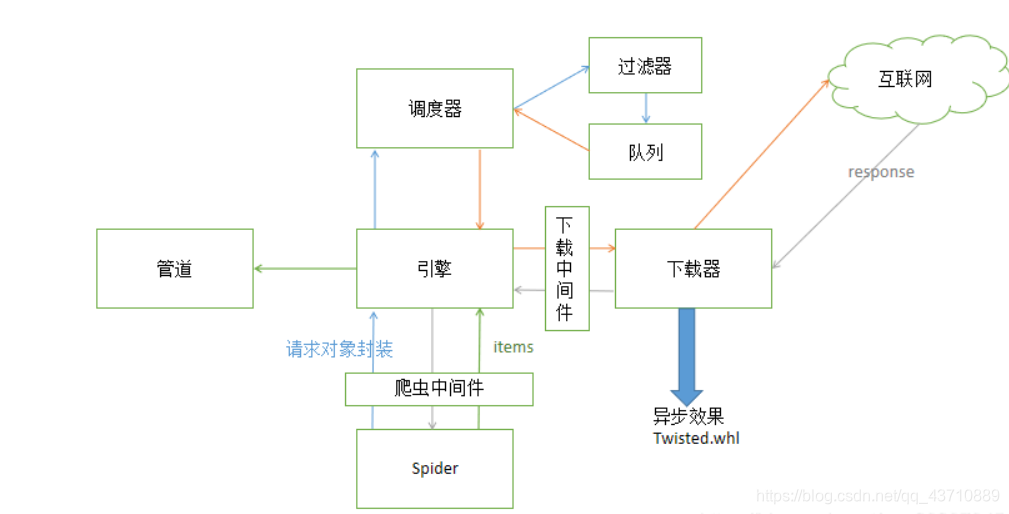
引擎(Scrapy)
调度器(Scheduler)
下载器(DownLoader)
爬虫(spiders)
项目管道(Pipeline)
使用场景:如果爬取解析的数据不在同一张页面中。(深度爬取)
详见案例:爬取网易新闻
图片数据爬取(ImagesPipeline)
基于scrapy爬取字符串类型的数据和爬取图片类型的数据区别
— 字符串:只需要基于小path进行解析且提交管道进行持久化存储
— 图片:xpath解析出图片src的属性值。单独的对图片地址发起请求获取图片二进制类型的数据。
使用流程:
— 数据解析(图片地址)
— 将存储图片地址的item提交到指定的管道类
— 在管道文件中自制一个机遇ImagesPipeline的管道类
? — def get_media_requests(self,item,info):#根据图片地址进行数据请求
? — def file_path(self,request,response=None,info=None):#指定图片存储类型
? —def item_completed(self,results,item,info):#返回给下一个即将执行的管道类
— 在配置文件中:
? — 指定图片存储的目录:IMAGES_STORE = './img_temp'
? — 指定开启的管道:自制定的管道类
img.py
import scrapy
from imgsPro.items import ImgsproItem
class ImgSpider(scrapy.Spider):
name = 'img'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://sc.chinaz.com/tupian/']
def parse(self, response):
div_list = response.xpath('//div[@id="container"]/div')
for div in div_list:
#注意伪属性
img_url = 'https:' + div.xpath('./div/a/img/@src2').extract()[0]
item = ImgsproItem(img_url=img_url)
yield item
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ImgsproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img_url = scrapy.Field()
#pass
pipeline.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# class ImgsproPipeline:
# def process_item(self, item, spider):
# return item
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class imgsPipeLine(ImagesPipeline):
#根据图片地址进行数据请求
def get_media_requests(self,item,info):
yield scrapy.Request(item['img_url'])
#指定图片存储类型
def file_path(self,request,response=None,info=None):
imgName = request.url.split('/')[-1]
return imgName
# def item_completed(self,results,item,info):
# return item #返回给下一个即将执行的管道类
setting.py
BOT_NAME = 'imgsPro'
SPIDER_MODULES = ['imgsPro.spiders']
NEWSPIDER_MODULE = 'imgsPro.spiders'
LOG_LEVEL = 'ERROR'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'imgsPro (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'imgsPro.pipelines.imgsPipeLine': 300,
}
#指定图片存储路径
IMAGES_STORE = './img_temp'
https://news.163.com/
需求:爬取网易新闻中的新闻数据(标题和内容)
目录层级
wangyi.py
import scrapy
from selenium import webdriver
from wangyiPro.items import WangyiproItem
class WangyiSpider(scrapy.Spider):
name = 'wangyi'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://news.163.com/']
model_urls = []
def __init__(self):
self.bro = webdriver.Chrome(executable_path=r"E:\google\Chrome\Application\chromedriver.exe")
def parse(self, response):
li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
alist = [3,4,6,7,8]
for i in alist:
model_url = li_list[i].xpath('./a/@href').extract_first()
self.model_urls.append(model_url)
for url in self.model_urls:
yield scrapy.Request(url,callback=self.model_parse)
def model_parse(self,response):
div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div')
for div in div_list:
title = div.xpath('./div/div[1]/h3/a/text()').extract_first()
new_detail_url = div.xpath('./div/div[1]/h3/a/@href').extract_first()
if new_detail_url == None:
continue
item = WangyiproItem()
item['title'] = title
yield scrapy.Request(url=new_detail_url,callback=self.parse_detail,meta={'item':item})
def parse_detail(self,response):
content = response.xpath('//*[@id="content"]/div[2]//text()').extract()
content = ''.join(content)
item = response.meta['item']
item['content'] = content
yield item
def closed(self,spider):
self.bro.quit()
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class WangyiproItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
content = scrapy.Field()
middlewares.py
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
from scrapy.http import HtmlResponse
from time import sleep
class WangyiproDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
bro = spider.bro
if request.url in spider.model_urls:
bro.get(request.url)
sleep(2)
page_text = bro.page_source
new_response = HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request)
return new_response
else:
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class WangyiproPipeline:
fp = None
# 重写父类的一个方法:该方法只在爬虫开始的时候被调用一次
def open_spider(self, spider):
print('开始爬虫。。。。')
self.fp = open('./wangyi.txt', 'w', encoding='utf-8')
def close_spider(self, spider):
print('爬虫结束!!!')
self.fp.close()
def process_item(self, item, spider):
title = item['title']
content = item['content']
self.fp.write(title+content + '\n')
return item
setting.py
BOT_NAME = 'wangyiPro'
SPIDER_MODULES = ['wangyiPro.spiders']
NEWSPIDER_MODULE = 'wangyiPro.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'
LOG_LEVEL = 'ERROR'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'wangyiPro.pipelines.WangyiproPipeline': 300,
}
效果图
CrawlSpider是Spider的一个子类
全站数据爬取方式:
CrawlSpider的使用:
cd XXX
scrapy genspider -t crawl xxx www.xxx.com
例子:
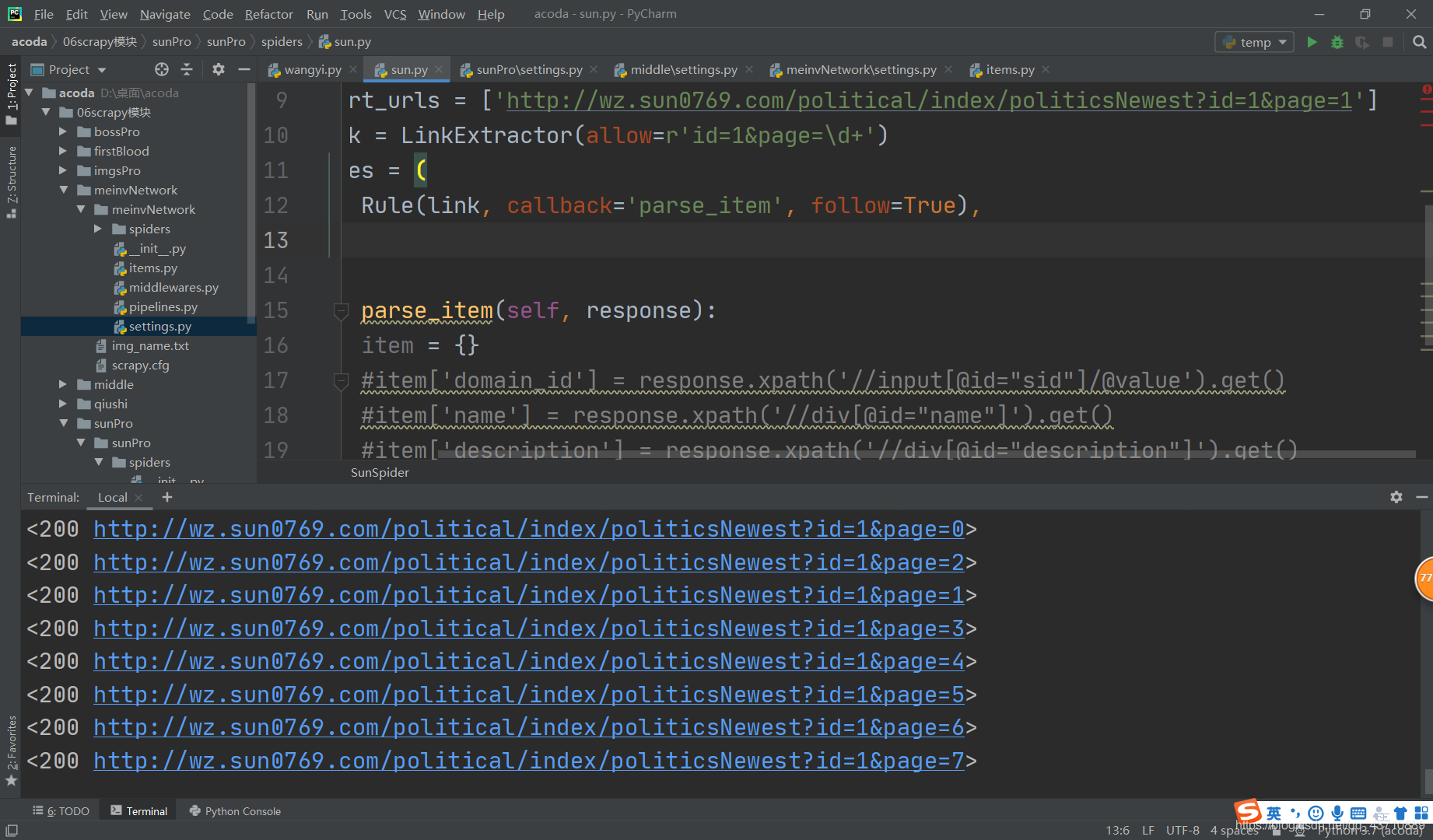
http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1
sun.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class SunSpider(CrawlSpider):
name = 'sun'
#allowed_domains = ['www.xxx.com']
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1']
link = LinkExtractor(allow=r'id=1&page=\d+')
rules = (
Rule(link, callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
#return item
print(response)

详解Spring Controller autowired Request变量 spring的DI大家比较熟悉了,对于...
需要注意的是,调用的封装的数据库,和jQuery的保存地址 一、注册 (1)写文本框...
最近在学习jQuery时接触到了show()、hide()、toggle()函数,于是利用这几个函数...
git clone支持https和git(即ssh)两种方式下载源码: 当使用git方式下载时,如...
多年以后,面对台下五彩斑斓的Jetbrain和Vscode用户,这位曾经的资深的vim追随者...
大家好我是爱景甜的网工我是一个思科出身专注于华为的网工 好了话不多说进入正题...
一个常见的场景,获取:标签背景图片链接: 如字符串:var bgImg = "url (\" htt...
1 概述 在接下来的时间里,将会入手ASP.NET MVC这一专题,尽量用最快的时间,最...
在Asp.net Core之前所有的Action返回值都是ActionResult,Json(),File()等方法返...
在新的MySQL 8.0.23中,引入了新的有趣功能:不可见列。 这是第一篇关于这个新功...