

在安装 Hadoop 之前,需要先安装两个程序,分别为:
(1) JDK。Hadoop 使用的是 Java 写的程序,Hadoop 的编译及 MapReduce 的运行都需要使用 JDK。因此在安装 Hadoop 之前,必须先安装 JDK。
(2) SSH(安全外壳协议),推荐安装 OpenSSH。Hadoop 需要通过 SSH 无密码连接 Slave 列表中各台主机的守护进程,因此 SSH 也是必须安装的。
本节介绍 JDK 的检查与安装。
在安装 JDK 之前,可以首先检查一下系统是否安装了 JDK,检查方法如下。打开终端,输入以下内容,来检查 JDK 是否可用:
javac
如果没有安装 JDK 的话,执行结果如下图所示:
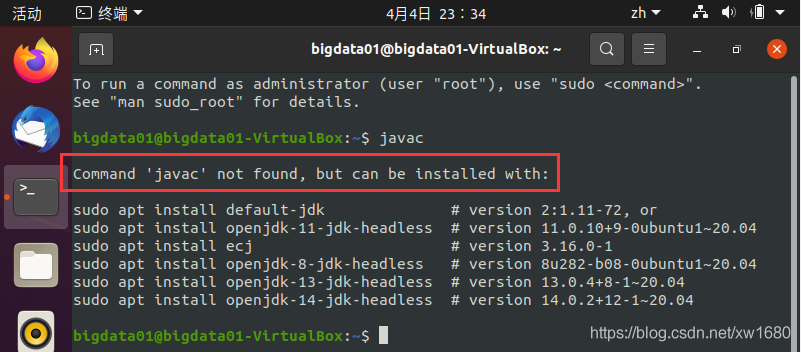
如果上述命令返回 Command 'java' not found 或者类似的错误,这时需要下载并安装 JDK。本篇博文用的 jdk 版本为:jdk-8u202-linux-x64.tar.gz。如果读者要安装其他版本的 jdk,可以自行到官网进行下载,jdk 下载比较简单,这里博主就不再赘述,不想下载也可以直接从下面的网盘中进行获取,链接如下:
链接:https://pan.baidu.com/s/1M_uFasC58iLB5HtzmnZWdQ
提取码:i8yt
复制这段内容后打开百度网盘手机App,操作更方便哦--来自百度网盘超级会员V6的分享
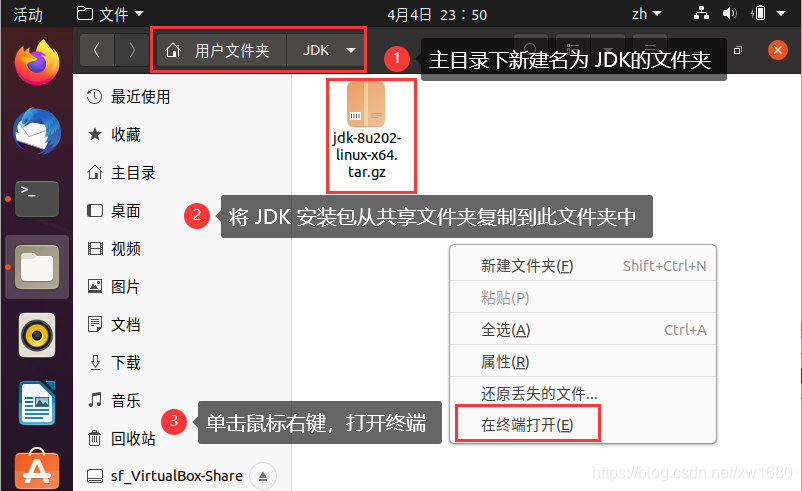
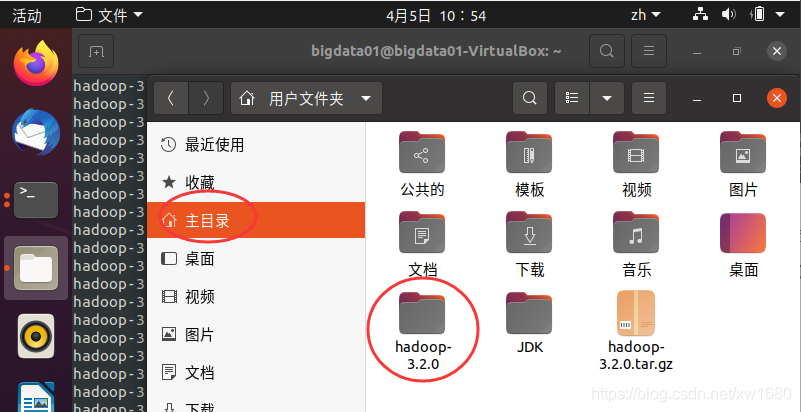
(1) 将下载好的 JDK 安装包放到共享文件夹中 (在 2021年全网最细 VirtualBox 虚拟机安装 Ubuntu 20.04.2.0 LTS及Ubuntu的相关配置 一文中详细介绍了如何设置了共享文件夹,博主 Windows 10 系统的共享文件夹路径为 D:\VirtualBox-Share,Ubuntu 系统中的共享文件夹名为 sf_VirtualBox-Share)
然后在 Ubuntu 系统的 home 目录(也称为主目录)下,新建文件夹名为 JDK,将 JDK 安装包复制此 JDK 文件夹中。复制好之后,在此文件夹空白处单击鼠标右键,选择 在终端打开,打开终端,如下图所示:
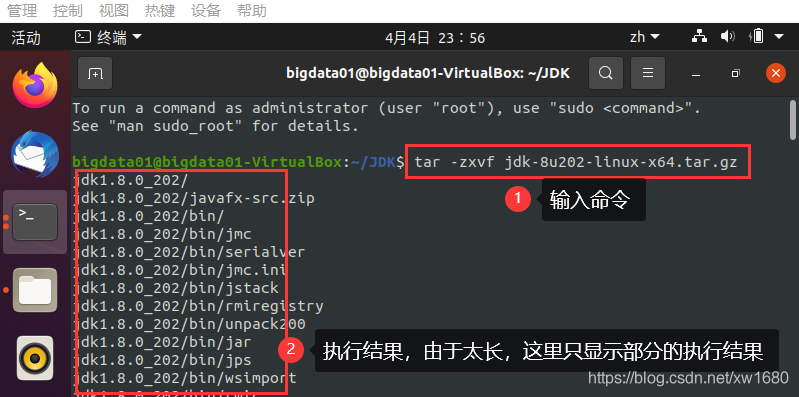
(2) 解压 JDK 安装包。将安装包 jdk-8u202-linux-x64.tar.gz 解压到当前文件夹,命令如下:
tar -zxvf jdk-8u202-linux-x64.tar.gz
命令及执行结果如下图所示:
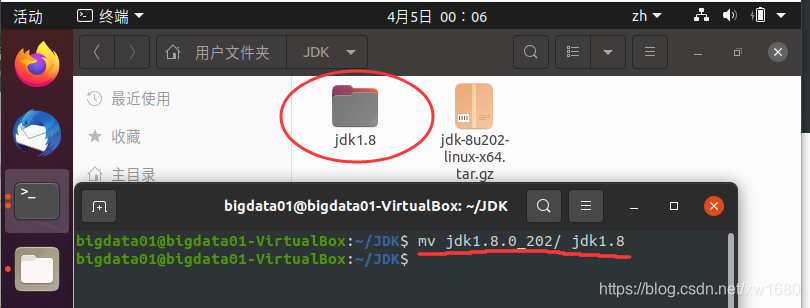
解压完成后,在当前文件夹中,得到名为 jdk1.8.0_191 的文件夹,为了后期设置环境变量更加方便,将名字重命名为 jdk1.8,如下图所示:
说明:解压即安装。
(3) 设置环境变量。编辑配置文件,首先需要打开配置文件,然后将环境变量添加到文件末尾。
在终端输入如下命令,打开配置文件。
sudo gedit /etc/profile
然后按照提示,输入 root 用户的密码,输入密码后,敲击回车进入文档编辑界面,如下图所示:
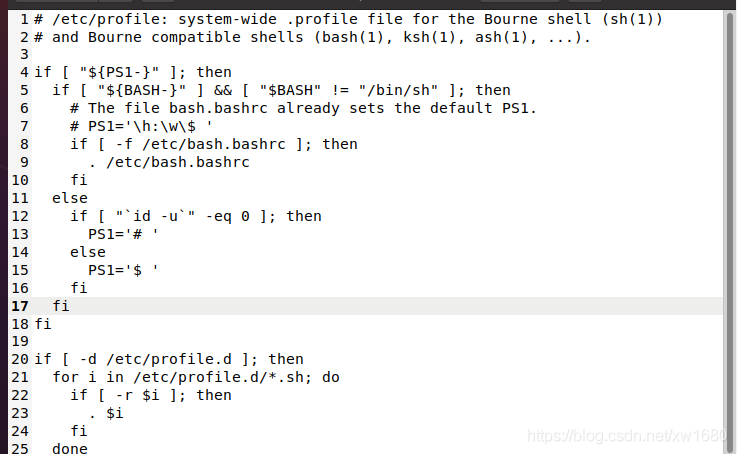
将下面的命令输入到配置文件中:
export JAVA_HOME=/home/bigdata01/JDK/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
注意,JAVA_HOME 后面的为解压后的 JDK 文件夹,读者需要根据实际情况进行修改。配置文件修改完成后,Ctrl + s 即可保存然后退出。重新加载配置文件,命令如下:
source /etc/profile
验证是否安装 JDK 成功,输入如下命令查询 JDK 版本:
java -version
执行结果如下图所示:
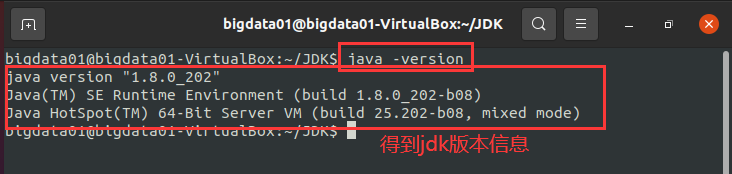
如上图所示的执行结果中,显示了 JDK 的版本信息,则说明 JDK 安装成功。
说明:也可以使用 sudo vi /etc/profile 命令打开配置文件,然后按照提示,输入 root 用户的密码,输入密码后,敲击回车进入文档编辑界面。使用快捷键 <Shift+g> 将光标移到文件末尾,按 i 键进入编辑状态,将上面的命令输入到配置文件中,配置文件修改完成后,按 Esc 退出编辑状态,输入 :wq 命令,敲击回车之后即可保存并退出。最后重新加载配置文件即可。
SSH 为 Secure Shell 的缩写,即安全外壳协议,为建立在应用层基础上的安全协议。Hadoop 使用 SSH 连接,这是目前较为可靠,专为远程登录其他服务器提供的安全性协议。通过 SSH 会对所有传输的数据进行加密,利用 SSH 协议可以防止远程管理系统时信息外泄的问题。
Hadoop 是由很多台服务器组成的,当启动 Hadoop 时,NameNode 必须与 DataNode 连接并管理这些节点(DataNode),此时系统会要求用户输入密码。为了让系统顺利运行而不用手动输入密码,可以将 SSH 设置为无密码登录。
注意:无密码登录不是不需要密码,而是使用 SSH Key 来进行身份验证。
1、安装SSH
打开终端,输入命令:sudo apt-get install ssh
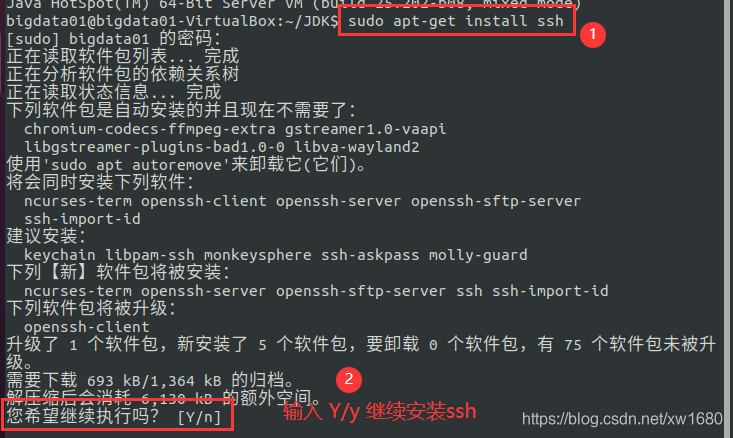
在输入 Y 或 y 后,系统会自动安装 SSH,安装完成如下图所示:
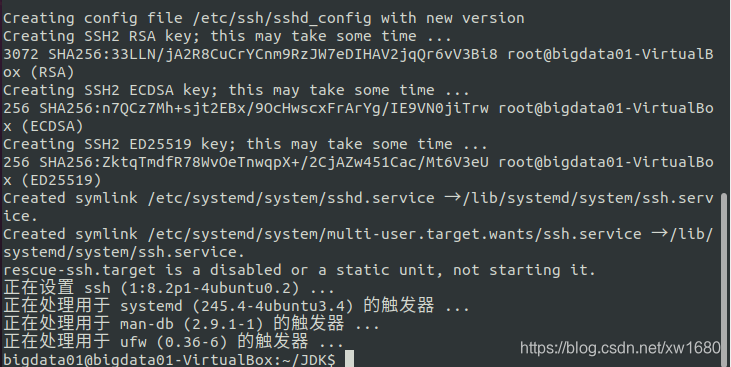
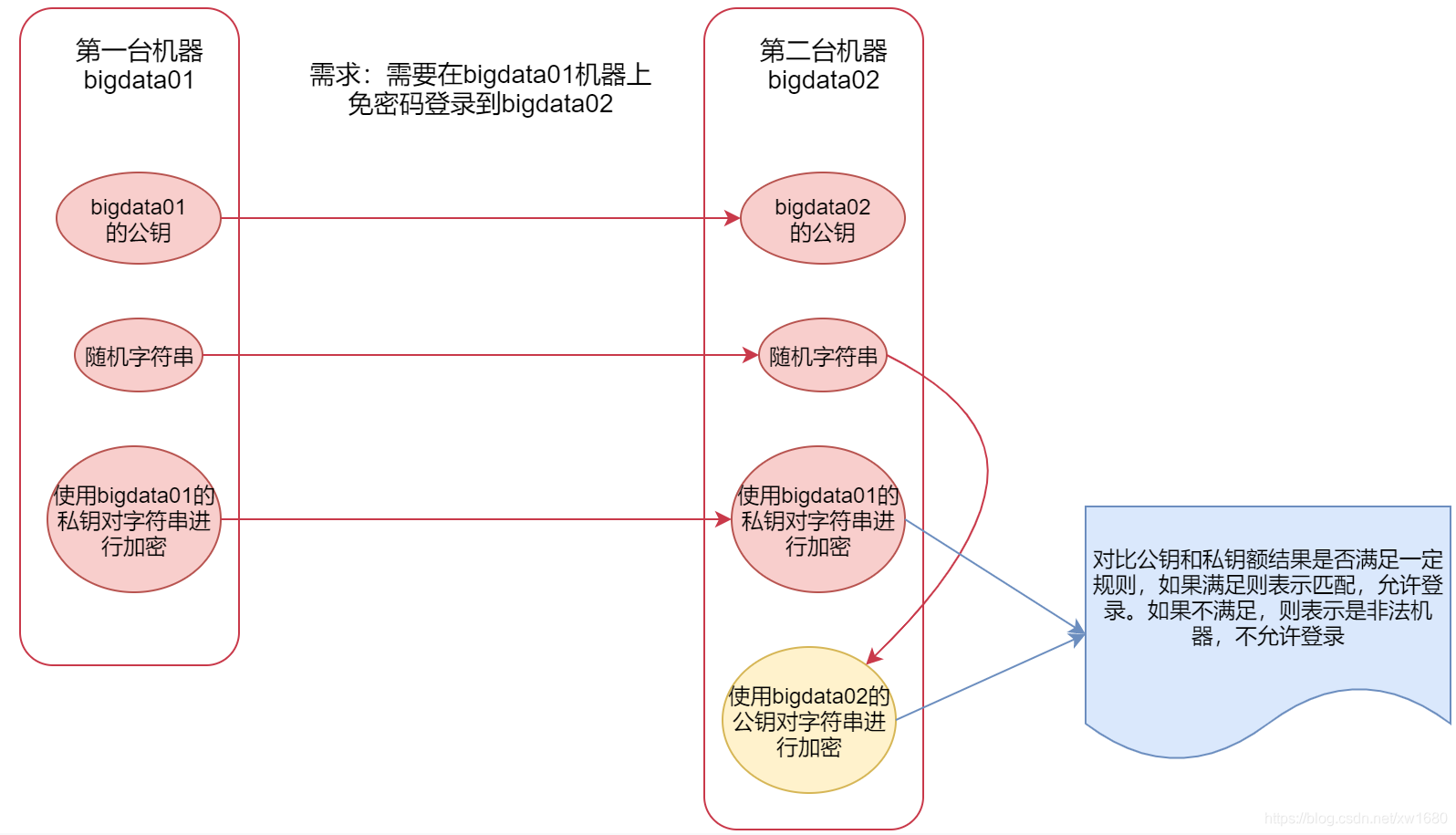
2、SSH 无密码登录的原理
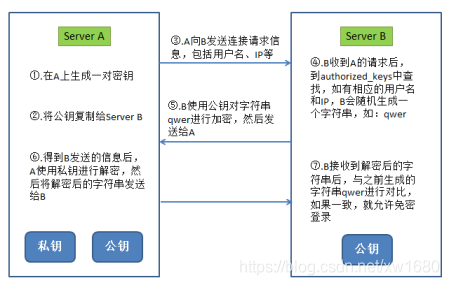
在配置 SSH 之前,首先介绍一下 SSH 免密登录的原理,以 Server A 要免密登录 Server B 为例,如下图所示:
3、配置 SSH 无密码登录
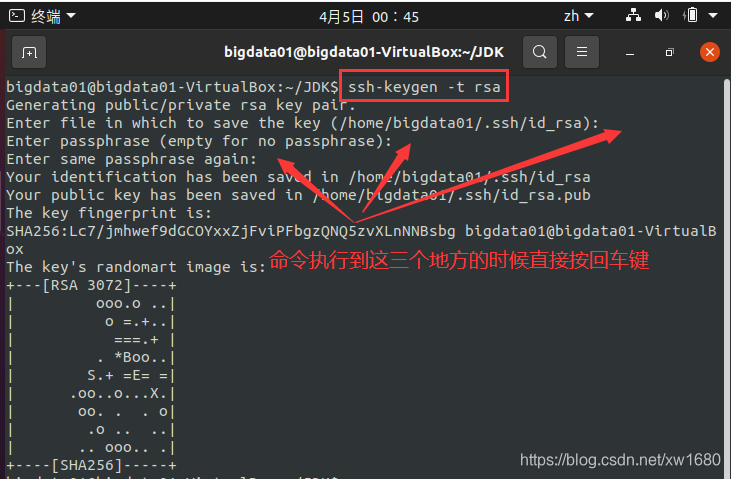
产生 SSH Key。接着在终端输入命令:ssh-keygen -t rsa。注意:注意ssh-keygen后参数的大小写,比如“-t”与“-T”表示不同意思。其中,ssh-keygen代表生成密钥;-t表示生成指定类型的密钥类型;rsa是rsa密钥认证。
此条命令运行后出现暂停时,按回车键即可。并且会产生两个密钥文件,即在 .ssh 文件夹(此文件夹在用户的根目录下,即 /home/bigdata01) 下创建 id_rsa 和 id_rsa.pub 两个文件,这是 SSH 的一对私钥和公钥,类似于钥匙和锁,下面要做的就是把 id_rsa.pub(公钥)放到许可证文件中去。
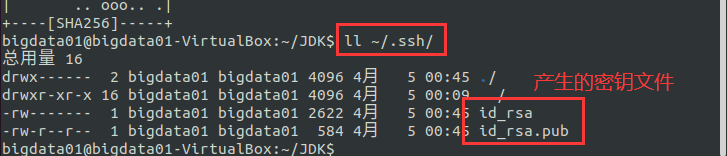
使用 ll ~/.ssh 查看产生的 SSH Key(密钥):
将 id_rsa.pub(公钥) 放到许可证文件(authorized_keys)中,命令:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
更改权限,命令如下:
chmod 755 ~
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
验证 SSH 是否安装成功,以及是否可以免密码登录本机。首先,验证SSH是否安装成功,输入命令:ssh -Version。执行结果如图所示:
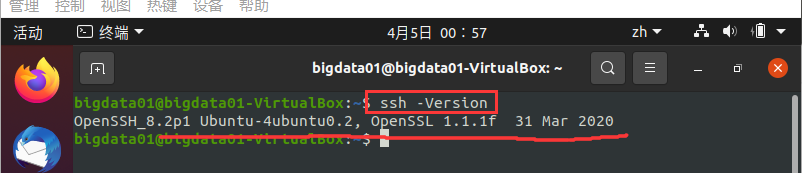
出现上图所示的执行结果,则表示 SSH 安装成功。注意:命令“ssh -Version”中的V是大写的
接下来,验证是否可以免密码登录本机,命令:ssh bigdata01-VirtualBox。执行结果如下图所示:
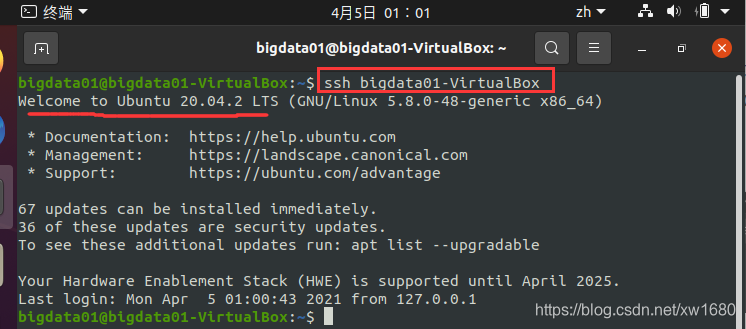
说明:bigdata01-VirtualBox 为笔者的主机名,读者可以使用 hostname 命令查看自己的主机名。如上图所示,没有要求输入登录密码,则表示 SSH 已经成功实现无密码登录了。
退出 SSH 连接,代码如下:exit。执行结果如下图所示:

说明:在 Hadoop 的安装过程中,是否无密码登录不是特别重要的,但是如果不配置无密码登录,每次启动 Hadoop 都需要输入密码来登录到每台机器的 DataNode 上,但是 Hadoop 集群动辄拥有数百或上千台机器,因此一般来说都会配置 SSH 的无密码登录。
在介绍 Hadoop 的安装之前,先介绍一下 Hadoop 对各个节点的角色定义。
Hadoop 可以分别从三个角度将主机划分为两种角色。第一,最基本的划分为 Master 和 Slave,即主人与奴隶;第二,从 HDFS 的角度,将主机划分为 NameNode 和 DataNode(在分布式文件系统中,目录的管理很重要,管理目录相当于主人,而 NameNode 就是目录管理者);第三,从 MapReduce 的角度,将主机划分为 JobTracker 和 TaskTracker(一个 Job 可以划分为多个Task)。
1、Hadoop的安装模式
Hadoop 有三种安装模式,分别为:单机模式、伪分布式和完全分布式(集群)。
其中,安装单机模式的 Hadoop 无须配置,在这种方式下,Hadoop 被认为是一个单独的 Java 进程,这种方式经常用来测试。
本篇博文主要介绍伪分布式的 Hadoop 安装,可以把伪分布式的 Hadoop 看作是只有一个节点的集群,在这个集群中,这个节点既是 Master,也是 Slave;既是 NameNode,也是 DataNode;既是 JobTracker,也是 TaskTracker。关于完全分布式的 Hadoop 下篇博文再进行介绍。
2、Hadoop 的下载
本篇博文中使用的 Hadoop 的安装版本为 Hadoop 3.2.0,下载 Hadoop 的网址为:https://hadoop.apache.org/releases.html,如下图所示:
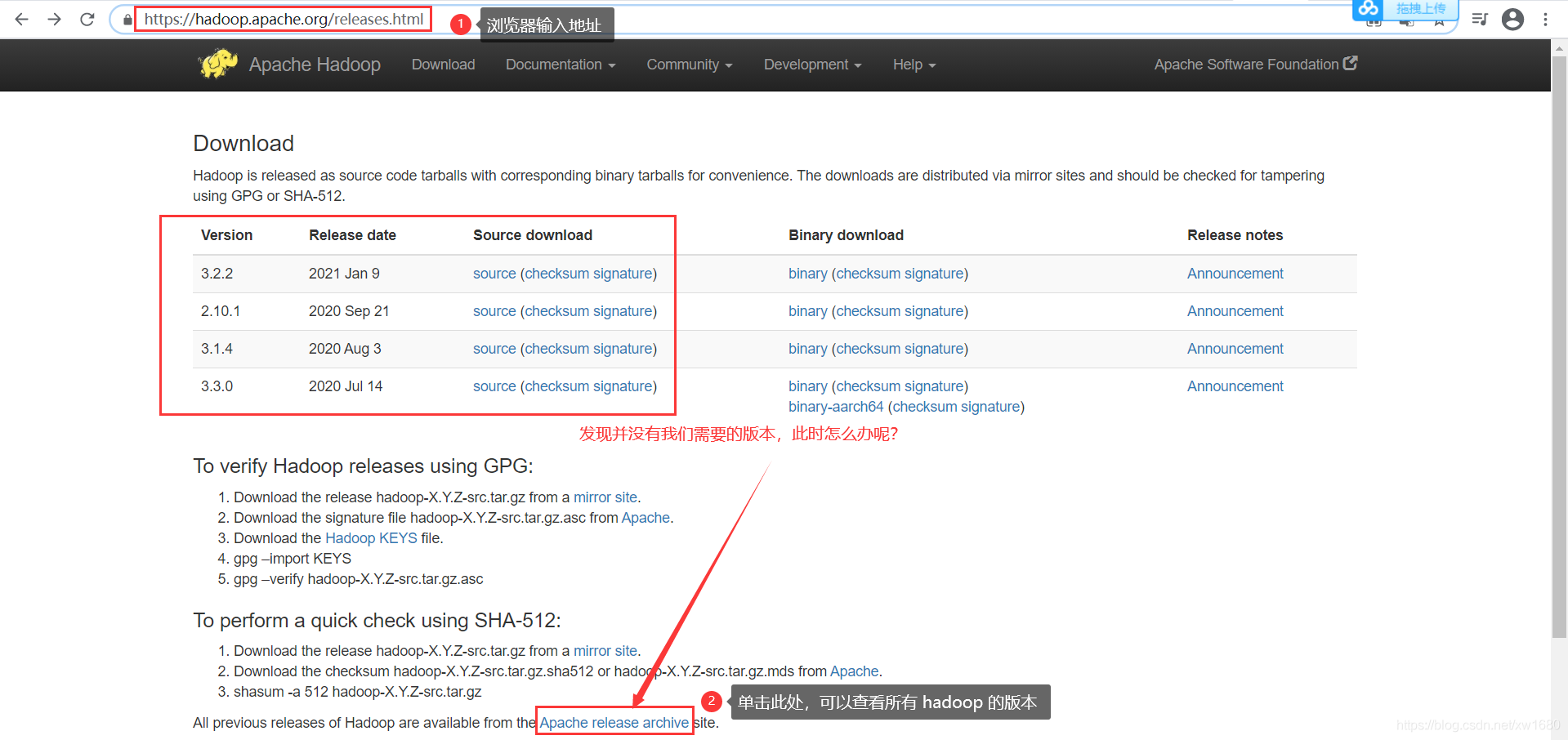
单击后,进入一个新的页面,向下拉动浏览器的滚动条,找到我们需要的 hadoop 版本,如下图所示:
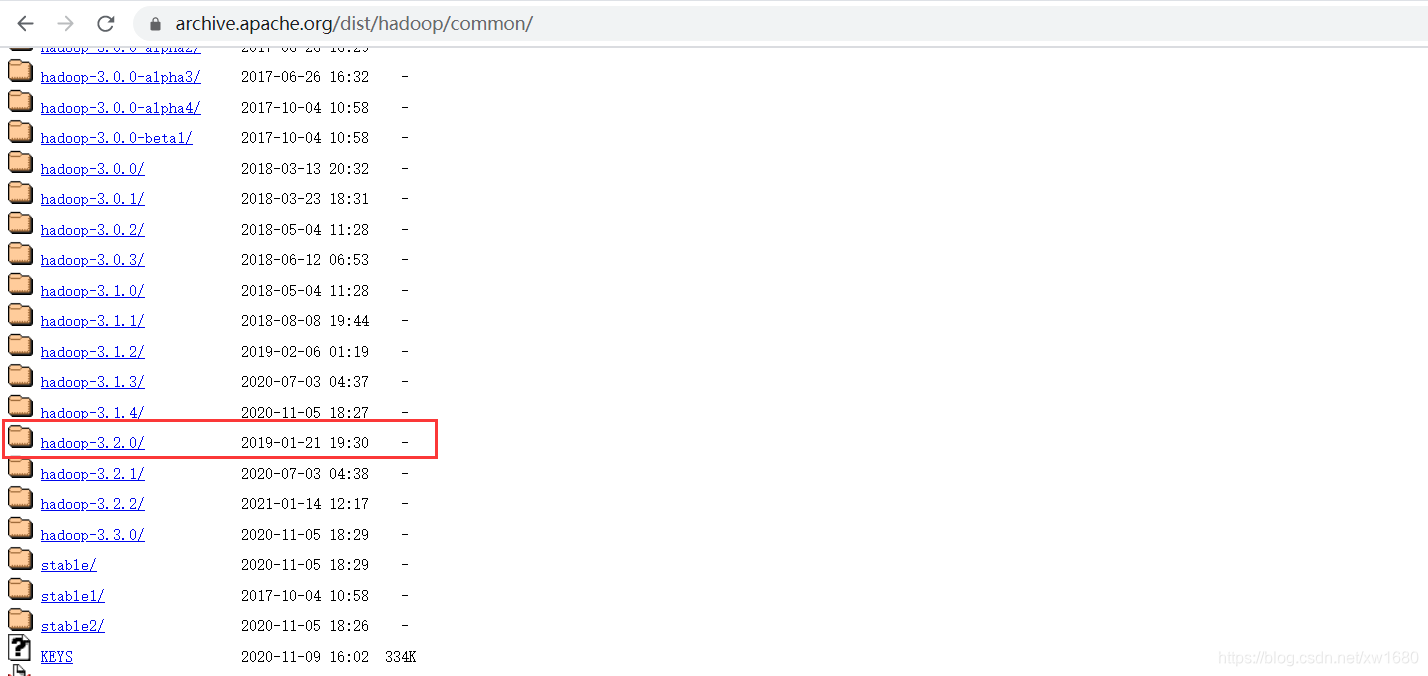
找到我们需要的 hadoop 版本之后,鼠标左键点击,进入到新的界面,然后选择 hadoop-3.2.0.tar.gz 进行下载,如下图所示:
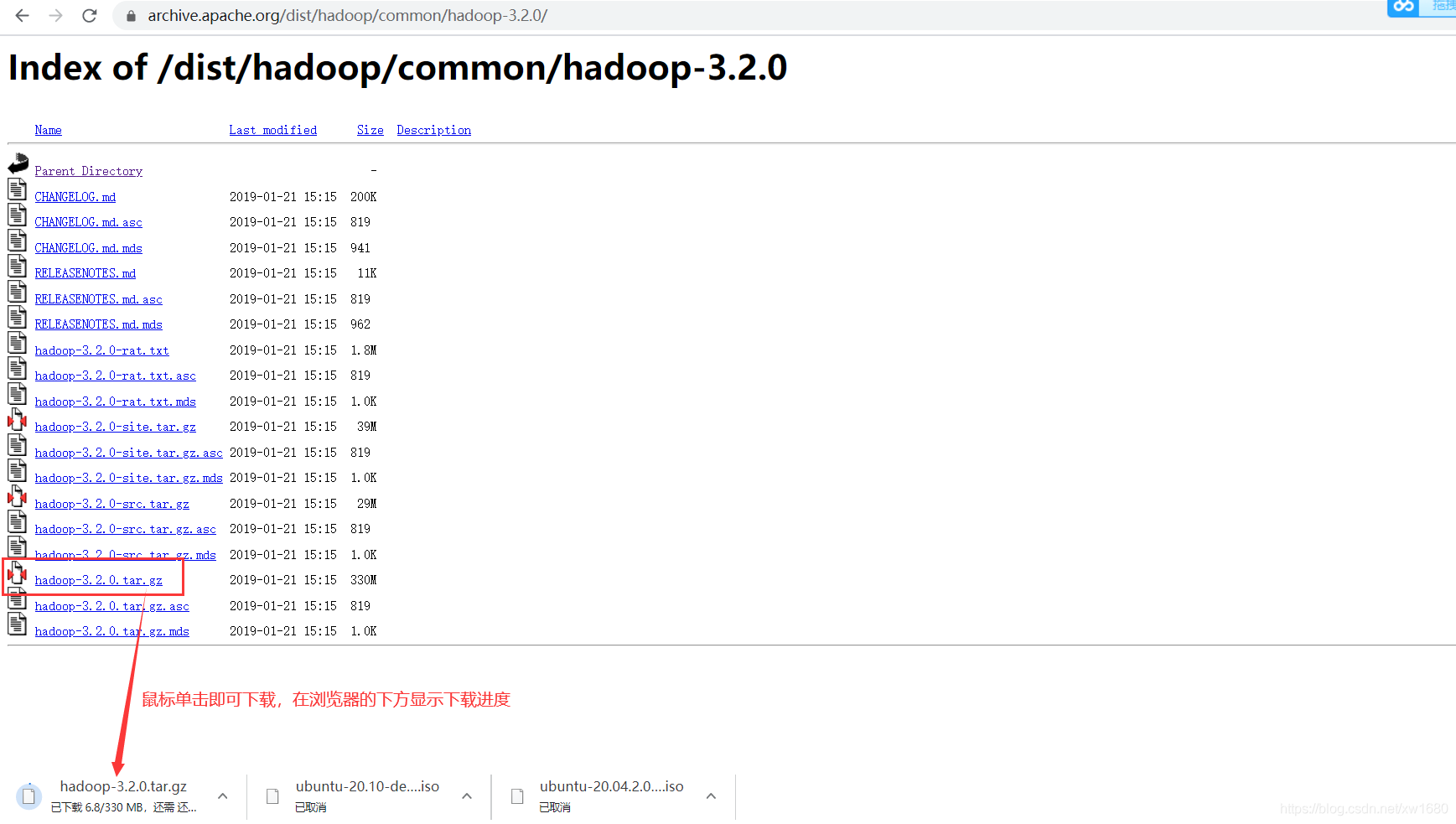
注意:如果发现这个国外的地址下载比较慢,可以使用国内的镜像地址下载,但是这些国内的镜像地址中提供的安装包版本可能不全,如果没有找到我们需要的版本,那还是要老老实实到官网下载。
这些国内的镜像地址里面不仅仅有 Hadoop 的安装包,里面包含了大部分 Apache 组织中的软件安装包:
地址1:https://mirrors.tuna.tsinghua.edu.cn/apache/
将下载好的安装包 hadoop-3.2.0.tar.gz 复制到共享文件夹中,以便 Ubuntu 系统可以对此安装包进行下一步的操作。
3、Hadoop 的安装
Hadoop 的安装步骤如下:
解压缩 Hadoop 安装包。将安装包从共享文件夹复制到主目录下,打开终端,输入如下命令,将 Hadoop 安装包解压缩到当前目录下。命令:tar -zxvf hadoop-3.2.0.tar.gz
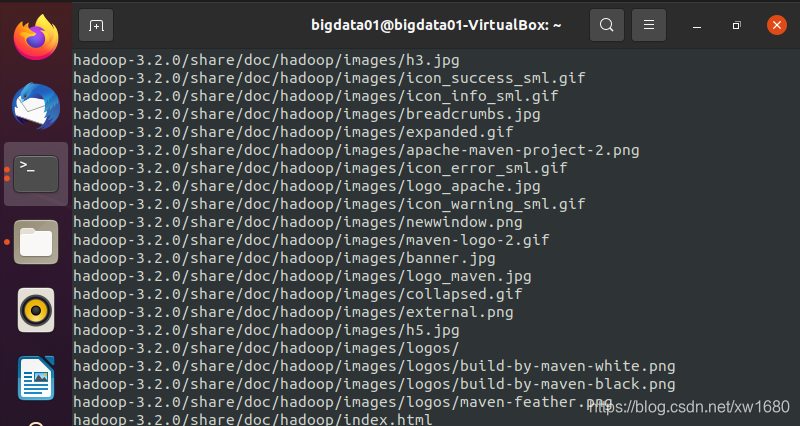
命令执行后,系统开始解压缩 hadoop-3.2.0.tar.gz 文件,屏幕上不断显示解压过程信息,如上图所示(由于篇幅问题,只显示部分解压信息),当解压完成后,系统将在主目录下创建 hadoop-3.2.0 子目录,此为 Hadoop 的安装目录。
查看一下 Hadoop 安装目录中的安装文件,输入命令:
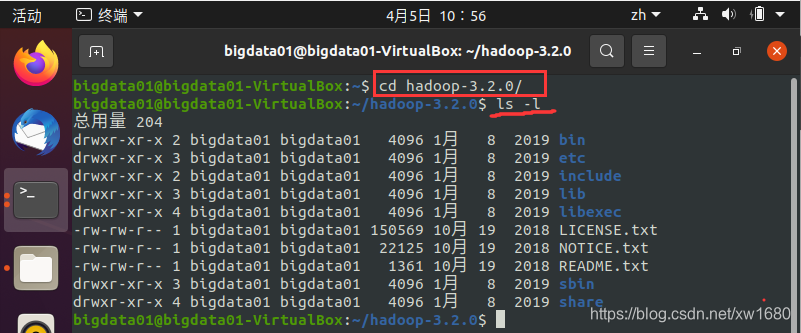
安装文件的目录及目录下常用文件说明如下表所示:


至此,Hadoop 安装完毕,但是要使用 Hadoop,还需要进行一系列的配置。
1、配置 IP 和主机名
下面分别通过命令查看本机的 IP 地址和主机名,并将 IP 地址和主机名写进 /etc/hosts 配置文件中,步骤如下:
(1) 查看本机的 IP 地址,命令如下:
sudo apt install net-tools
ifconfig
或者直接使用
ip addr
执行结果如下图所示:
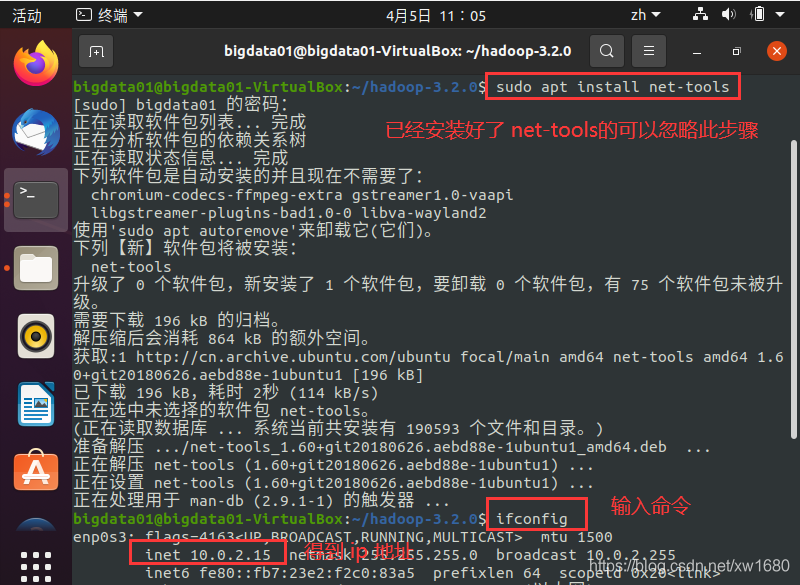
从上图中可知本机的 IP 地址为 10.0.2.15。说明:此 IP 地址为虚拟机自动分配的地址,可以自己另行设置。
(2) 查看本机的主机名,命令如下:
hostname
执行结果如下图所示:
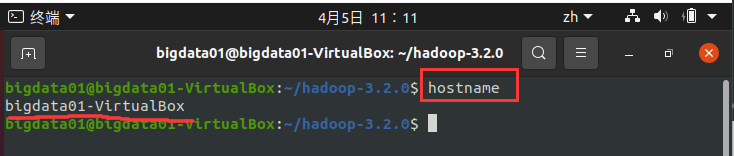
从上图中可知本机的主机名为 bigdata01-VirtualBox。
(3) 将 IP 地址和主机名写进 /etc/hosts 配置文件中,打开 /etc/hosts 命令如下:
sudo gedit /etc/hosts
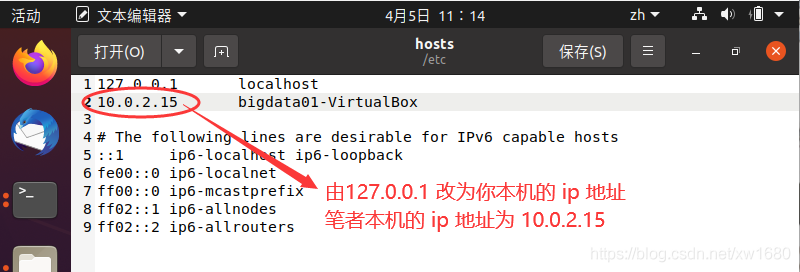
修改完成后,单击保存按钮,关闭文件。
2、设置 Hadoop 环境变量
运行 Hadoop 必须设置很多环境变量,可是如果每次登录时都必须重新设置就会很烦琐,因此,可以在 ~/.bashre 文件中设置每次登录时都会自动运行一次环境变量设置,设置步骤如下:
(1) 在终端输入如下命令:
sudo gedit ~/.bashrc
执行命令之后,就会打开 ~/.bashrc 文件,在原有代码的最下方的位置添加如下代码:
# 设置JDK安装路径。
export JAVA_HOME=/home/bigdata01/JDK/jdk1.8
# 设置Hadoop的安装目录。
export HADOOP_HOME=/home/bigdata01/hadoop-3.2.0
# 设置PATH
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 设置Hadoop其他环境变量 将这些环境变量设置为$HADOOP_HOME。
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
# 链接库的设置
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
编辑好 ~/.bashrc 文件后,单击 保存 按钮后,再关闭 gedit,如下图所示:
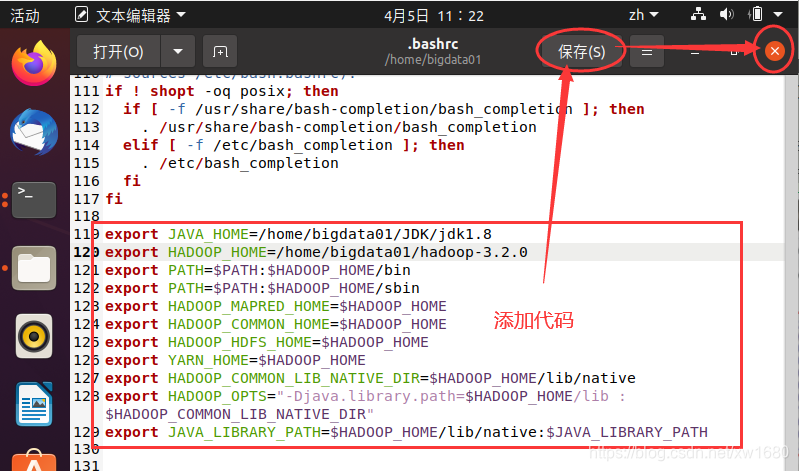
(2) 使设置生效。在终端输入命令:source ~/.bashrc。或者重启系统,也会使得设置生效。
(3) 使用 hadoop version 命令测试是否配置成功,执行结果如下图所示:
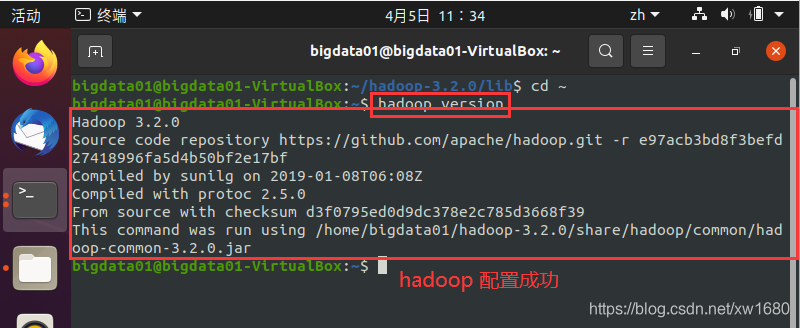
出现上图所示的结果,则说明 Hadoop 环境已经配置成功了。
3、修改 Hadoop 配置文件
接下来要进行 Hadoop 的配置设置,需要修改的配置文件有:Hadoop-env.sh、core-site.xml、yarn-site.xml、mapred-site.xml 和 hdfs-site.xml,最后还要修改一下 /etc/profile 文件。
(1) 修改 Hadoop-env.sh 文件。Hadoop-env.sh 是 Hadoop 的配置文件,在此文件中需要设置 Java 的安装路径。首先通过终端打开 Hadoop-env.sh 文件,代码如下:
sudo gedit ./hadoop-3.2.0/etc/hadoop/hadoop-env.sh
Hadoop-env.sh 文件打开后,找到 # export JAVA_HOME 处(可以使用快捷键 <CTRL+F> 查找),在等号后面添加 JDK 的安装位置,并将 export 前面的 # 号删掉,如下图所示:
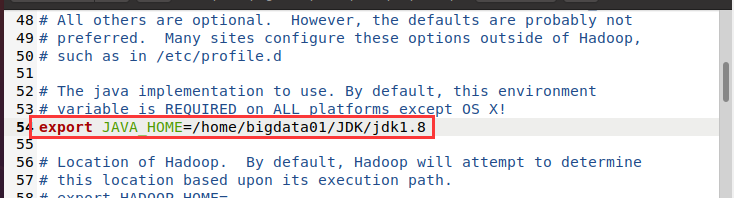
修改完毕后,单击 保存 按钮,关闭 Hadoop-env.sh 文件。
(2) 修改 core-site.xml 文件,通过终端打开 core-site.xml 文件,代码如下:
sudo gedit ./hadoop-3.2.0/etc/hadoop/core-site.xml
core-site.xml 文件打开后,需要设置 HDFS 的默认名称、地址和端口号,将如下代码添加到 <configuration> 和 </configuration> 之间
<!-- 配置HDFS的主节点,NameNode -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.0.2.15:9000</value>
</property>
<!-- 配置HADOOP运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/bigdata01/hadoop-3.2.0/dataNode_1_dir</value>
</property>
如下图所示:
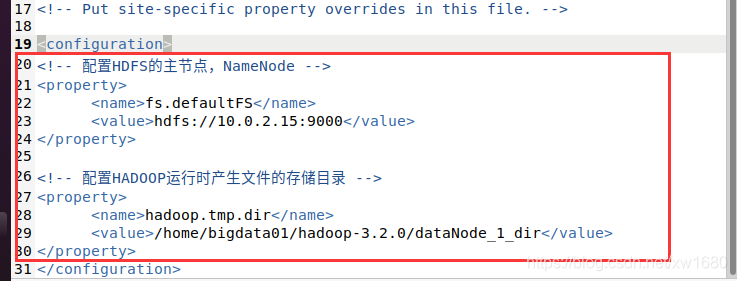
说明:代码中的 10.0.2.15 为笔者的虚拟机的 IP 地址,读者可以通过 ifconfig 命令查看本机的 IP 地址。XML文件中,<!--、--> 中间的内容为注释。修改完毕后,单击 保存 按钮,关闭 core-site.xml 文件。
(3) 修改 yarn-site.xml 文件。YARN 的站点配置文件是 yarn-site.xml,通过终端打开 yarn-site.xml 文件的代码如下:
sudo gedit ./hadoop-3.2.0/etc/hadoop/yarn-site.xml
YARN-site.xml 文件打开后,将如下代码添加到 <configuration> 和</configuration> 之间,代码如下:
<!--配置ReourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>10.0.2.15</value>
</property>
<!--配置NodeManager执行任务的方式:shuffle:洗牌 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
修改完毕后,单击 保存 按钮,关闭 YARN-site.xml 文件。如果 YARN 集群有多个节点,还需要配置 yarn.resourcemanager.address 等参数。
(4) 修改 mapred-site.xml 文件。mapred-site.xml 为计算框架文件,用于设置监控 Map 与 Reduce 程序的 JobTracker 任务分配情况以及 TaskTracker 任务运行情况。打开 mapred-site.xml 文件,命令如下:
sudo gedit ./hadoop-3.2.0/etc/hadoop/mapred-site.xml
mapred-site.xml 文件打开后,将如下代码添加到 <configuration> 和</configuration> 之间,设置 mapreduce 的框架为 yarn。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
修改完毕后,单击 保存 按钮,关闭 mapred-site.xml 文件。
(5) 修改 hdfs-site.xml 文件。hdfs-site.xml 用于设置 HDFS 分布式文件系统。该文件指定与 HDFS 相关的配置信息。需要修改 HDFS 默认的块的副本属性,因为 HDFS 默认情况下每个数据块保存 3 个副本,而在伪分布式模式下运行时,由于只有一个数据节点,所以需要将副本个数改为1;否则 Hadoop 程序会报错。打开 hdfs-site.xml 文件,命令如下:
sudo gedit ./hadoop-3.2.0/etc/hadoop/hdfs-site.xml
同样,hdfs-site.xml 文件打开后,将如下代码添加到 <configuration> 和 </configuration> 之间。
<!-- 指定DataNode存储block的副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定namenode数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/bigdata01/hadoop-3.2.0/hadoop_data/hdfs/namenode</value>
</property>
<!-- 指定datanode数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/bigdata01/hadoop-3.2.0/hadoop_data/hdfs/datanode</value>
</property>
<!-- 指定ip地址 -->
<property>
<name>dfs.http.address</name>
<value>10.0.2.15:50070</value>
</property>
修改完毕后,单击 保存 按钮,关闭 hdfs-site.xml 文件。注意:将dfs.replication配置成超过3的数是没有意义的,因为HDFS的最大副本数就是3。
(6) 修改 /etc/profile 文件。
sudo gedit /etc/profile
export HADOOP_HOME=./hadoop-3.2.0
:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
如下图所示:

4、创建并格式化文件系统
在上面的小节,hdfs-site.xml 文件中,指定了 NameNode 和 DataNode 的数据存储目录,但是这两个目录并没有创建,在本小节中,创建 NameNode 和 DataNode 的数据存储目录,并进行格式化。创建 NameNode 和 DataNode 的数据存储目录,命令如下:
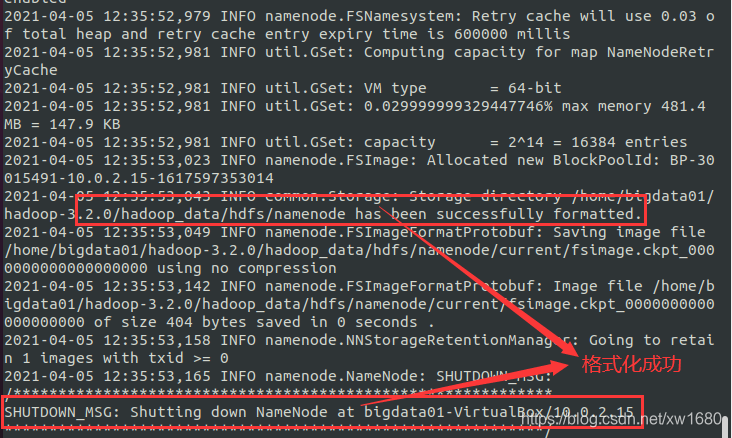
通过前面的小节,已经完成了 Hadoop 伪分布式单节点的安装,现在开始启动 Hadoop。使用命令 start-all.sh,来同时启动 HDFS 和 YARN,执行结果如下图所示:
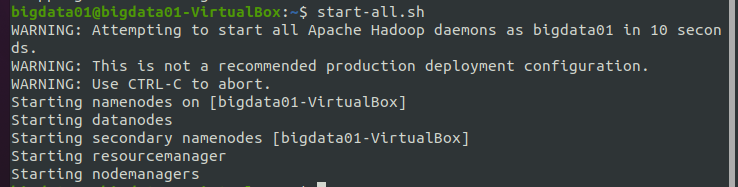
说明:start-all.sh命令可以拆分为start-dfs.sh和start-yarn.sh,分别用来启动HDFS和YARN。在启动Hadoop时,用这两种方式都可以。
下面通过 jps 命令检验一下是否全部开启 Hadoop 的守护进程,执行结果如图所示:
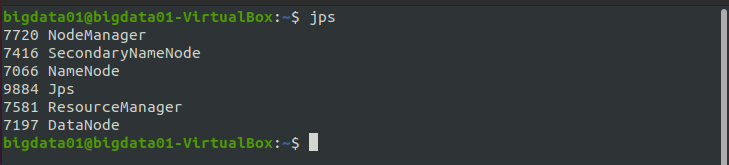
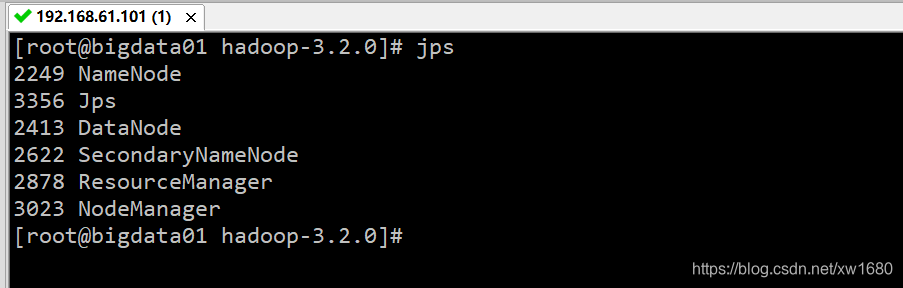
在上图的结果图中,DataNode、SecondaryNameNode 和 NameNode 是文件系统 HDFS 的进程,NodeManager、ResourceManager 是 YARN 的进程。只有这 5 个进程全部启动,才说明 Hadoop 启动成功了。
关闭 Hadoop 的命令:stop-all.sh,执行结果如下图所示:
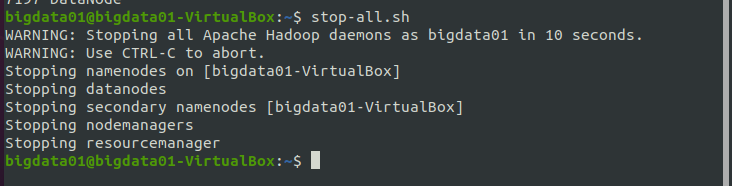
说明:stop-all.sh命令可以拆分为stop-dfs.sh和stop-yarn.sh,分别用来关闭HDFS和YARN。在关闭Hadoop时,使用“stop-all.sh”或者“stop-dfs.sh”+“stop-yarn.sh”这两种方式都可以。
HDFS Web 界面可以检查当前 HDFS 与 DataNode 的运行情况,打开步骤如下。打开浏览器 Firefox,在浏览器的地址栏中输入:10.0.2.15:50070,向下滑动页面,可以看到活动节点,如下图所示:
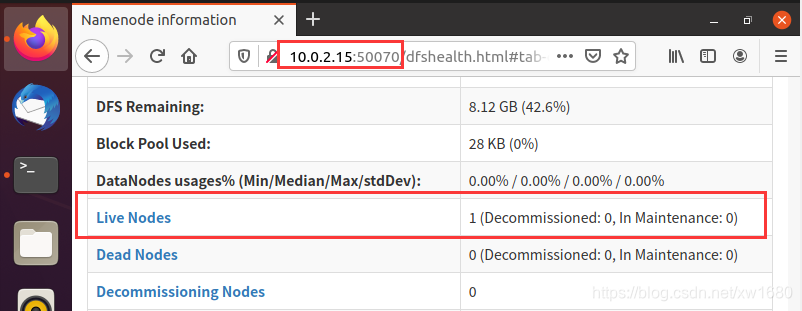
说明:10.0.2.15 为笔者虚拟机中的 IP 地址,读者应根据实际情况进行替换。
YARN Web 界面也被称为 Hadoop ResourceManager Web 界面,在此页面中,可以查看当前 Hadoop 的状态;Node 节点;应用程序、进程的运行状态。打开 YARN 的 Web 界面的步骤如下。
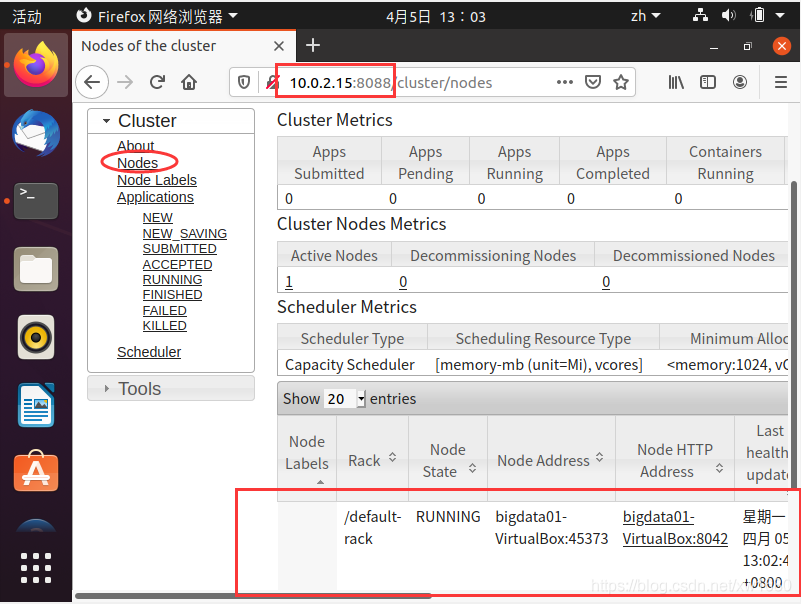
打开浏览器 Firefox,在浏览器的地址栏中输入:10.0.2.15:8088,单击 Nodes 链接,显示当前已经运行的节点。因为本篇博文中安装的是伪分布式的 Hadoop,所以会看到当前只有一个节点,如下图所示:
设置静态 ip:vi /etc/sysconfig/network-scripts/ifcfg-ens33(不同系统 ens 后的数字不一样,读者需根据自己本机实际情况)
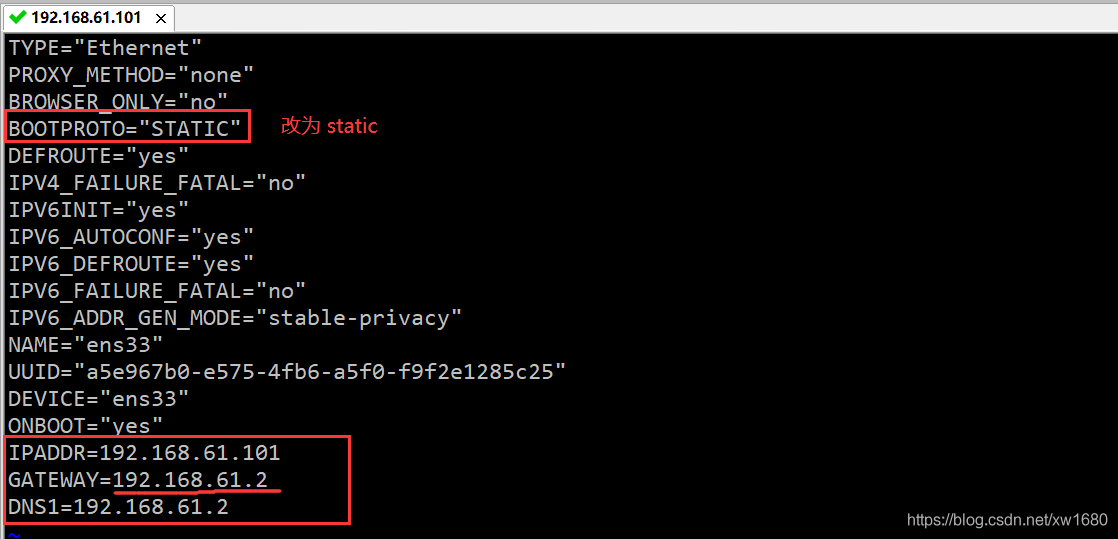
注意:IPADDR 的值,192.168.61 都是取自虚拟机中虚拟网络编辑器中子网地址的值,最后的 101 是我自己取的,这个值可以取 3~254 之间的任意一个数值,建议大家也按照我这个取值为 101,这样方便统一,后期和我在博客中使用的都是一样的。GATEWAY 的值是取自虚拟网络编辑器中 NAT 设置里面的网关的值,DNS1 的值和 GATEWAY 的值一样即可。
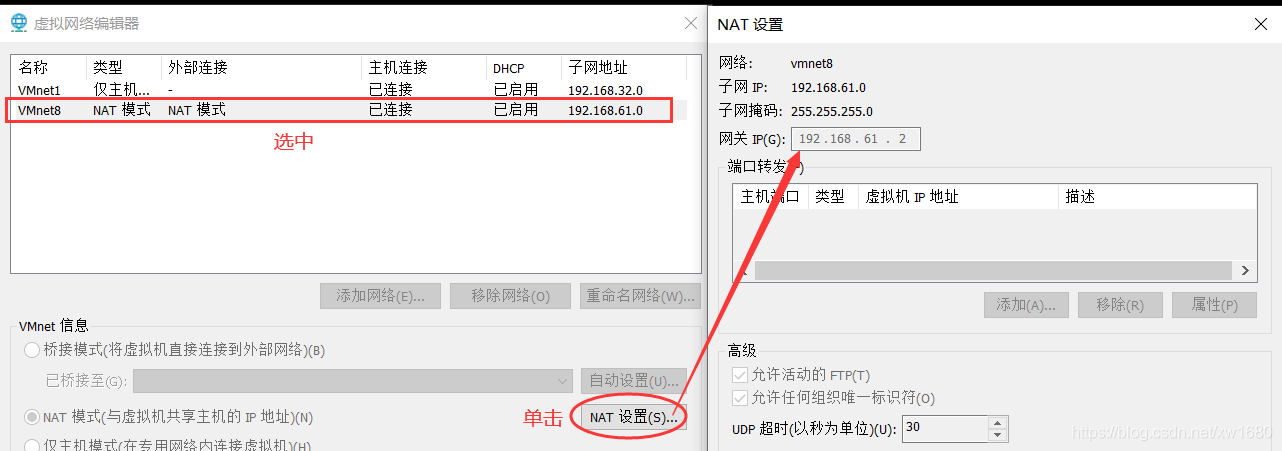
最后:service network restart,如下图所示:

hostname:设置临时主机名和永久主机名。临时:hostname bigdata01、永久:vi /etc/hostname 将里面的主机名改为 bigdata01。紧接着重启查看:reboot -h now、hostname。

firewalld:临时关闭防火墙+永久关闭防火墙。临时:systemctl stop firewalld、永久:systemctl disable firewalld、确认是否从开机启动项中关闭了:systemctl list-unit-files | grep firewalld
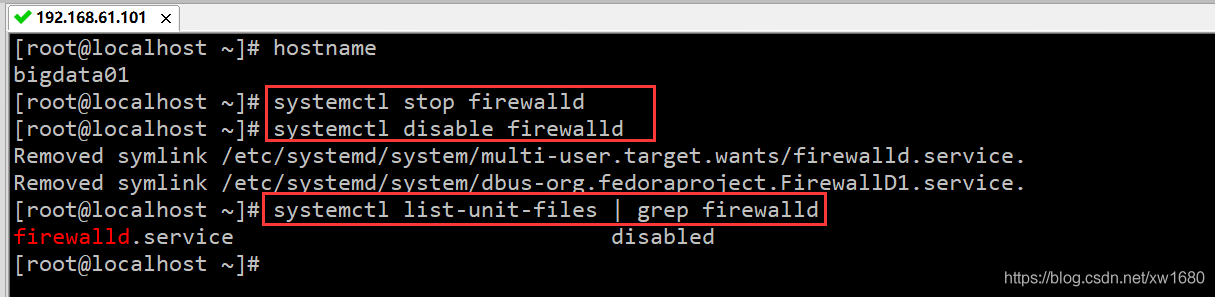
注意:针对不同版本的 centos 系统,关闭防火墙的命令是不一样的,目前的两大主流版本是 centos6 和 centos7,他们两个关闭防火墙的命令也是不一样的。刚刚博主演示的是 centos7 中防火墙关闭的命令,如果你遇到了 centos6,也想关闭防火墙的话可以自己百度一下命令,后续博主也会在 Linux 从菜鸟到精通专栏 中继续更新 Centos6 的相关操作。
ssh 免密码登录。在上面 Ubuntu 中详细介绍过,这里博主就不再赘述。
1、ssh-keygen -t rsa、注意:执行这个命令以后,在 Centos 需要连续按 4 次回车键回到 linux 命令行才表示这个操作执行结束,在按回车的时候不需要输入任何内容。
2、把公钥拷贝到需要免密码登录的机器上面:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
安装 JDK。先:mkdir -p /data/soft、把 JDK 的安装包上传到 /data/soft/ 目录下
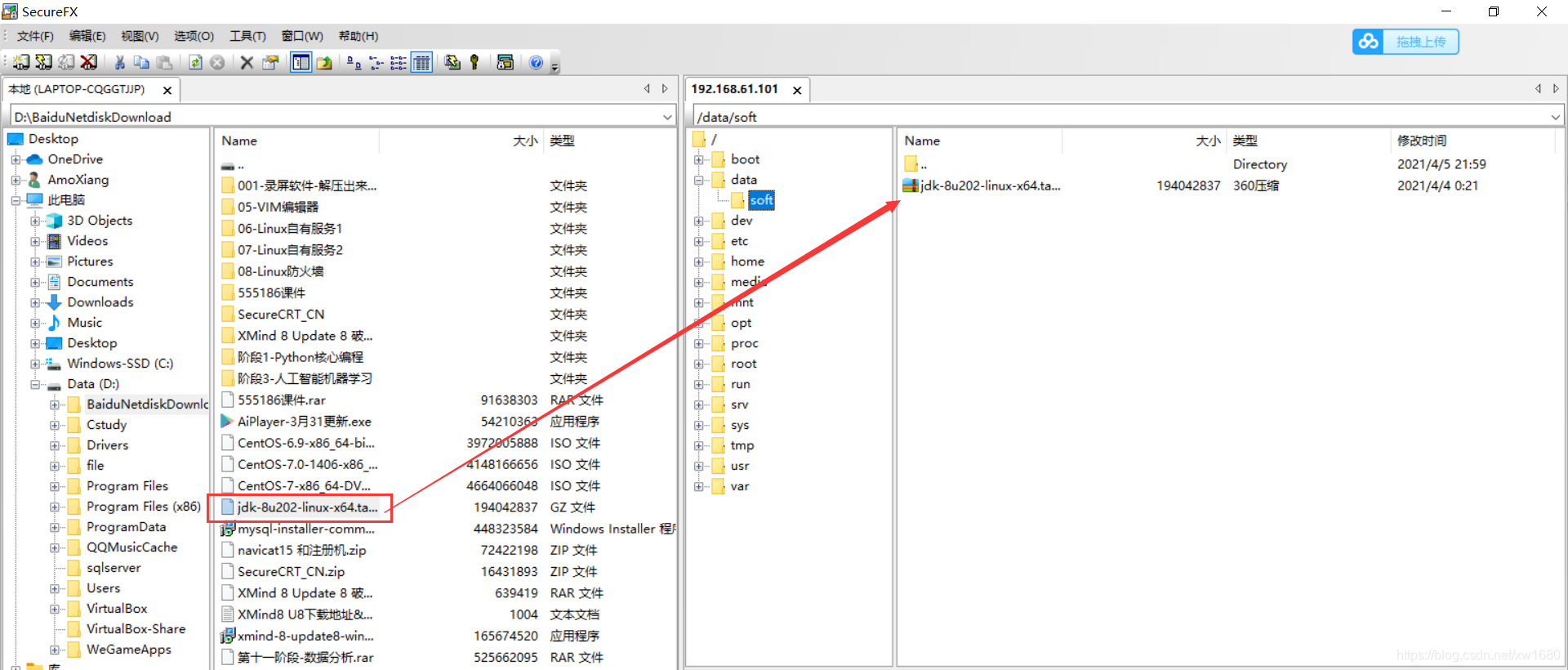
解压 jdk 安装包:tar -zxvf jdk-8u202-linux-x64.tar.gz
重命名 jdk:mv jdk1.8.0_202/ jdk1.8
配置环境变量 JAVA_HOME:vi /etc/profile

立即生效:source /etc/profile
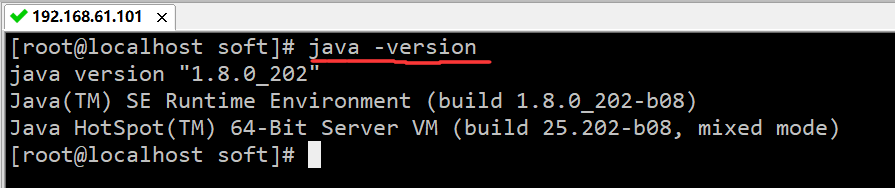
验证:java -version
把 hadoop 的安装包上传到 /data/soft 目录下,解压 hadoop 安装包:tar -zxvf hadoop-3.2.0.tar.gz
配置一下环境变量 vi /etc/profile

修改 Hadoop 相关配置文件。进入配置文件所在目录:cd etc/hadoop/
先修改 hadoop-env.sh,执行命令:vi hadoop-env.sh,如下图所示:

修改 core-site.xml 文件,注意 fs.defaultFS 属性中的主机名需要和你配置的主机名保持一致,执行 vi core-site.xml 命令,添加内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
修改 hdfs-site.xml 文件,把 hdfs 中文件副本的数量设置为1,因为现在伪分布集群只有一个节点。首先:vi hdfs-site.xml,添加内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
修改 mapred-site.xml,设置 mapreduce 使用的资源调度框架。首先:vi mapred-site.xml,添加内容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改 yarn-site.xml,设置 yarn 上支持运行的服务和环境变量白名单。首先:vi yarn-site.xml,添加内容如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
修改 workers,设置集群中从节点的主机名信息,在这里就一台集群,所以就填写 bigdata01 即可,首先:vi workers,然后将里面的 localhost 改为 bigdata01。
格式化 HDFS。cd /data/soft/hadoop-3.2.0、bin/hdfs namenode -format,如下图所示:
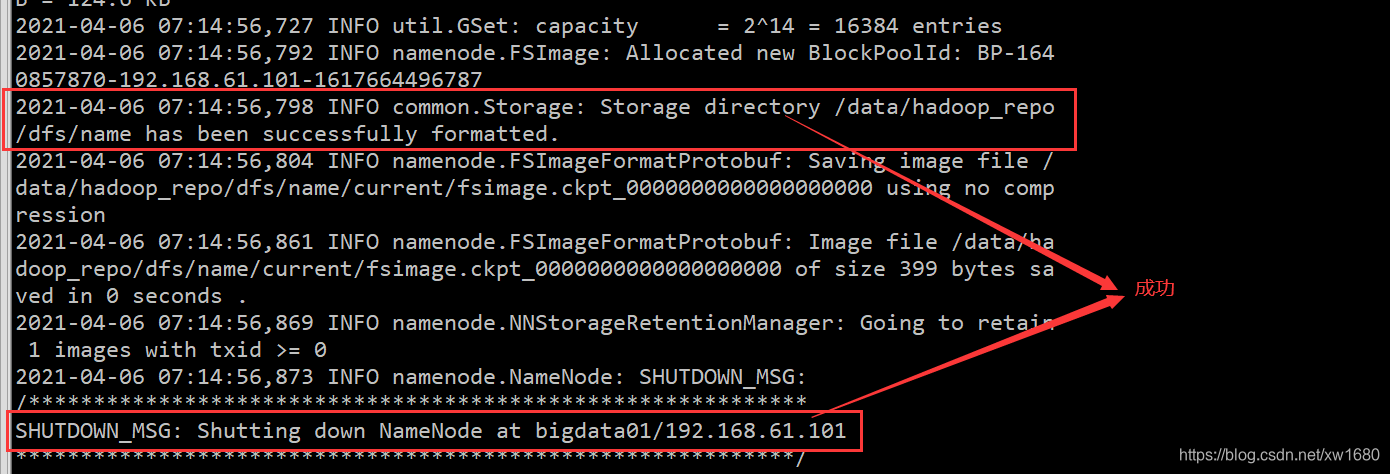
如果提示错误,一般都是因为配置文件的问题,当然需要根据具体的报错信息去分析问题。注意:格式化操作只能执行一次,如果格式化的时候失败了,可以修改配置文件后再执行格式化,如果格式化成功了就不能再重复执行了,否则集群就会出现问题。如果确实需要重复执行,那么需要把 /data/hadoop_repo 目录中的内容全部删除,再执行格式化。
启动伪分布集群,使用 sbin 目录下的 start-all.sh 脚本。
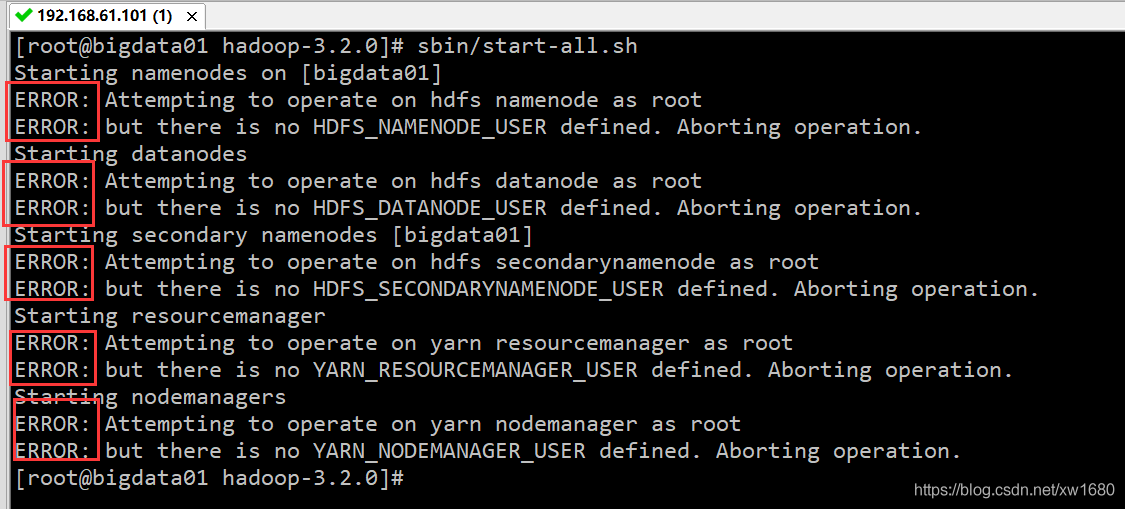
执行的时候发现有很多 ERROR 信息,提示缺少 HDFS 和 YARN 的一些用户信息。解决方案如下:修改 sbin 目录下的 start-dfs.sh,stop-dfs.sh 这两个脚本文件,在文件前面增加如下内容:cd sbin/
vi start-dfs.sh,增加以下内容:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vi stop-dfs.sh,增加以下内容:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改 sbin 目录下的 start-yarn.sh,stop-yarn.sh 这两个脚本文件,在文件前面增加如下内容。vi start-yarn.sh,增加以下内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
vi stop-yarn.sh,增加以下内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
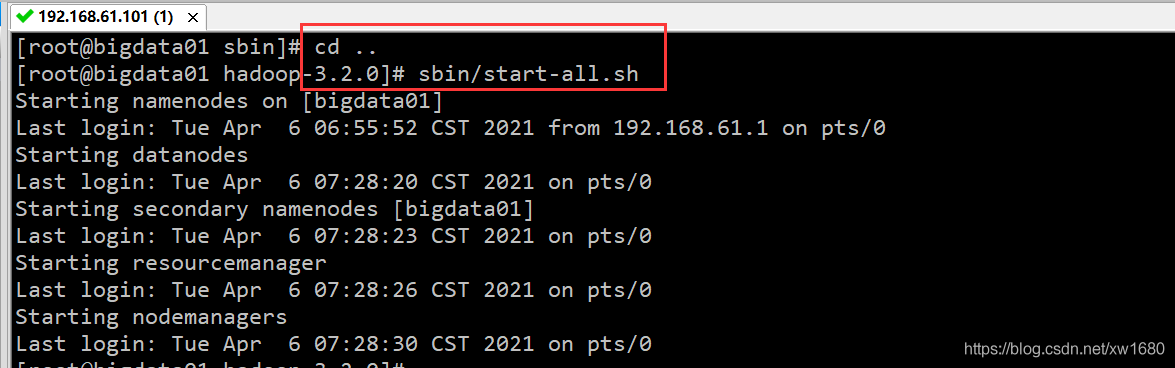
再启动集群:
验证集群进程信息。执行 jps 命令可以查看集群的进程信息,去掉 jps 这个进程之外还需要有 5 个进程才说明集群是正常启动的。
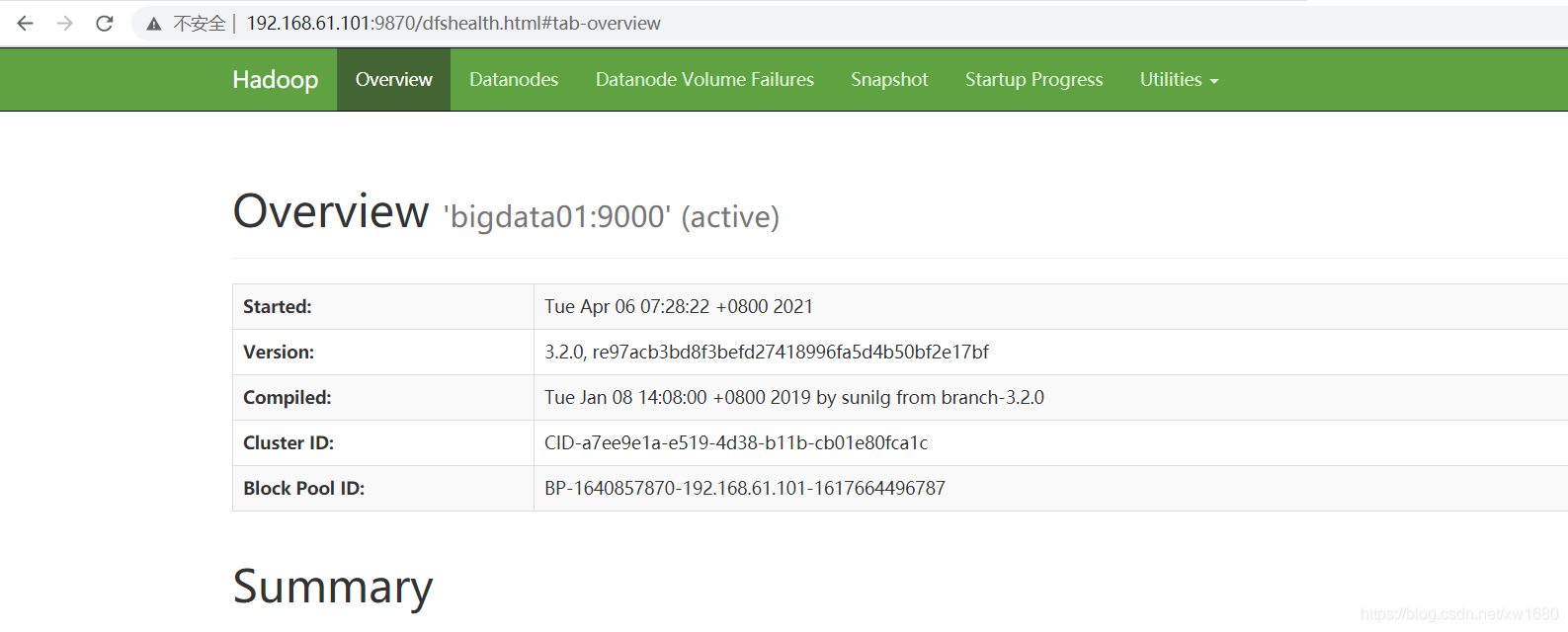
还可以通过 webui 界面来验证集群服务是否正常。HDFS webui 界面:http://192.168.61.101:9870
YARN webui 界面:http://192.168.61.101:8088
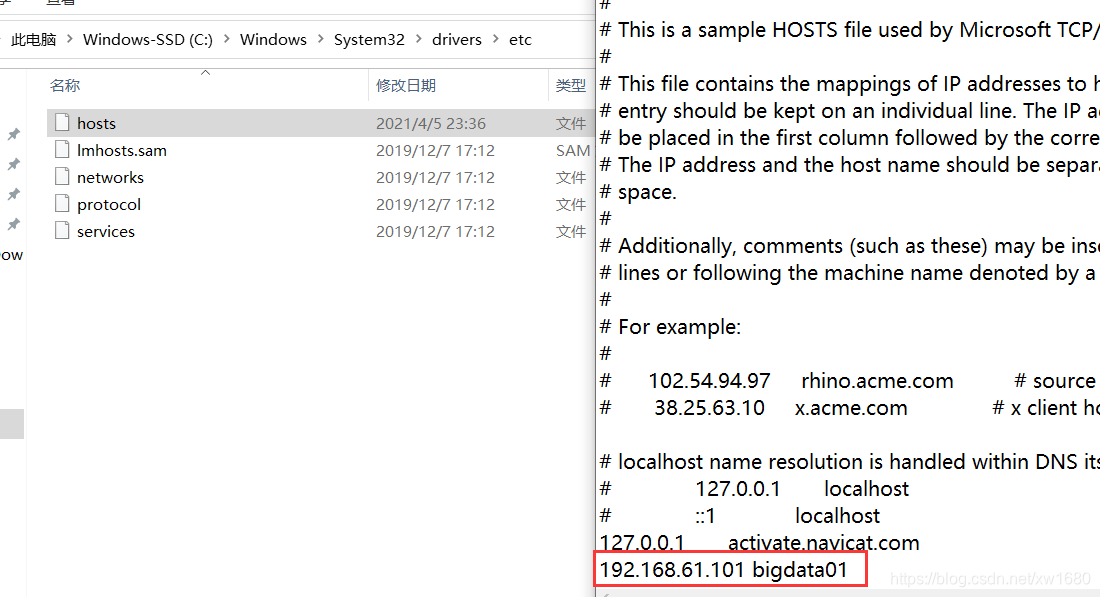
如果想通过主机名访问,则需要修改 Windows 机器中的 hosts 文件。文件所在位置为:C:\Windows\System32\drivers\etc\HOSTS。在文件中增加下面内容,这个其实就是 Linux 虚拟机的 ip 和主机名,在这里做一个映射之后,就可以在 Windows 机器中通过主机名访问这个 Linux 虚拟机了。
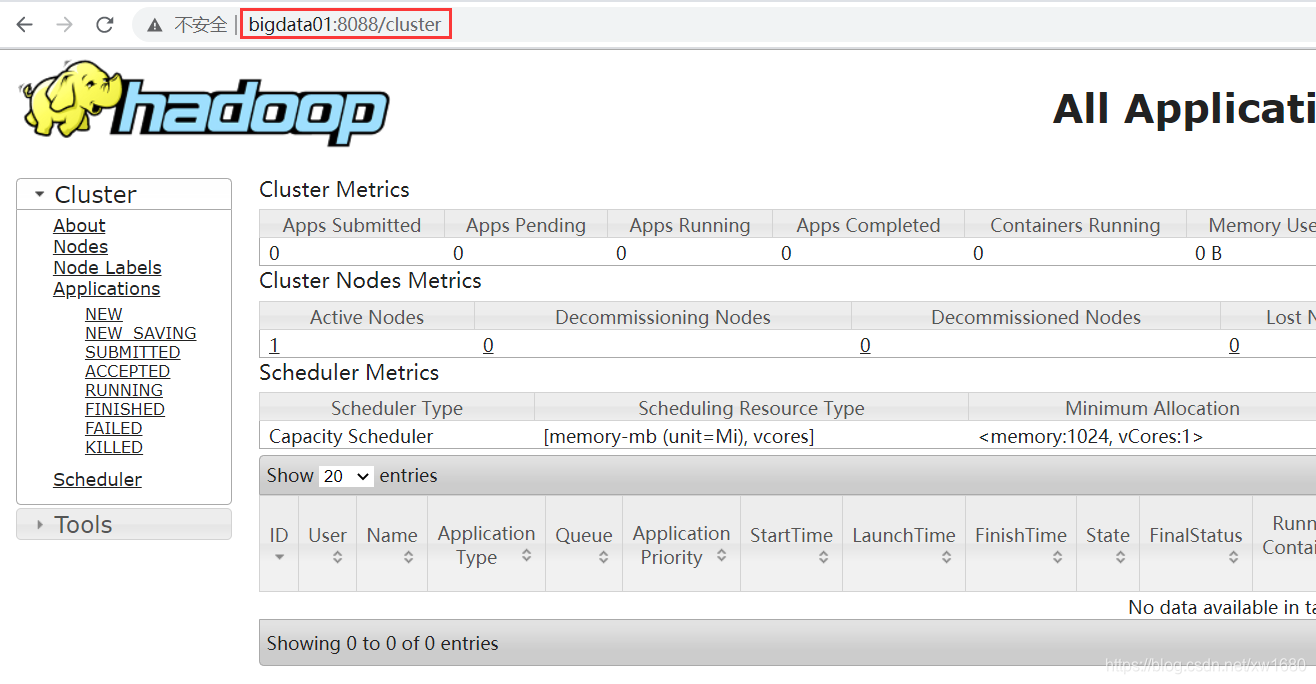
使用 http://bigdata01:8088/cluster YARN webui 界面,如下图所示:
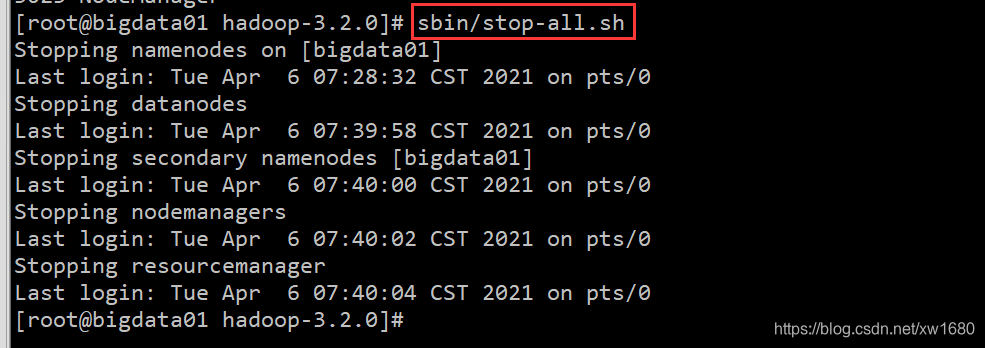
停止集群。如果修改了集群的配置文件或者是其它原因要停止集群,可以使用命令:sbin/stop-all.sh。

Spring3.0配置多个事务管理器(即操作多个数据源)的方法 大多数项目只需要一个...
上篇文章中,通过创建了一个带有构造函数的最简单的C++类 —— HelloWorldPlugin...
JSP开发之生成图片验证码技术的详解 我们在网页注册用户时,常常会需要格根据图...
本文转载自微信公众号「Java极客技术」,作者鸭血粉丝 。转载本文请联系 Java极...
以前只会/ abc(!def).+/.exec("abcdef\nabczzz"), 匹配到 abczzz, 这种简单的...
判断目标字符串中是否 可能 含这个字符。 假如待匹配字符串包含指定字符串并且匹...
原理 Linux内核发送崩溃时,kdump会生成一个内核转储文件vmcore。 可以通过分析v...
SpringMVC下获取验证码实例详解 前言: 1.用户一开始登录的时候, 不建议出现验证...
在设计 API 时,出于安全性等因素考虑,有时需要放弃使用自增 ID,使 ID 非连续...
前言 如果想让自己的Webshell留的更久一些,除了Webshell要免杀,还需要注意一些...

