

决策树(Decision Tree)是根据一系列规则对数据进行分类的过程。实际上决策树的生成过程就是使用满足划分准则的特征不断的将数据集划分为纯度更高,不确定性更小的子集的过程。对于当前数据集的每一次的划分,都希望根据某特征划分之后的各个子集的纯度更高,不确定性更小。在学习之前先了解几个概念。
信息量:
香农被称为“信息论之父”,他认为“信息就是用来消除不确定的性的东西”,也就是信息量越大,不确定性就越小,信息量的大小与事件发生的概率成反比。
信息量的公式为:l(x)= -log2P(x) ,其中P(x)为事件发生的概率。
熵
熵也叫香农熵,指的是所有可能发生事件所带来的信息量的期望。也可以理解为熵描述的是信息的无序程度,信息越无序,熵越大。
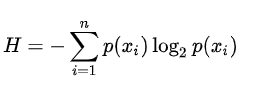
P(xi)表示Xi事件发生的概率,n为X中所有类别的个数。
信息增益
信息增益实际上就指的是数据集被划分前后熵的差值,在决策数据中使用信息增益来决定使用哪个数据特征值作为节点进行分割,在决策树构建的过程中我们总是希望当前集合往最快到达纯度更高的子集合方向发展,因此我们总是选择使得信息增益最大的特征来划分当前数据集。
信息增益 = 熵(前) - 熵(后)

基于ID3算法的决策树实现
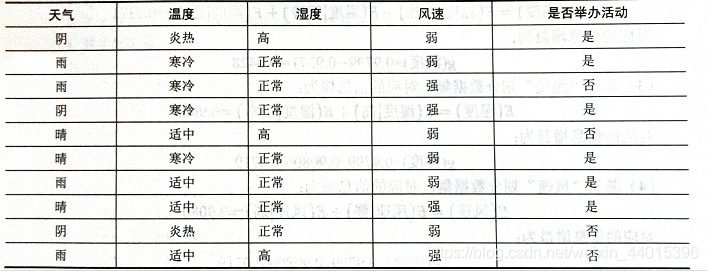
表中共有四个属性:天气、温度、湿度、风速。2个类别标签,典型的二分类问题。
10个样本中,“是”的标签有6个,“否”的标签有4个,
1.计算当前熵E = - 6/10 * log2(6/10) + -4/10 * log2(4/10)
根据熵的计算公式,对每个属性分别计算其对应的信息熵。
2.以“天气”为例,该属性共有3中取值。
“晴”出现3次,其中“是”标签有2个,“否”标签有1个,则天气为晴是对应的信息熵为:
E(天气|晴)=3/10 * [- 2/3 * log2(2/3) + -1/3 * log2(1/3)]
E(天气|阴)=
E(天气|雨)=
以下同理…
3.基于“天气”划分数据集,对应总的信息熵为:
E(天气) = E(天气|晴) + E(天气|阴) + E(天气|雨)
4.对应的信息增益为:
G(天气) = E - E(天气)
同理,求出其他几个属性的信息熵,信息增益。

下面给出4个函数,足够你抵挡一切SQL注入漏洞!读懂代码,你就能融会贯通。 注意...
通过前面两章的介绍,我们已经对XSLT的基本概念和它的转换过程有了一些了解。下...
从MySQL源码看其网络IO模型 前言 MySQL是当今最流行的开源数据库,阅读其源码是...
在做项目的过程中,使用正则表达式来匹配一段文本中的特定种类字符,是比较常用...
本文转载自微信公众号「源码兴趣圈」,作者马称 。转载本文请联系源码兴趣圈公众...
为什么要使用FluentValidation 1.在日常的开发中,需要验证参数的合理性,不紧前...
小皮面板是什么? 小皮面板,是由phpStudy官方团队针对Linux服务器开发推出的一...
html5为input添加了原生的占位符属性placeholder,高级浏览器都支持这个属性,例...
Redis 介绍 Redis 代表REmote DIctionary Server是一种开源的内存中数据存储,通...
1.新建三个html文件,两个php文件和若干个CSS文件和若干个JS文件 2.登录的html页...

