

尚硅谷丨大数据Hadoop 3.x(2021全新升级/部署+源码+实战)
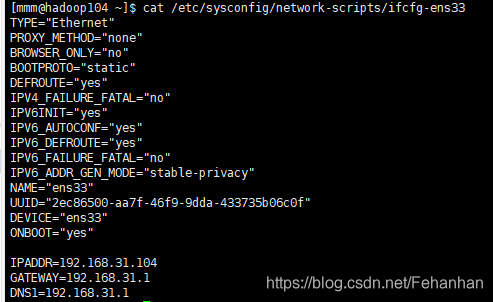
配置ip
如果修改同个局域网下电脑时
首先将虚拟机改为桥联
其次bootproto改为静态
最后需要将他们配置到同一网段即IP地址第三项相同最后一项不同
网关号最后一位试试1和2
vim /etc/sysconfig/network-scripts/ifcfg-ens33
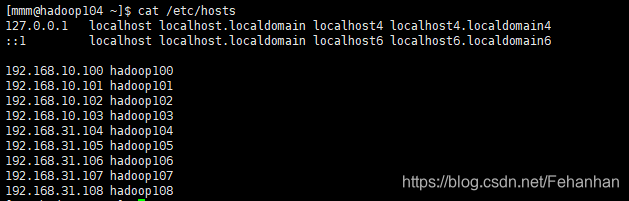
修改主机名称并添加主机名称映射

重启reboot
卸载虚拟机自带jdk
重新安装jdk
安装hadoop
xshell远程连接服务器通讯
在/home/mmm/路径下新建文件夹bin
向其中填入下列代码
变换模式为可执行
将/home/mmm/bin填入环境变量确保任何情况下能够使用
如果分发需要root权限文件需要使用sudo xsync /home/mmm/xsync 文件路径
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop104 hadoop105 hadoop106
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
chmod 777 xsync
获取自身公钥私钥
ssh-keygen -t rsa
将自身公钥私钥发送给自身以及其他电脑
ssh-copy-id hadoop104
测试是否配置成功
ssh hadoop105
其他电脑同样进行配置
1、进入profile.d
cd /etc/profile.d/
2、新建my_env.sh用于存放环境变量
vim my_env.sh
3、向其中添加路径
#JAVA_HOME
export JAVA_HOME=/home/mmm/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/home/mmm/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
4、分发至集群xsync my_env.sh
5、分别在每个服务器上重新载入环境变量
source /etc/profile
6、将hadoop与jdk分发至集群
配置core-site.xml
进入hadoop安装路径/etc/hadoop
编辑core-site.xml
vim core-site.xml
在configuration中添加如下设置
注意缩进以及对主机名称的修改
<!-- 指定NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop104:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/mmm/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为mmm -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>mmm</value>
</property>
配置hdfs-site.xml
同样在configuration中插入如下参数
注意修改主机名称
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop104:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop106:9868</value>
</property>
配置yarn-site.xml
同样在configuration中插入如下参数
注意修改主机名称
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop105</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop105:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
配置mapred-site.xml
同样在configuration中插入如下参数
注意修改主机名称
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop104:10020</value>
</property>
<!-- 历史服务器 web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop104:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/mmm/module/hadoop-3.1.3/etc/hadoop:/home/mmm/module/hadoop-3.1.3/share/hadoop/common/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/common/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/hdfs:/home/mmm/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/hdfs/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/yarn:/home/mmm/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/yarn/*</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/mmm/module/hadoop-3.1.3/etc/hadoop:/home/mmm/module/hadoop-3.1.3/share/hadoop/common/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/common/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/hdfs:/home/mmm/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/hdfs/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/yarn:/home/mmm/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/yarn/*</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/mmm/module/hadoop-3.1.3/etc/hadoop:/home/mmm/module/hadoop-3.1.3/share/hadoop/common/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/common/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/hdfs:/home/mmm/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/hdfs/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/yarn:/home/mmm/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/home/mmm/module/hadoop-3.1.3/share/hadoop/yarn/*</value>
</property>
配置workers
同样进入当前目录workers
将其中localhost删除并添加集群所有主机名称
hadoop104
hadoop105
hadoop106
将etc/hadoop文件夹分发至所有服务器
xsync hadoop安装路径/etc/hadoop
初始化集群
hdfs namenode -format
编写启动脚本
进入home/mmm/bin文件夹下创建myhadoop.sh脚本添加下列代码
注意修改主机名称
变换为可执行模式chmod 777 myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop104 "/home/mmm/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop105 "/home/mmm/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop104 "/home/mmm/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop104 "/home/mmm/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop105 "/home/mmm/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop104 "/home/mmm/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
编写状态查询脚本jpsall
变换为可执行模式chmod 777 jpsall
#!/bin/bash
for host in hadoop101 hadoop102 hadoop103
do
echo =============== $host ===============
ssh $host jps
done
启动集群终端输入myhadoop.sh start
查询集群状态终端输入jpsall
显示状态如下
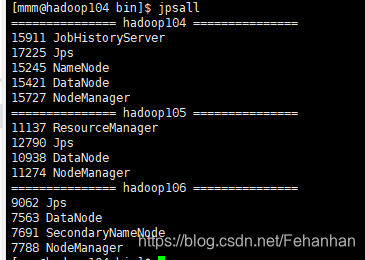
关闭集群终端输入myhadoop.sh stop

? ? 老猿Python博文目录https://blog.csdn.net/LaoYuanPython ? 一、引言 前几天...
本文实例为大家分享了Android九宫格图片展示的具体代码,供大家参考,具体内容如...
jsp按格式导出doc文件实例详解 原理: doc文件其实可以保存为xml文件,该xml文件...
php7中mysql的连接与使用与PHP5中大不相同 PHP5中mysql_connect()等函数大多被PH...
原来是在系统上出了问题.是2003的IIS出现了问题,因为是2003的系统,它对ASP的上...
jsp输出金字塔的简单实例 % String str = ""; for(int i = 1; i = 5; i++){ for(...
前言 在编写程序调用变量时,遇到未定义的变量时,会报错,这是就需要我们对变量...
一、简介 基于matlab GUI最小半径泊车方法仿真 二、源代码 function varargout b...
官方PHP Redis扩展文件下载 https://pecl.php.net/package/redis 选择与你PHP版...
使用bootstrap后他由他自带的样式has-error,想要使用它就会比较麻烦,往常使用j...

