

?
(本文档内容有同事贡献部分,该部分标记为蓝色,对同事表示感谢)
目录
版本:airflow 2.0.0;python 3.6
部署方式:集群部署,运行在anaconda3的虚拟环境 (airflow)
* 节点7 [webserver、schuduler、worker]
* 节点8 [worker]
* 节点9 [worker、schuduler]
官网文档(最新):http://airflow.apache.org/docs/apache-airflow/stable/start.html
非官方翻译中文文档(1.10.2):https://airflow.apachecn.org/#/
default_args = {
'owner': '***',
'start_date': days_ago(1),
'email': ['xxx@qq.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(seconds=50),
'pool': 'test',
'priority_weight': 100
}
baseoperator(
:param task_id: a unique, meaningful id for the task
:type task_id: str
:param owner: the owner of the task, using the unix username is recommended
:type owner: str
:param email: the 'to' email address(es) used in email alerts. This can be a
single email or multiple ones. Multiple addresses can be specified as a
comma or semi-colon separated string or by passing a list of strings.
:type email: str or list[str]
:param email_on_retry: Indicates whether email alerts should be sent when a
task is retried
:type email_on_retry: bool
:param email_on_failure: Indicates whether email alerts should be sent when
a task failed
:type email_on_failure: bool
:param retries: the number of retries that should be performed before
failing the task
:type retries: int
:param retry_delay: delay between retries
:type retry_delay: datetime.timedelta
:param retry_exponential_backoff: allow progressive longer waits between
retries by using exponential backoff algorithm on retry delay (delay
will be converted into seconds)
:type retry_exponential_backoff: bool
:param max_retry_delay: maximum delay interval between retries
:type max_retry_delay: datetime.timedelta
:param start_date: The ``start_date`` for the task, determines
...详见baseoperator源码,注:baseoperator即基础operator。
)
Bashoperator(运行方式为执行bash命令)。例如:
run_this = BashOperator(
task_id='run_after_loop',
bash_command='echo 1',
dag=dag
)
注:可以通过ssh命令在远程机器上执行脚本或命令
2.ExternalTaskSensor(可以用作dag之间依赖,感知前置dag或task执行状态,不必重复执行上层依赖)。例如:
child_1 = ExternalTaskSensor (
task_id = 'henry_1',
external_dag_id = 'henry_test',
# external_task_id = "task_1",
dag = dag
)
3.LatestOnlyOperator(只运行最新的)。可以跳过在 DAG 的最近计划运行期间未运行的任务。例如:
dag = DAG(
dag_id='latest_only_with_trigger',?
schedule_interval=dt.timedelta(hours=4),?
start_date=dt.datetime(2016, 9, 20),
)?
latest_only = LatestOnlyOperator(task_id='latest_only', dag=dag)
4.ExternalTaskMarker(继承自DummyOperator, 该task被clear之后,下游的依赖任务也会递归的全都clear,默认深度10)暂时弃用。
parent_task = ExternalTaskMarker(
task_id="parent_task",
external_dag_id="example_external_task_marker_child",
external_task_id="child_task1",
dag = dag
)
5. TriggerDagRunOperator(直接触发下游dag运行)
t2 = TriggerDagRunOperator(
task_id='trigger_dag',
trigger_dag_id='dag_1',
# 被触发执行的dag的execution_date,str / datetime.datetime,加这个参数执行报错...
# execution_date=datetime.datetime(2021, 3, 5, 8, 20),
# reset_dag_run=True,
# wait_for_completion=False,
# Poke interval to check dag run status when wait_for_completion=True.
# poke_interval=60,
dag=dag,
)
使用时,依次执行命令:?
1)source /home/***/anaconda3/bin/activate airflow? ? ?# 激活虚拟环境
2)cd /home/***/airflow/dags? ? # 进入任务dags目录,然后创建自己名称的文件夹,将任务放入自己名下便于管理
3)构建.py任务文件
4)执行(依实际需要操作,可在web页面操作)
* python 任务文件确保编译没问题
* 运行task:airflow dags?run?<dag_id> <task_id> <execution_date>
* 重跑/回溯历史任务:airflow dags?backfill?<dag_id>-s?START_DATE?-e?END_DATE
1.打通airflow和任务的时间参数,让页面操作的时间范围能正确带入到任务脚本
# The execution date as YYYY-MM-DD date ="{{ ds }}"t = BashOperator( task_id='test_env', bash_command='/tmp/test.sh ', dag=dag, env={'EXECUTION_DATE': date})
?
这里,?{{ ds }}是一个宏,并且由于BashOperator的env参数是使用 Jinja 模板化的,因此执行日期将作为 Bash 脚本中名为EXECUTION_DATE的环境变量提供。
您可以将 Jinja 模板与文档中标记为“模板化”的每个参数一起使用。模板替换发生在调用运算符的 pre_execute 函数之前。
注意,由于airflow实际上接管了日期参数,多日重跑或者回溯的数据,实际上是由多个单日的任务组合而成,也就意味着原有的本身支持批量跑数的python脚本要改成单天执行的脚本,或者直接在bashoperator的bash_command中添加两个一样的时间参数{{ ds }},如 bash_command="python test.py?{{ ds }} {{ ds }}",(不过原有脚本的一些功能可能就会发生改变,比如原来在时间范围循环内执行完多天统一发送邮件的,现在的效果则变成每天一封邮件)。
?
?
2.任务报警(邮件需要修改配置文件,配置邮件服务,才能使任务脚本中的邮件报警生效)
直接修改airflow.cfg保存退出即可生效,不需要执行任何airflow命令。不要执行airflow initdb。
# smtp server here
smtp_host = smtp.exmail.qq.com(注意这里不要输错,第二个位置是exmail而不是email)
smtp_starttls = False
smtp_ssl = True
# Example: smtp_user = airflow
smtp_user = 发件用户,一般和下面的发件人一致即可(之后改为mmribao)
# Example: smtp_password = airflow
smtp_password =?
smtp_port = 465
smtp_mail_from = 发件人
?
任务文件中示例:
default_args = {
? ? 'owner': '***',
? ? 'start_date': days_ago(1),
? ? 'email': ['xxx@.com'],
? ? 'email_on_failure': True,
? ? 'email_on_retry': False,
? ? 'retries': 1,
? ? 'retry_delay': timedelta(seconds=5),
}
?
邮件内容效果:
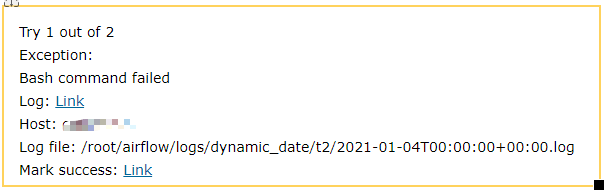
?
3.任务队列以及优先级问题(先搭建集群后使用celery的queue)
default_args里面增加了:
'queue':'ribao','pool':'daily','priority_weight':100
之后,任务执行异常,之前会正常执行各部分task且失败后会发送邮件,但是增加了这三个参数之后,重跑和例行都不会执行子task也不会发送失败邮件(看起来压根没有按照正常的步骤执行任务)。增加之后删除这3项参数,当天执行重跑也会产生相应的异常,第二天例行之后才会正常执行失败并且发送邮件。
注:这里的queue和pool含义不同,假如启动celery的worker的时候指定了?-q? 参数,那么该worker就会专门被指定用来跑该queue的任务,之后提交该名称的queue任务的时候,就会由该worker来执行。
实际使用的时候,只需要添加pool和priority_weight属性即可实现日常需求。
?
4.任务命名规范
web页面是按照字母a-z排序的,同时后几位也会按按位比较大小。
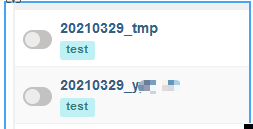
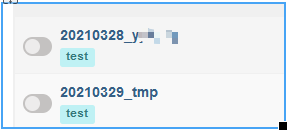
同时dag名称是唯一的(task_id只作用在本dag内,不同dag的taskid可以同名),所以正式的dag命名:
年月日_人名首字母_根据业务或功能自行命名,如:
20210303_人名首字母_业务
年月日首先避免了绝大多数重名风险,人名首字母进一步将名称重名的可能性锁定在本人任务重,极大程度减少和别人任务同名的可能。
?
5.是否更新到airflow2.0(使用节点7、节点8/节点9另外搭建2.0,不影响之前的单点1.10)
已解决,直接部署了2.0
6.使用celery构建集群
celery的监控页面flower:http://***:5555。执行单位是task,同一个dag的不同task可能被分配到不同的worker执行,可以从flower页面看到执行节点。
考虑节点7作为主节点,节点8作为子节点,节点9作为子节点。
mysql取消使用docker的原因:docker可以部署mysql服务,但是本地物理机需要安装mysql客户端,但是物理机安装客户端的时候,会对已有的mariadb进行依赖升级,而已有的mariadb的一些依赖被hadoop一些组件所依赖。害怕影响集群,所以这种方式也不保险。索性使用运维提供的二进制安装包方式绕过依赖问题安装mysql5.7以及客户端,依赖问题不存在了,也就没有使用docker的必要了。
但是经过测试,mysql5.7及之前版本,容易发生死锁问题,由于行级锁。并且也不支持scheduler HA,所以直接换为docker的mysql8,但是mysql8又有其他问题,比如源码无法正确识别mysql8版本,导致执行不合版本的sql语句。故重新测试安装postgresql9.6/10,最后现在使用postgresql10,并启动2个scheduler。
?
说明:redis使用docker搭建了哨兵,但是airflow配置broker里面需要填写一个redis地址,但是哨兵是3个,分别监控各自的redis,并不能起到一个类似zookeeper的作用(它通过api可以告知主节点的ip,但是不能自动直接连接到主节点,所以暂时仍然在airflow.cfg里面手动填写一个redis主节点的地址)。
然后redis也更换为rabbitmq,但是未能解决web页面的按钮功能失效,比如重跑回溯任务偶发失败。所以应该是airflow的bug问题,而非redis不如rabbitmq,并且,rabbitmq在使用时,celery不能很好检测到其worker运行状态,必须重新启动rabbitmq和scheduler,然后worker才能工作,但是flower始终显示worker离线,但是换成redis就立即能够识别出worker在线状态。后来也将result_backend也换为redis和amqp,都未能解决按钮失效功能。并且官方强烈建议backend存入传统意义上的数据库,索性换回redis+postgresql组合。
最重要的还是airflow的dag脚本文件。
老架构:

?
现有架构:

7.配置日志组件(先测试hdfs路径是否能够使用)
应该是不行了。。
各节点的logs文件夹的内容是不一样的,也就是不同的机器执行任务产生的日志不同(执行什么,产生什么)。
8.dag文件必须放在启动scheduler的节点(节点7)。或者修改配置文件,目前配置文件都是本机的dags目录,但是worker节点不检测任务文件。
9.目前的任务都是先登录到节点10上然后进行操作,需要注意大批量迁移后,大量连接登录的问题(连接数限制问题)。
10.celery的flower的时区是否需要修改(需要修改celery的源码,最后再说)
11.测试externaltaskmarker和externaltasksensor,在上游任务重跑后,会有怎样的效果。并且在这两个实例中execution_date的使用。
这两个部件在web页面使用有问题,客户端命令可以较为正常运行,但是sensor仍然不会随着marker的清理而自动重跑。基本需要客户端手动执行命令才能正常。基本上只有第一次执行遇到前置失败会报警。 1
12.编辑一个任务,定期清理logs文件夹的历史文件,因为批量使用后,会产生大量的日志。后来查看发现,日志量大的主要是scheduler产生的,所以设定了任务,每天自动清理logs/scheduler下的当日的前天的目录。
13.编写一个dags文件夹分发的任务,每次有人更新了自己的任务文件,就要手动重跑该任务,更新dags文件夹到节点8和节点9.
14.任务超时设置问题,因为现有任务尤其是spark的任务通常都要几分钟甚至更久,但是目前airflow的默认的超时判定好像都很短,这个值要
置的大一点。
?

复制代码 代码如下: % URL="http://news.163.com/special/00011K6L/rss_newstop....
教程前先给大家看看小编的实现成果吧! 图1: 图2: 图3: 教程: 实现这个功能...
首先定义个文本域并且给个ID textarea id="O_txt_1" rows="8" cols="80" !--要运...
不知道是不是年龄大了 经受折磨的时候总会怀念过去 一辈子很短好日子并不多,要学...
名花有主已 C语言中有一些预先定义的字符串他们本身被赋予了自身的功能。并且我...
如何准确地获得一个整数? function NumbersOnlyNoDecimals(pInString) lNumbers...
由于同一进程的多个线程共享一块存储空间在带来方便的同时也带来了访问冲突问题...
新人小白第一次用vs就出现了问题,如图: 主要表现为:发生生成错误。是否继续运...
NoSQL 现在非常火,我看过的简历里面十个有九个都写了熟悉 NoSQL,但是对于 NoSQ...
为了保护个人隐私,一般人都会给自己的电脑设置登录密码,以防止他人随便使用,...

