

上图已魔法反爬,哈哈哈,想爬就爬呗,不拦着。
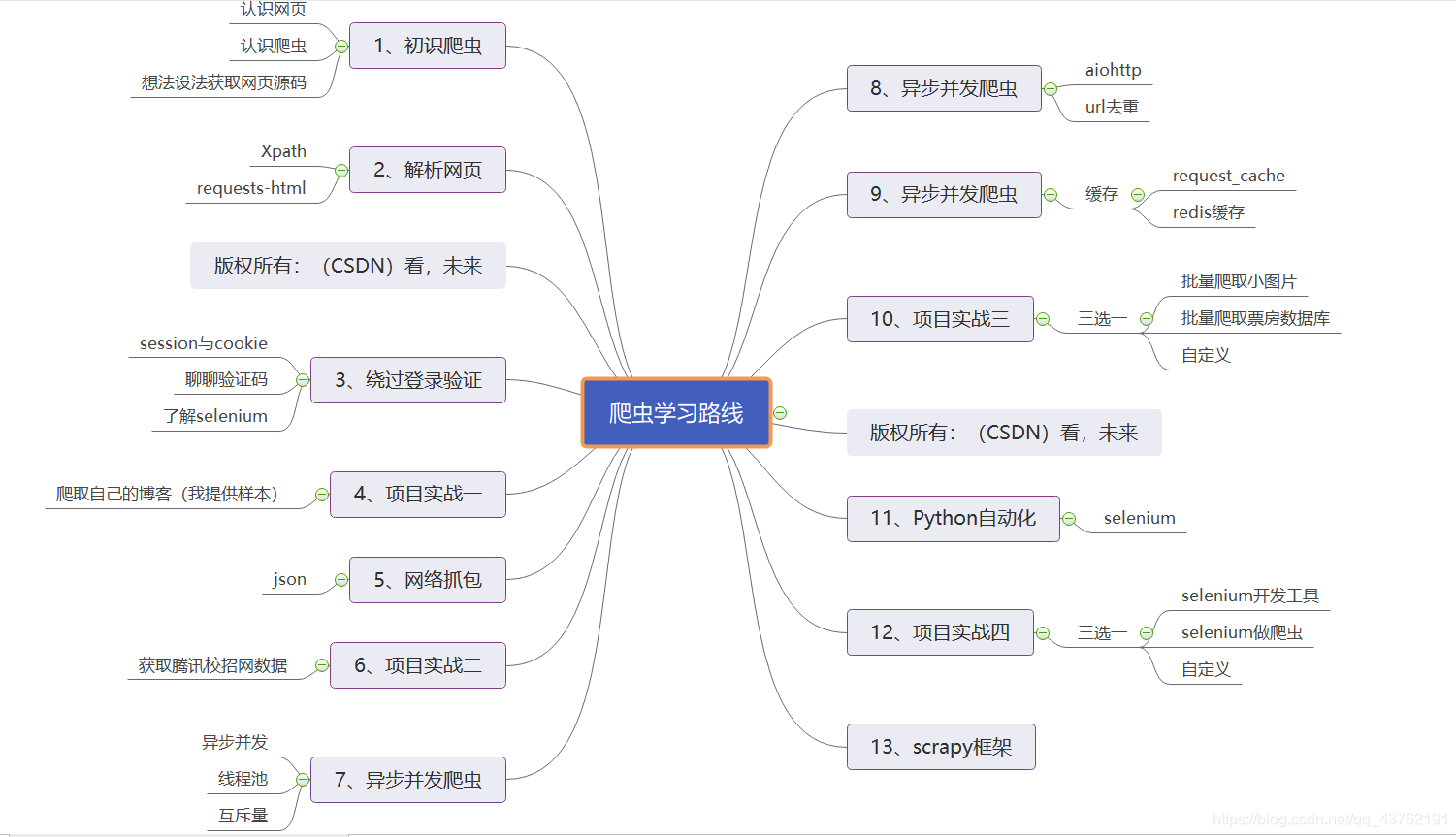
本系列会写一些什么内容,在开头那张思维导图里面写了个大概了,至于导图里面没有写出来的,就作为一些探索的内容吧。
我之前有写过一个Python爬虫自学系列,反响也还可以,不过那个系列里面的不少链接是另一个付费专栏里面的内容了,相对要阅读就有些困难。
这个系列是在原有知识点的基础上,加入一些新的知识点,重新写的一个系列。不出意外,这个系列将会是我在Python爬虫领域的最后一个教学系列。
这个系列是会有配套视频课的,将会发布在CSDN学院上,当然,如果还是喜欢看博文的朋友可以看我的这个系列。
由于参加了CSDN的“蓄力计划”,诸多条条框框,总结一下就是为读者服务,所以这个系列会写的很认真,毕竟我想上榜啊,大家多多支持。
有Python基本语法基础的人,分支循环、函数、类、模块、异常处理等。
不喜欢枯燥乏味的填鸭式教育的朋友。
肯动手实操为最佳。
不知道大家对于爬虫这项技术是怎么看的,我是犹豫了很久,才学的爬虫(要不是学长把买好的课拍在我面前,我估计还不动手)。倒不是说爬虫有多难,但是在当时的我看来,爬虫技术离我那是十万八千里,爬虫会不会很难呐。但是真的放下心里的包袱去学的时候,会发现爬虫也就那样,一个月入门爬虫绰绰有余了。
为什么要专门讲这个呢,因为有的年轻人,入门爬虫之后就会比较喜欢炫技,这也无可厚非啦,我也有过一段喜欢炫技的时间。
但是呢,我们学习爬虫技术,使用爬虫技术,最本质的目标是什么?不就是为了获取数据嘛。
获取什么数据?
可以复制的数据、
可以复制的数据,但是量大、
不可以复制的数据、
不可以复制的数据,而且量还大、
多种数据糅杂
···
大概是这些吧。那我们先来简单讲一下针对这些数据,分别要如何处理吧。
对于第一种:那还费什么话,直接复制粘贴就好,我想应该没有人会专门为了这种数据去写个爬虫吧?
对于第二种:那需要使用爬虫了,这里的量大,怎么说也得有个几十上百页吧。但是这时候我们不要自己去写爬虫,应该使用现有代码框架。
这里的框架指的是我们自己平时封装好的代码框架,不要迷恋什么scrapy框架,数据量还没大到那个程度呢。
在本系列中,我会陆陆续续放上我自己平时使用的比较顺手的封装代码,大家自取。
对于第三种:如果还在“提取图中文字”的朋友可以停手了,学完这篇就可以停手了。我们直接打开它的源码,直接复制就好了。
对于第四种:既然不让复制,那要直接爬取就比较麻烦了,这时候就需要根据实际情况选用合适的方法来爬取了。
对于第五种:伺机而动,爬下来之后还要做一系列数据清洗工作才行。
总之,这个系列贯穿头尾的线索就是:怎么简单怎么来,好不?咱不搞那些花里胡哨的
玩爬虫呐,是有可能会跟“法”打交道的,这点大家还是要了解一下的,新闻上时不时的就有报道,说某某数据团队被一锅端了,因为爬了不该爬的数据,并做商用。
然后呢,我昨晚苦思冥想,想到了老师上课所说的一句话:我们为了学术研究而去获取的资料,不拿去传播就没有太大的问题。
懂我意思吧,不拿去传播。
其实吧,就我这技术,能拿去卖钱的数据,我也拿不到嘛。
好了好了,言归正传,写爬虫的都知道一般网站都有robot.txt,可以看网站上的哪些目录拒绝爬虫,这个文件一般在网站的根目录后面跟上robot.txt打开,如果比较稳重的朋友建议采用这种方式。像我这种比较飘的,就直接爬了,不给爬的话,返回的状态量就会直接提示了。
网站地图就先不说啦,后面批量爬取的时候再说,那个东西可真的是玩火了。
“学爬虫,对HTML的要求很高吗?”很多朋友都问我这个问题。
我说我一个后端选手都能学爬虫,你们怕什么?
推荐使用浏览器:谷歌浏览器
随便打开一个网页,或者你们就对着这篇博客,我们来打开网页源代码看一下:
方法一:网页空白处右击,检查
方法二:F12
如果遇上那种不让右击,又不让F12的网页的话,这种网页比较少见,但是碰到的时候还是很懵逼的。
方法三:Ctrl+Shift+i
方法四:鼠标点击网址栏,然后再按F12。目前不清楚这是个例还是通用的,因为我就遇到了一个这种网页。
方法五:自定义及控制->更多工具->开发者工具。
作为一个爬虫选手,如果连审查页面元素的能力都没有,那也就不要干了嘛。
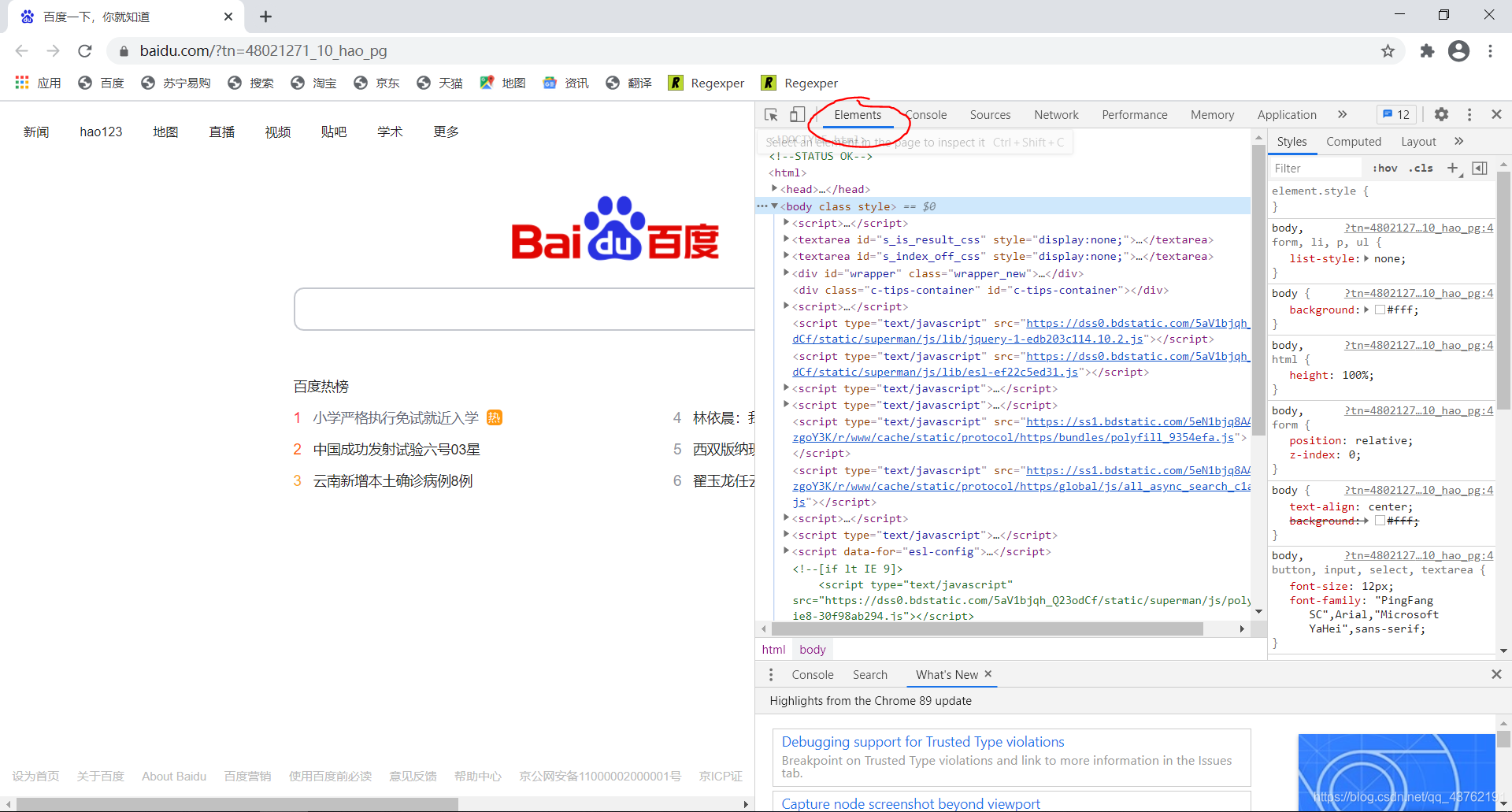
左边这一块儿,就是网页源码。
而我们今天的任务也很明确,获取它的源码。
这一块儿,有一个比较出名且常用的模块儿来专门负责:requests。
import requests
获取网页源码也只需要一行简单的代码:
res = resquests(url,headers = headers)
有时候需要带上个头,有时候不需要。不过大部分时候需要,那就带上吧。
先看代码,然后我们对着代码里面还没说的点进行补充。
目前的封装代码如下:
def get_html(url,times):
'''
这是一个用户获取网页源数据的函数
:param url: 目标网址
:param times: 递归执行次数
:return: 如果有,就返回网页数据,如果没有,返回None
'''
try:
res = requests.get(url = url,headers = {
"User-Agent":random.choice(user_agent_list) # 注一
}) #带上请求头,获取数据
if res.status_code>=200 and res.status_code<=300: # 注二
return res
else:
return None
except Exception as e:
print(e) # 显示报错原因(可以考虑这里写入日志)
if times>0:
get_html(url,times-1) # 递归执行
这里是一个请求头的列表。
倒不是我小气,IP池分两种,一种是私用的,一种是公有的,公有的IP池有现成的包,from fake_useragent import UserAgent,但是公有的IP都不稳定啊,毕竟大家都在用,用多了就让人封了呗。封了你还不知道,傻乎乎的去用,就爬不到数据了呗。
user_agent_list = [
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",
]
还是上面那个图,在“Element”右边,找到一个“network”,点进去,什么都没有,是吧。
在左边的网页上,右击,重新加载。
如果网页是无法右击状态的话,可以在电脑左上角,刷新网页。这时候,右侧就会出现一些包。
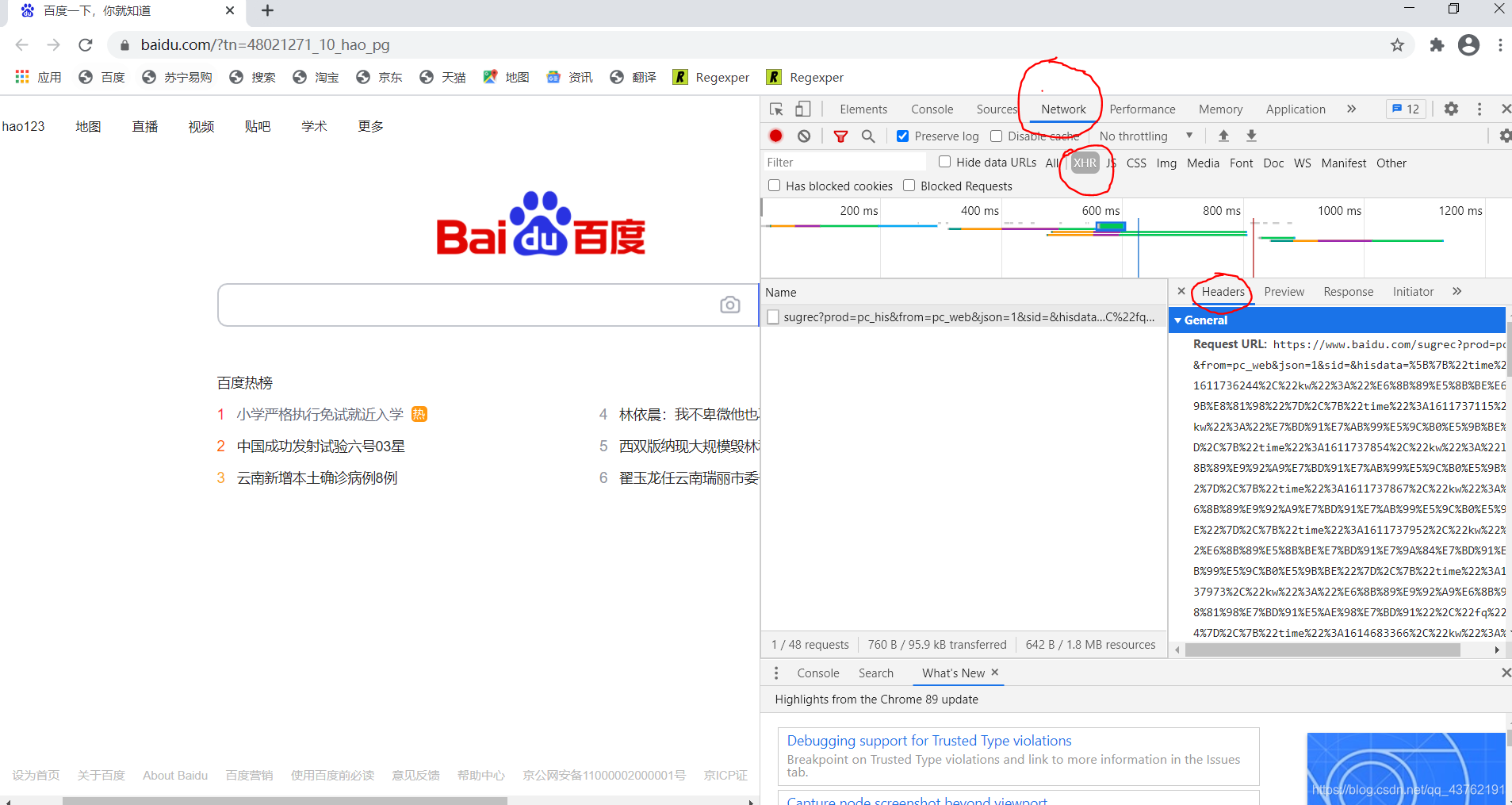
看到没,我圈起来的那三个圈,从上往下依次点击两个,然后会发现包少了一些,随便点一个,再点我圈出来那第三个圈,然后往下划,找到一个“User-Agent”打头的,把后面那个复制下来。
如果没有就再找一个包。
那个是网页校验码,当校验码在以2XX的形式存在的时候,说明这个网页可以被爬取,否则就不要想太多啦。
今天就先到这里,下篇见咯。


前言 aop即是面向切面编程,众多Aop框架里Castle是最为人所知的,另外还有死去的...
开发过程中,我们经常会遇到代码回滚的情况。正常人都知道,git 回滚有两大宝: ...
本文转载自微信公众号「Linux开发那些事儿」,作者 LinuxThings 。转载本文请联...
一、Postman背景介绍 用户在开发或者调试网络程序或者是网页B/S模式的程序的时候...
互联网业务往往使用MySQL数据库作为后台存储,存储引擎使用InnoDB。我们针对互联...
简介 “ 大家好我是帅哥欢迎来到帅哥的程序人生我会把经历分享出来助你了解圈内...
2月26日消息 众所周知,Windows 10 的安全更新和其他重要累计更新通常是在同一天...
不少Windows 10用户之前都抱怨一个问题,那就是系统的屏幕出现了渲染问题,而微...
console.log ,作为一个前端开发者,可能每天都会用它来分析调试,但这个简单函...
继 Australis 和 Photon 之后,Mozilla 现又酝酿为 Firefox 带来名为Proton的全...

