???突然想学大数据了,加上上课老师把大数据说的天花乱坠,我还没听懂😟,于是只能课下开小灶。大致了解一下大数据的一些基本概念和名词。
1.大数据的概念
大数据:是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新的处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。一般来说就是指存储数据在TB、PB、EB量级的数据。
- 主要解决海量数据的采集、存储和分析计算的问题。
- 数据量大
- 产生速度快
- 数据类型多样:结构化(数据库/文本)和非结构化数据(网络日志、音频、视频、图片、地理位置等)
- 密度大,价值低,即价值密度的高低和数据量大小成反比。
2.Hadoop介绍
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
- 主要解决海量数据的存储和海量数据的分析计算的问题。
- 广义上来说,Hadoop 通常是指一个更广泛的概念——Hadoop 生态圈。
3.Hadoop的版本
hadoop的三大发行版本:Apache、Cloudera、Hortonworks。
- Apache版本最原始(最基础),对入门学习最好。
- Cloudera内部集成了很多大数据框架,对应产品CDH。
- Hortonworks文档较好,对应产品HDP 。
- Hortonwork和Cloudera合并
3.Hadoop的特点
- 高可靠性:Hadoop底层维护多个数据副本,即使某个计算单元存储出现故障,也不会导致数据丢失。
- 高拓展性:在集群之间分配任务数据,可方便的扩展数以万计节点。
- 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
- 高容错性:能够自动将失败的任务重新分配。
4.Hadoop的组成
- Hadoop1.X版本的组成
MapReduce负责计算和计算所需的cpu、内存等资源的调度
- Hadoop2.X版本的组成
增加了Yarn进行资源调度,原来的MapReduce只负责计算。
- Hadoop3.X版本的组成没啥区别,在细节上还是有区别的。
5.HDFS
HDFS(Hadoop Distributed File System)是一个分布式文件系统。
大致是这样的:将一个很大的文件拆成很多部分,然后存储在一个个DataNode中,而NameNode中只存储DataNode的位置信息,2NN对NameNode进行备份(害怕NameNode挂掉,然后丢失所有信息。)
- NameNode(nn):存储文件的元数据,如文件名、文件目录结构、文件属性,以及每个文件的块列表和块所在的DataNode等。
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NameNode(2nn):每隔一段时间对NameNode进行备份。
6.YARN
YARN(Yet Another Resource Negotiator),是一种资源协调者,是Hadpood的资源管理器。
- ResourceManager(RM):整个集群资源(内存、CPU)的老大。
- NodeManager(NM):单个节点服务器资源老大。
- ApplicationMaster(AM):单个任务运行的老大。
- client:客户端
- Container:容器,相当于一台独立的服务器,里面封装了运行所需的资源,如内存、CPU、磁盘、网络等。
-
客户端可有多个、集群上可有运行多个ApplicationMaster、每个NodeManager上可以有多个Container.
7.MapReduce
MapReduce将计算过程划分为两个阶段:MAP和Reduce
- Map阶段并行处理输入数据。
- Reduce阶段对Map结果进行汇总。
100T的数据已经被分被存储到很多台服务器上,如果需要找寻某个资料,我们就可以要求各个服务器并行寻找自己的电脑上有没有对应的内容,然后把结果告诉汇总服务器。
8.HDFS、YARN和MapReduce三者的关系
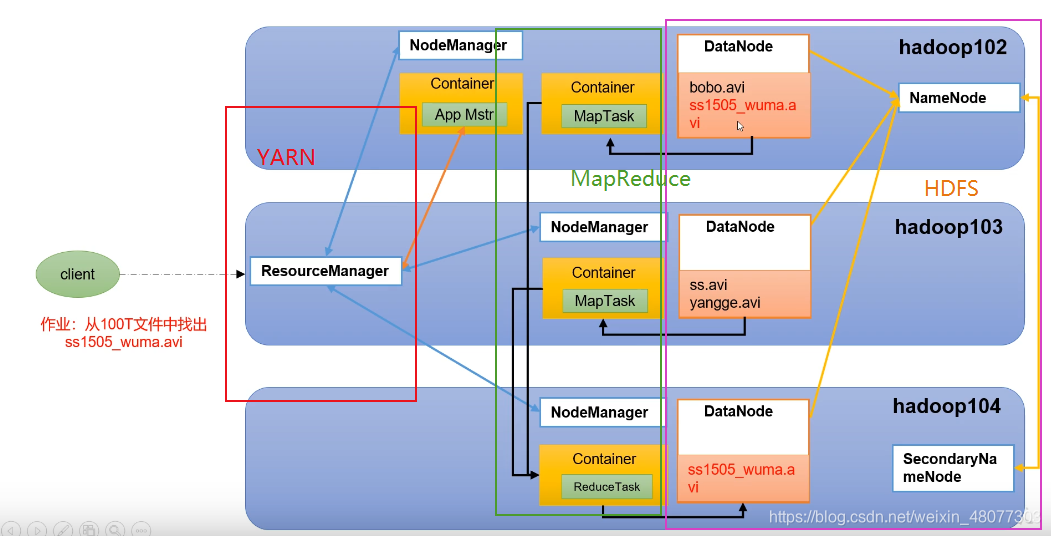
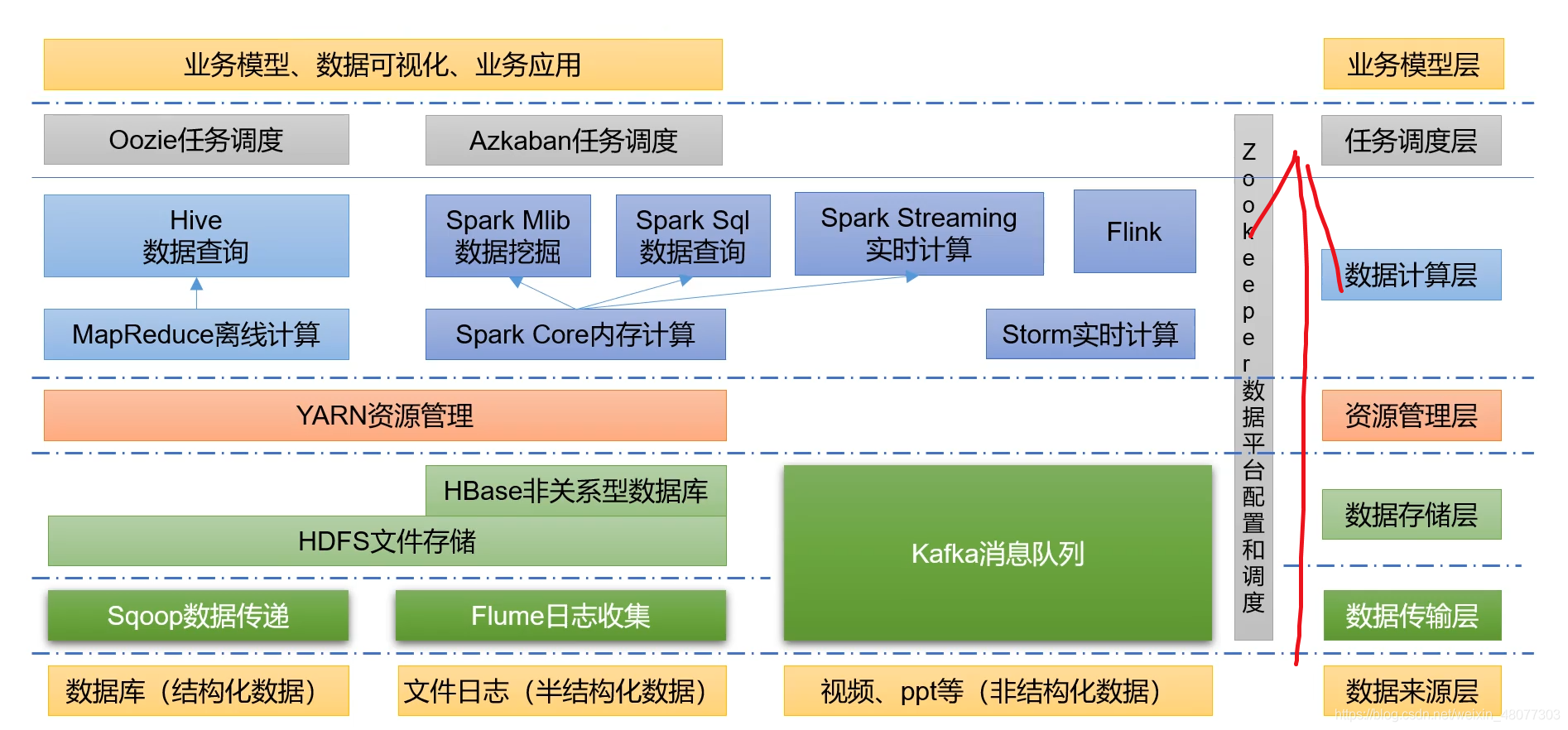
9.大数据处理的过程
参考资料:
大数据课程《Hadoop入门》




