

本文主要总结了工作中一些常用的操作及不合理的操作,在对慢查询进行优化时收集的一些有用的资料和信息,本文适合有 MySQL 基础的开发人员。
索引相关
索引基数
基数是数据列所包含的不同值的数量,例如,某个数据列包含值 1、3、7、4、7、3,那么它的基数就是 4。
索引的基数相对于数据表行数较高(也就是说,列中包含很多不同的值,重复的值很少)的时候,它的工作效果***。
如果某数据列含有很多不同的年龄,索引会很快地分辨数据行;如果某个数据列用于记录性别(只有“M”和“F”两种值),那么索引的用处就不大;如果值出现的几率几乎相等,那么无论搜索哪个值都可能得到一半的数据行。
在这些情况下,***根本不要使用索引,因为查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。惯用的百分比界线是“30%”。
索引失效原因
索引失效的原因有如下几点:
MySQL 8.0 开始支持函数索引,5.7 可以通过虚拟列的方式来支持,之前只能新建一个 ROUND (t.logicdb_id) 列然后去维护。
索引的建立
索引的建立需要注意以下几点:
EXPLIAN 中有用的信息
基本用法
EXPLIAN 基本用法如下:
提高性能的特性
EXPLIAN 提高性能的特性如下:
5.6 版本开始当 ICP 打开时,如果部分 where 条件能使用索引的字段,MySQL Server 会把这部分下推到引擎层,可以利用 index 过滤的 where 条件在存储引擎层进行数据过滤。
EXTRA 显示 using index condition。需要了解 MySQL 的架构图分为 Server 和存储引擎层。
一般用 or 会用到,如果是 AND 条件,考虑建立复合索引。EXPLAIN 显示的索引类型会显示 index_merge,EXTRA 会显示具体的合并算法和用到的索引。
Extra 字段
Extra 字段使用:
MySQL 中无法利用索引完成的排序操作称为“文件排序”,其实不一定是文件排序,内部使用的是快排。
using filesort、using temporary 这两项出现时需要注意下,这两项是十分耗费性能的。
在使用 group by 的时候,虽然没有使用 order by,如果没有索引,是可能同时出现 using filesort,using temporary 的。
因为 group by 就是先排序在分组,如果没有排序的需要,可以加上一个 order by NULL 来避免排序,这样 using filesort 就会去除,能提升一点性能。
type 字段
type 字段使用:
字段类型和编码
MySQL 返回字符串长度
CHARACTER_LENGTH(同CHAR_LENGTH)方法返回的是字符数,LENGTH 函数返回的是字节数,一个汉字三个字节。
varchar 等字段建立索引长度计算语句
select count(distinct left(test,5))/count(*) from table;越趋近 1 越好。
MySQL 的 utf8
MySQL 的 utf8 ***是 3 个字节不支持 emoji 表情符号,必须只用 utf8mb4。需要在 MySQL 配置文件中配置客户端字符集为 utf8mb4。
JDBC 的连接串不支持配置 characterEncoding=utf8mb4,***的办法是在连接池中指定初始化 SQL。
例如:hikari 连接池,其他连接池类似 spring . datasource . hikari . connection - init - sql =set names utf8mb4。否则需要每次执行 SQL 前都先执行 set names utf8mb4。
MySQL 排序规则
一般使用 _bin 和 _genera_ci:
那么,同样是区分大小写,utf8_general_cs 和 utf8_bin 有什么区别?
初始化命令
SQLyog 中初始连接指定编码类型使用连接配置的初始化命令,如下图:

SQL 语句总结
常用但容易忘的
SQL 语句常用但容易忘的总结如下:
锁相关
锁相关(作为了解,很少用):
优化时用到
优化时用到:
查看状态
查看状态:
SQL 编写注意
SQL 编写请注意:
踩坑
踩坑总结如下:
千万大表在线修改
MySQL 在表数据量很大的时候,如果修改表结构会导致锁表,业务请求被阻塞。
MySQL 在 5.6 之后引入了在线更新,但是在某些情况下还是会锁表,所以一般都采用 PT 工具( Percona Toolkit)。
如对表添加索引:
- pt-online-schema-change --user='root' --host='localhost' --ask-pass --alter "add index idx_user_id(room_id,create_time)"
- D=fission_show_room_v2,t=room_favorite_info --execute
慢查询日志
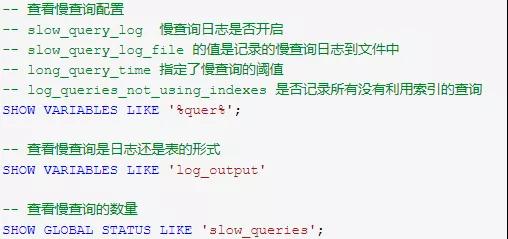
有时候如果线上请求超时,应该去关注下慢查询日志,慢查询的分析很简单,先找到慢查询日志文件的位置,然后利用 mysqldumpslow 去分析。
查询慢查询日志信息可以直接通过执行 SQL 命令查看相关变量,常用的 SQL 如下:
mysqldumpslow 的工具十分简单,我主要用到的参数如下:
例子:mysqldumpslow -v -s t -t 10 mysql_slow.log.2018-11-20-0500。
查看 SQL 进程和杀死进程
如果你执行了一个 SQL 的操作,但是迟迟没有返回,你可以通过查询进程列表看看它的实际执行状况。
如果该 SQL 十分耗时,为了避免影响线上可以用 kill 命令杀死进程,通过查看进程列表也能直观的看下当前 SQL 的执行状态;如果当前数据库负载很高,在进程列表可能会出现,大量的进程夯住,执行时间很长。
命令如下:
- --查看进程列表
- SHOW PROCESSLIST;
- --杀死某个进程
- kill 183665
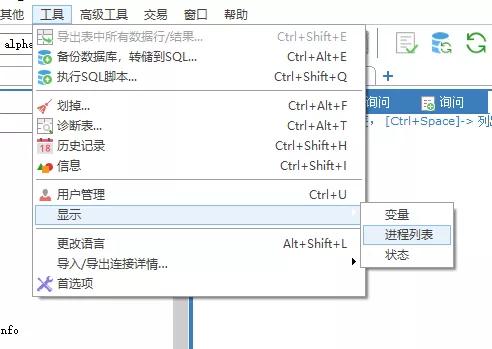
如果你使用的 SQLyog,那么也有图形化的页面,在菜单栏→工具→显示→进程列表。
在进程列表页面可以右键杀死进程,如下所示:

一些数据库性能的思考
在对公司慢查询日志做优化的时候,很多时候可能是忘了建索引,像这种问题很容易解决,加个索引就行了。但是有几种情况就不是简单加索引能解决了:
业务代码循环读数据库
考虑这样一个场景,获取用户粉丝列表信息,加入分页是十个,其实像这样的 SQL 是十分简单的,通过连表查询性能也很高。
但是有时候,很多开发采用了取出一串 ID,然后循环读每个 ID 的信息,这样如果 ID 很多对数据库的压力是很大的,而且性能也很低。
统计 SQL
很多时候,业务上都会有排行榜这种,发现公司有很多地方直接采用数据库做计算,在对一些大表做聚合运算的时候,经常超过五秒,这些 SQL 一般很长而且很难优化。
像这种场景,如果业务允许(比如一致性要求不高或者是隔一段时间才统计的),可以专门在从库里面做统计。另外我建议还是采用 Redis 缓存来处理这种业务。
超大分页
在慢查询日志中发现了一些超大分页的慢查询如 Limit 40000,1000,因为 MySQL 的分页是在 Server 层做的,可以采用延迟关联在减少回表。
但是看了相关的业务代码正常的业务逻辑是不会出现这样的请求的,所以很有可能是有恶意用户在刷接口,***在开发的时候也对接口加上校验拦截这些恶意请求。


前言 关于Window,你了解多少呢?看看下面这些问题你都能答上来吗。 如果你遇到这...
从功能测试、性能测试、界面测试、安全性测试、易用性、兼容性测试、震动测试七...
今日国内领先的智能数据服务运营商觉非科技完成近亿元A轮融资。本轮融资由和高资...
我们知道微软将会在今年给Windows10更换全新设计的UI,让Windows10的界面更加整...
一、简介 本设计为硬币图像识别统计装置通过数码相机获取平铺无重叠堆积的硬币的...
git工作区,暂存区,版本库之间的关系: 我们建立的项目文件夹就是工作区,在初...
本文实例讲述了jsp中page指令用法。分享给大家供大家参考。具体如下: 一、JSP ...
大家好,今天我们来简单的聊一聊缓存问题。什么是缓存呢?它在系统设计中是在一个...
首先给扑克牌中每张牌设定一个编号,下面算法实现的编号规则如下: u 红桃按照从...
一、MVC MVC模式的意思是,软件可以分成三个部分。 视图(View):用户界面。 控...

