

本文的volatile是Java中的,虚拟机默认是hotspot,默认是英特尔x86_64处理器.同时希望你有Java多线程的基础和Java虚拟机的相关知识 如果发现本文有错误,烦请告知
上一篇文章万字长文深入剖析缓存一致性协议(MESI),内存屏障我们花了大量的篇幅讲述缓存一致性协议,明白缓存一致性协议确保了一个处理器对某个内存地址进行的写操作的结果能够被其他处理器读取,但并不能保证一个处理器对共享变量所做的更新具体在什么时候能够被其他处理器读取,比如Store Buffer,Invalidate Queue的存在可能导致一个处理器读取到共享变量的旧值。为了解决这个问题,又引入了内存屏障。但是由于多种处理器架构的存在,它们对有序性的保障也各不相同。例如x86处理器仅支持StoreLoad重排序,而ARM处理器支持四种重排序。
这篇文章我们回到Java的世界,Java作为一个跨平台(跨操作系统和硬件)的语言,为了屏蔽不同处理器的差异,避免Java程序员根据不同的处理器编写不同的代码,定义了Java内存模型(Java Memory Model),简称JMM。Java内存模型是一套规范,描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取变量这样的底层细节。
Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。

这里面提到的主内存和工作内存,可以简单的类比成计算机内存模型中的主存和缓存的概念。特别需要注意的是,主内存和工作内存与JVM内存结构中的Java堆、栈、方法区等并不是同一个层次的内存划分,无法直接类比。如果两者一定要勉强对应起来,那么从变量、主内存、工作内存的定义来看,主内存主要对应于Java堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域,但这也只是大致划分。从更基础的层次上说,主内存直接对应于物理硬件的内存,而为了获取更好的运行速度,虚拟机(或者是硬件、操作系统本身的优化措施)可能会让工作内存优先存储于寄存器和高速缓存中,因为程序运行时主要访问的是工作内存。
在执行程序时,为了提高性能,在不影响程序(单线程程序)正确性的情况下,编译器和处理器常常会对指令做重排序。重排序分3 种类型。

public class ReorderDemo {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
for (int i = 0; ; i++) {
x = 0; y = 0;
a = 0; b = 0;
Thread one = new Thread(() -> {
a = 1;
x = b;
});
Thread other = new Thread(() -> {
b = 1;
y = a;
});
one.start();
other.start();
//主线程在这堵塞,等待one线程执行完毕
one.join();
//主线程在这堵塞,等待other线程执行完毕,可能此时other线程已经执行完毕
other.join();
if (x == 0 && y == 0) {
String result = "第" + i + "次(" + x + ", " + y + ")";
System.out.println(result);
}
}
}
}
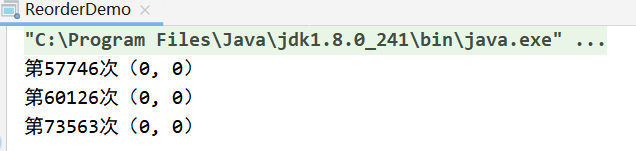
按照正常的结果是不会出现(0,0)这个结果的,这种现象只有在x=b跑到a=1前面,并且b=1和y=a在a=1前面执行才有可能产生,以上实验结果证明了指令确实进行重排。

对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于2和3,JMM的处理器重排序规则会要求Java编译器在生成指令序列时,插入特定类型的内存屏障指令,通过内存屏障指令来禁止特定类型的处理器重排序。
JVM 一共提供了四种 Barrier。比如 LoadLoad Barrier 就是放在两次 Load 操作中间的 Barrier,LoadStore 就是放在 Load 和 Store 中间的 Barrier。具体如下:
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad Barriers | Load1;LoadLoad;Load2 | 用于保证访问 Load2 的读取操作一定不能重排到 Load1 之前。类似于前面说的 Read Barrier,需要先处理 Invalidate Queue 后再读 Load2; |
| StoreStore Barriers | Store1;StoreStore;Store2 | 用于保证 Store1 及其之后写出的数据一定先于 Store2 写出,即别的 CPU 一定先看到 Store1 的数据,再看到 Store2 的数据。可能会有一次 Store Buffer 的刷写,也可能通过所有写操作都放入 Store Buffer 排序来保证; |
| LoadStore Barriers | Load1;LoadStore;Store2 | 用于保证 Store2 及其之后写出的数据被其它 CPU 看到之前,Load1 读取的数据一定先读入缓存。甚至可能 Store2 的操作依赖于 Load1 的当前值。 |
| StoreLoad Barriers | Store1;StoreLoad;Load2 | 用于保证 Store1 写出的数据被其它 CPU 看到后才能读取 Load2 的数据到缓存。如果 Store1 和 Load2 操作的是同一个地址,StoreLoad Barrier 需要保证 Load2 不能读 Store Buffer 内的数据,得是从内存上拉取到的某个别的 CPU 修改过的值。StoreLoad 一般会认为是最重的 Barrier ,它会清空Invalidate Queue并将Store Buffer中的内容写入高速缓存,即StoreLoad屏障能够实现其他三个基本内存屏障的效果 |
这四个 Barrier 只是 Java 为了跨平台而设计出来的,实际上根据 CPU 的不同,对应 CPU 平台上的 JVM 可能会优化掉一些 Barrier。比如在 x86 平台的JVM上只剩下一个 StoreLoad Barrier被使用。

volatile有不稳定的意思,在Java中。volatile关键字用于修饰没有final关键字修饰的实例变量或静态变量,这些变量一般是共享可变的,即一个变量可能被多个线程访问(读/写),值容易发生变化,因而不稳定。
volatile关键字的作用包括:保证可见性,保证有序性和保证long/double型变量读写操作的原子性
JMM针对编译器制定的volatile重排序规则表如下:

举例来说,第三行最后一个单元格的意思是:在程序中,当第一个操作为普通变量的读或写时,如果第二个操作为volatile写,则编译器不能重排序这两个操作。
在 JSR-133 Cookbook中提出几乎无法找到一个“最理想”位置,将内存屏障个数降到最小。因此JMM采取了保守策略,以保证在任意处理器平台,任意的程序都能得到正确的volatile语义。


上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变 volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障

大部分时候可以简化为下面的表:


由于x86处理器仅支持StoreLoad重排序,因此在x86处理器上Java虚拟机会将LoadLoad内存屏障,LoadStore内存屏障以及StoreStore内存屏障映射为空指令,也就是说只需要在volatile写操作后插入一个StoreLoad内存屏障,其它的都不用管。
在设计模式——单例模式(Singleton Pattern)这篇文章中,深入讲解了各种单例模式,其中Double Check Lock单例模式有一个问题
public class Singleton {
private volatile static Singleton singleton = null;
private Singleton(){
}
public static Singleton getInstance(){
if (singleton == null){
synchronized (Singleton.class){
if (singleton == null){
singleton = new Singleton();
}
}
}
return singleton;
}
}
在Java中,singleton = new Singleton();这个操作会分解为以下伪代码所示的几个独立子操作:
其中volatile关键字 仅保障子操作3是一个原子操作,但是由于子操作1和子操作2仅涉及局部变量而未涉及共享变量,因此对变量singleton的赋值操作仍可以看作是一个原子操作。
由于volatile能够禁止volatile变量写操作与该操作之前的任何读,写操作进行重排序,因此,用volatile修饰singleton相当于禁止JIT编译器以及处理器将子操作2,3进行重排序,这就保障了一个线程读取到singleton变量所引用的实例时该实例已经初始化完成。
通过javac Singleton.java将类编译为class文件,再通过javap -v -p Singleton.class命令反编译查看字节码文件。-p的作用是显示所有类与成员
D:\JavaSE\JavaProject\design-pattern\src\main\java>javap -p -v Singleton.class
Classfile /D:/JavaSE/JavaProject/design-pattern/src/main/java/Singleton.class
Last modified 2021-4-19; size 509 bytes
MD5 checksum fc6fcd094d2d9cdf0edd20d59c6b0d22
Compiled from "Singleton.java"
public class Singleton
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #5.#20 // java/lang/Object."<init>":()V
#2 = Fieldref #3.#21 // Singleton.singleton:LSingleton;
#3 = Class #22 // Singleton
#4 = Methodref #3.#20 // Singleton."<init>":()V
#5 = Class #23 // java/lang/Object
#6 = Utf8 singleton
#7 = Utf8 LSingleton;
#8 = Utf8 <init>
#9 = Utf8 ()V
#10 = Utf8 Code
#11 = Utf8 LineNumberTable
#12 = Utf8 getInstance
#13 = Utf8 ()LSingleton;
#14 = Utf8 StackMapTable
#15 = Class #23 // java/lang/Object
#16 = Class #24 // java/lang/Throwable
#17 = Utf8 <clinit>
#18 = Utf8 SourceFile
#19 = Utf8 Singleton.java
#20 = NameAndType #8:#9 // "<init>":()V
#21 = NameAndType #6:#7 // singleton:LSingleton;
#22 = Utf8 Singleton
#23 = Utf8 java/lang/Object
#24 = Utf8 java/lang/Throwable
{
private static volatile Singleton singleton;
descriptor: LSingleton;
flags: ACC_PRIVATE, ACC_STATIC, ACC_VOLATILE
private Singleton();
descriptor: ()V
flags: ACC_PRIVATE
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
line 5: 4
public static Singleton getInstance();
descriptor: ()LSingleton;
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=0
0: getstatic #2 // Field singleton:LSingleton;
3: ifnonnull 37
6: ldc #3 // class Singleton
8: dup
9: astore_0
10: monitorenter
11: getstatic #2 // Field singleton:LSingleton;
14: ifnonnull 27
17: new #3 // class Singleton
20: dup
21: invokespecial #4 // Method "<init>":()V
24: putstatic #2 // Field singleton:LSingleton;
27: aload_0
28: monitorexit
29: goto 37
32: astore_1
33: aload_0
34: monitorexit
35: aload_1
36: athrow
37: getstatic #2 // Field singleton:LSingleton;
40: areturn
Exception table:
from to target type
11 29 32 any
32 35 32 any
LineNumberTable:
line 7: 0
line 8: 6
line 9: 11
line 10: 17
line 12: 27
line 14: 37
StackMapTable: number_of_entries = 3
frame_type = 252 /* append */
offset_delta = 27
locals = [ class java/lang/Object ]
frame_type = 68 /* same_locals_1_stack_item */
stack = [ class java/lang/Throwable ]
frame_type = 250 /* chop */
offset_delta = 4
static {};
descriptor: ()V
flags: ACC_STATIC
Code:
stack=1, locals=0, args_size=0
0: aconst_null
1: putstatic #2 // Field singleton:LSingleton;
4: return
LineNumberTable:
line 2: 0
}
SourceFile: "Singleton.java"

volatile在字节码层面,就是使用访问标志:ACC_VOLATILE来表示,供后续操作此变量时判断访问标志是否为ACC_VOLATILE,来决定是否遵循volatile的语义处理。
下面看一下getInstance()方法的字节码:

下面简单介绍黄框里面的四个字节码指令:
objRef = allocate(Singleton.class)。<init>方法,对对象进行初始化,这时一个真正可用的对象才算真正被构造出来。即完成invokespecial(objRef)。singleton赋值为objRef,即完成singleton = objRef。这里的细节比较多,如果读者对这块不了解,读一下深入理解Java虚拟机的相关内容。
其实从字节码层面,看到的东西很有限,无法看到volatile变量具体怎么起作用的。那我们从hotspot源码看一下发生了什么?
看一下bytecodeInterpreter.cpp中的代码片段(其实这个解释器很少用到,大部分平台用模板解释器,通过JIT编译器执行的差异更大,但是看一下运行过程还是没问题的),这儿简单看看领会那个意思就行,cpp代码也看不太懂
在openjdk8根路径/hotspot/src/share/vm/interpreter路径下的bytecodeInterpreter.cpp文件中,处理putstatic和putfield指令的代码:
CASE(_putfield):
CASE(_putstatic):
......
//
// Now store the result
//
int field_offset = cache->f2_as_index();
if (cache->is_volatile()) {
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {
VERIFY_OOP(STACK_OBJECT(-1));
obj->release_obj_field_put(field_offset, STACK_OBJECT(-1));
}
......
OrderAccess::storeload();
}
//在windows_x86上的具体实现
inline void OrderAccess::loadload() { acquire(); }
inline void OrderAccess::storestore() { release(); }
inline void OrderAccess::loadstore() { acquire(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() {
#ifndef AMD64
__asm {
mov eax, dword ptr [esp];
}
#endif // !AMD64
}
inline void OrderAccess::release() {
//避免不同的线程击中相同的缓存行
volatile jint local_dummy = 0;
}
inline void OrderAccess::fence() {
#ifdef AMD64
StubRoutines_fence();
#else
if (os::is_MP()) {
__asm {
// 使用lock指令是因为mfence的代价比较昂贵
// always use locke since mfence is sometimes expensive
lock add dword ptr [esp], 0;
}
}
#endif // AMD64
}
通过上面的代码可以大体看出,如果发现某个变量是is_volatile(),进行putstatic操作后,会加上storeLoad屏障,且只有fence()里面的内嵌汇编指令加上了lock指令,即在x86处理器上只有StoreLoad屏障有真正内存屏障的功能。使用lock而不用mfence是因为mfence的开销比较大,在源码的注释中也有体现。
在Intel? 64 and IA-32 Architectures Software Developer’s Manual 中给出LOCK指令的详细解释

可以看到在赋值操作(putstatic)后执行了一个lock add dword ptr [rsp], 0;,这一句会清空Store Buffer,将数据写入高速缓存(或者内存),同时通过缓存一致性协议让其它CPU相关缓存行失效,起到了StoreLoad的作用。从而使该指令前面对数据的更新能被其他处理器看到,进而保证了可见性。

public class VolatileAtomicSample {
private volatile static int counter = 0;
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
counter++;
}
});
thread.start();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("结果为" + counter);
}
}

可以看到,理想的结果应该是10000,但是结果为9368。在Java语言规范中,volatile关键字对原子性的保障仅限于共享变量写和读操作本身。对共享变量进行的赋值操作往往是一个复合操作,volatile并不能保障这些赋值操作的原子性。例如上面代码中的i++,它等价于i=i+1;而i是多个线程间的共享变量,那一条语句就可以分解为如下的几个子操作:
r1 = i; //将共享变量i的值加载到寄存器r1r2=r2+1;//将寄存器r1的值加1i=r2;//将寄存器r1的值写入共享变量i(内存/缓存) 
正如上面三行汇编代码
mov r8d,dword ptr [r10+68h] //把内存地址[r10+68h]中的双字型(dword 32位)数据赋给r8d寄存器inc r8d //inc加1操作mov dword ptr [r10+68h] , r8d //把r8d寄存器中的数据赋给内存地址[r10+68h]中的双字型( 32位)数据volatile关键字并不像锁那样具有排他性,在写操作方面,其对原子性的保障也仅仅作用于上述的子操作3.因此,当一个线程在执行到子操作3的时候,其他线程可能已经更新了共享变量i的值,这样就使得子操作3的执行线程实际上是向共享变量i写入了一个旧值。比如下图,进行两次加1操作,但最终写入内存的结果最终还是1。

先说结论,如果被修饰的变量是个数组,那么volatile关键字只能够对数组引用本身的操作(读取数组引用和更新数组引用)起作用,而无法对数组元素的操作(读取。更新数组元素)起作用。
比如int i = anArray[0];,可以分解为两个子步骤
而anArray=new int[10];是改变anArray的地址,会触发volatile关键字的作用。
在上图中,只有修改arr的地址才会生成lock前缀指令,从另一个方面验证了上面的结论。如果要使对数组元素的读,写也能触发volatile关键字的作用,那么可以用AtomicIntegerArray,AtomicIongArray,AtomicReferenceArray。
[1]周志明.深入理解Java虚拟机(第3版).机械工业出版社,2019.
[2] 黄文海. Java多线程编程实战指南(核心篇).电子工业出版社,2017.
[2] 程晓明. 深入理解Java内存模型.InfoQ软件开发丛书,2018.

本文将研究 ES6 的 for ... of 循环。 旧方法 在过去,有两种方法可以遍历 javas...
ADO对象: Connection Command Recordset Record Stream ASP支持的对象很多,可...
前言 相信大家都知道在IDE中代码的智能提示几乎都是标配,虽然一些文本编辑器也...
vbs:把一段文字中指定字符颜色变成红色的正则 functionc(Tstr,Word) Dimre Setre...
一石激起千层浪,继中国区浩浩荡荡的大裁员告一段落之后,甲骨文并未因此收起手...
一、正则表达式概述 二、正则表达式在VBScript中的应用 三、正则表达式在VavaScr...
【排序算法】之lowb三人组冒泡、插入、选择 什么是lowb三人组 冒泡排序bubble so...
微信文件传输助手是微信电脑版与手机微信之间相互传输图片等文件的好工具,但很...
计算属性computed: 支持缓存,只有依赖数据发生改变,才会重新进行计算 不支持...
歌词编辑器 歌词编辑器 第一步:选择要播放的歌曲并播放 第二步:填写全部的歌词...


