

基于参数服务器架构的大规模稀疏训练,可以说好几年没有新的变化和进步了,直到百度的aibox论文出现,以及后来nvidia开发的hugectr开源出来。总算是看到参数服务器架构又朝前走了一步。可以预见的是,这样的异构训练架构,相比之前的纯CPU的方式,一定会随着更多的高性能硬件、新的训练优化的出现,有更进一步的改进空间。希望大家看到后有什么问题可以留言讨论,一起进步。
相关的代码库链接:https://github.com/NVIDIA/HugeCTR/
hugectr是nvidia开发的GPU分布式训练框架,它主要针对的是推荐ctr场景,支持大规模稀疏参数的分布式训练与评估。
hugectr是一个基于参数服务器架构的训练框架,它的主要亮点在于,它有基于GPU显存的参数服务器(通俗一点说就是GPU显存里有个hashmap用来存参数),这样在做GPU训练的时候,参数可以直接从GPU拷贝或者利用GPU通信,大大加速了参数通信(pull和push),因为参数通信不再经过CPU了。
当然这也抛出了几个问题,不妨先思考一下:
(1)我们知道hashmap通常在大小接近一定阈值的时候,会做rehash的操作,而对参数服务器来说,随着不断训练,参数服务器存的参数也可能不断增多,尤其是训练刚开始的阶段,hashmap大小增长较快,如果频繁rehash或者创建新的key,那么就会存在频繁的GPU显存申请释放和拷贝,会很影响性能。
(2)GPU多了一步数据从CPU拷贝到GPU的过程,如果不做什么改进,计算的加速是否一定相比额外的数据拷贝要快呢?
(3)大规模稀疏参数,我们key的规模在十亿,value(即embedding向量)假如是32维float向量,假如我们使用的是adam优化器,那么算上优化器状态就是32 * 3 = 96维,总的参数规模大于300G,全放在显存里放得下吗?
这些问题在后面看的过程中会逐步解答,接下来让我们先看一下整体架构。

训练流程:首先reader从dataset中读取batch_size(比如32)的原始数据,解析原始数据,得到输入的sparse key,dense向量,label等,并根据sparse key从参数服务器(下文简称ps,即parameter server)中拉取(pull)对应的embedding向量,然后输入到深度学习神经网络中做前向-反向计算,并把反向计算得到的参数梯度推送(push)到ps,由ps根据梯度更新参数。
训练的过程可以认为是数据并行+模型并行。数据并行主要体现在每个GPU卡的同时读取不同的数据做训练,而模型训练主要体现在sparse参数的存储是存储在多个节点(node)上,每个节点分配一部分参数。
我们知道,ctr场景中,sparse参数的规模通常很大,从千万到万亿级别的大小,dense参数(网络中的权重)通常很小,占用内存大小也就几MB到几十MB。因此对sparse参数的存取需要好好设计。hugectr中对sparse的存储方式有两种:local和distribute。
让我们先看看local模式:一个slot的参数,只会在一个gpu卡上,这样查完embedding之后,因为已经拿到了这个slot的所有embedding,可以做完pooling之后再做GPU多卡通信,可以降低通信量。(这里slot的意思是特征种类,也可以称作field)

举个例子,我们是单机训练有4张GPU卡,有8个slot:slot0到slot7。如果是local模式,那么就是GPU0存slot0和slot1,GPU1存slot2和slot3,GPU2存slot4和slot5,GPU3存slot6和slot7。
对于distribute模式,每个GPU上上都会存所有slot的一部分参数,至于如何将一个参数分配到哪个GPU上,可以通过哈希的方法。
下图是从多线程数据读取、数据从CPU拷贝到GPU、训练的过程,图里的worker,其实指的就是reader,多个reader同时解析dataset的数据,然后由collector模块将数据拷贝到GPU。图里的worker、collector、training这三个是通过流水线串起来,各个部分相互独立,同时在不同的线程中运行。

下图就是流水线的具体示例,每种颜色代表一级流水线,共三级流水线。当第一级解析完batch0后,扔给第二级用来拷贝给GPU,这时候第一级继续解析batch1。当batch0在训练的时候,同时在做的是batch1拷贝到GPU。

需要注意的是,上图各级流水线的时间默认是相等的,但是实际情况一般不会这么巧,那么一般是需要灵活调整各级流水线的线程数的,让各级流水线的速度匹配起来。举个例子比如,readfile开10个线程,copy开5个线程,训练开8个线程。另外,上面实际是纵向在看流水线,如果横向来看,是各个batch互相独立的在做readfile-copy-train。
有没有发现,这里的流水线解答了开头的第2个问题。
我看代码喜欢自顶向下的看,这样不仅能开始就能掌握运行的整个流程,后面看细节的时候也可以有针对性得看。另外,我没有弄太多子标题,顺序往下看就好。
我们首先看readme中的例子,这是一个调用了python api的例子。hugectr与常见的深度学习框架一样,分为python端和c++端,python封装user api,c++实现底层训练逻辑。
# train.py
import sys
import hugectr
from mpi4py import MPI
def train(json_config_file):
solver_config = hugectr.solver_parser_helper(batchsize = 16384,
batchsize_eval = 16384,
vvgpu = [[0,1,2,3,4,5,6,7]],
repeat_dataset = True)
sess = hugectr.Session(solver_config, json_config_file)
sess.start_data_reading()
for i in range(10000):
sess.train()
if (i % 100 == 0):
loss = sess.get_current_loss()
print("[HUGECTR][INFO] iter: {}; loss: {}".format(i, loss))
if __name__ == "__main__":
json_config_file = sys.argv[1]
train(json_config_file)
另外,观察这里的api会发现,长得跟tensorflow单机的api是不是很像,确实分布式框架的一个目标就是用起来像写单机程序一样顺手,也就是所谓的“易用性”。
这里的solver_config就是把各种训练配置传入hugectr,session就是封装了分布式训练逻辑,start_data_reading就是字面意思,启动上文的readfile的异步线程,也就是第一级流水线。接着就是train,然后打印oss。
前面说过,自顶向下看代码的好处是可以对细节有针对性,那咱们先看重点,也就是sess.train。
python端与c++端的连接,可以使用pybind库。连接的“桥梁”定义在pybind/session_wrapper.hpp这个文件里:
void SessionPybind(pybind11::module &m) {
pybind11::class_<HugeCTR::Session, std::shared_ptr<HugeCTR::Session>>(m, "Session")
.def(pybind11::init<const SolverParser &, const std::string &, bool, const std::string>(),
pybind11::arg("solver_config"), pybind11::arg("config_file"),
pybind11::arg("use_model_oversubscriber") = false,
pybind11::arg("temp_embedding_dir") = std::string())
.def("train", &HugeCTR::Session::train)
.def("eval", &HugeCTR::Session::eval)
.def("start_data_reading", &HugeCTR::Session::start_data_reading)
....
在python调用sess.train,对应了c++的HugeCTR::Session::train,让我们来看一下这个函数,我加了一些注释:
bool Session::train() {
// 判断reader是否启动,未启动就开始训练则报错
if (train_data_reader_->is_started() == false) {
CK_THROW_(xxxx);
}
// 等待reader读取至少一个batchsize的数据
long long current_batchsize = 0;
while ((current_batchsize = train_data_reader_->read_a_batch_to_device_delay_release()) &&
(current_batchsize < train_data_reader_->get_full_batchsize())) {
// 告诉reader可以开始解析数据了,通过设置flag:READY_TO_WRITE
train_data_reader_->ready_to_collect();
}
// 读不到数据了,即没有数据可以训练了,直接返回
if (!current_batchsize) {
return false;
}
// reader解析完一个batch的数据后,flag会被设置为READY_TO_READ
// 上面通过read_a_batch_to_device_delay_release把数据已经从reader中取出来,
// 并且正在异步的拷贝到GPU,
// 调用ready_to_collect,首先sync上面的异步拷贝,然后让reader继续解析下一个batch
train_data_reader_->ready_to_collect();
// 从ps查embedding,做sum或者avg
for (auto& one_embedding : embeddings_) {
one_embedding->forward(true);
}
// 这里的逻辑看着有点乱,也就是多卡数据并行训练,
// 一个网络有gpu卡数个副本,也就是networks大小大于1的原因。
if (networks_.size() > 1) {
// 单机多卡或多机多卡
// execute dense forward and backward with multi-cpu threads
#pragma omp parallel num_threads(networks_.size())
{
// dense网络的前向反向
size_t id = omp_get_thread_num();
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(id);
networks_[id]->train(current_batchsize_per_device);
// 多卡之间交换dense参数的梯度
networks_[id]->exchange_wgrad();
// 更新dense参数
networks_[id]->update_params();
}
} else if (resource_manager_->get_global_gpu_count() > 1) {
// 多机单卡
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(0);
networks_[0]->train(current_batchsize_per_device);
networks_[0]->exchange_wgrad();
networks_[0]->update_params();
} else {
// 单机单卡
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(0);
networks_[0]->train(current_batchsize_per_device);
networks_[0]->update_params();
}
// embedding的反向
for (auto& one_embedding : embeddings_) {
one_embedding->backward();
// 更新sparse参数
one_embedding->update_params();
}
return true;
}
看到这里,基本上训练中的大体流程是清楚了。接下来,我们继续深入往下看reader、embedding、参数存储和通信等部分。首先有必要看一下初始化。
HugeCTR::Session的初始化代码如下:
parser.create_pipeline(
train_data_reader_, evaluate_data_reader_,
embeddings_, networks_, resource_manager_);
#pragma omp parallel num_threads(networks_.size())
{
size_t id = omp_get_thread_num();
networks_[id]->initialize();
if (solver_config.use_algorithm_search) {
networks_[id]->search_algorithm();
}
CK_CUDA_THROW_(cudaStreamSynchronize(
resource_manager_->get_local_gpu(id)->get_stream()));
}
init_or_load_params_for_dense_(solver_config.model_file);
init_or_load_params_for_sparse_(solver_config.embedding_files);
load_opt_states_for_sparse_(solver_config.sparse_opt_states_files);
load_opt_states_for_dense_(solver_config.dense_opt_states_file);
也就是分为以下步骤:
(1)创建三级流水线,即create_pipeline
(2)初始化network
(3)初始化参数,以及对应的优化器状态
这里面比较重要的部分是创建三级流水线,我们看一下create_pipeline的实现(函数传参先忽略掉):
// create reader
create_datareader<TypeKey>()(...);
// create embedding
for (unsigned int i = 1; i < j_layers_array.size(); i++) {
// 网路配置的每层是从bottom到top的,因此只要遇到非embedding的layer,
// 后面的layer就不用检查了
const nlohmann::json& j = j_layers_array[i];
auto embedding_name = get_value_from_json<std::string>(j, "type");
Embedding_t embedding_type;
if (!find_item_in_map(embedding_type, embedding_name, EMBEDDING_TYPE_MAP)) {
break;
}
create_embedding<TypeKey, float>()(...);
}
// create network,每张GPU卡创建一个network副本
for (size_t i = 0; i < resource_manager->get_local_gpu_count(); i++) {
network.emplace_back(Network::create_network(...));
}
可以看到create_pipeline主要包含了三步:create_datareader、create_embedding、create_network
我们接下来先看create_datareader里面做了什么:创建了一个train_data_reader和一个evaluate_data_reader,也就是一个用于训练,一个用于评估。然后还各自创建了WorkerGroup。
DataReader<TypeKey>* data_reader_tk = new DataReader<TypeKey>(...);
train_data_reader.reset(data_reader_tk);
DataReader<TypeKey>* data_reader_eval_tk = new DataReader<TypeKey>(...);
evaluate_data_reader.reset(data_reader_eval_tk);
train_data_reader->create_drwg_norm(source_data, check_type, repeat_dataset_);
evaluate_data_reader->create_drwg_norm(eval_source, check_type, repeat_dataset_);
void create_drwg_norm(std::string file_name, Check_t check_type,
bool start_reading_from_beginning = true) override {
source_type_ = SourceType_t::FileList;
worker_group_.reset(new DataReaderWorkerGroupNorm<TypeKey>(
csr_heap_, file_name, repeat_, check_type, params_, start_reading_from_beginning));
file_name_ = file_name;
}
// DataReaderWorkerGroupNorm的构造函数主要是如下功能,创建DataReaderWorker
for (int i = 0; i < NumThreads; i++) {
std::shared_ptr<IDataReaderWorker> data_reader(new DataReaderWorker<TypeKey>(
i, NumThreads, csr_heap, file_list, max_feature_num_per_sample, repeat, check_type, params));
data_readers_.push_back(data_reader);
}
// 然后创建了多个线程。每个线程对应一个reader,执行如下逻辑
while (*p_loop_flag) {
data_reader->read_a_batch();
}
好了,看到这里,出现了两个类DataReader和DataReaderWorkerGroupNorm,这两个类有必要看一下细节,从而弄清楚数据读取。
先看DataReader里的重要的函数和变量:
template <typename TypeKey>
class DataReader : public IDataReader {
std::shared_ptr<HeapEx<CSRChunk<TypeKey>>> csr_heap_;
std::shared_ptr<DataCollector<TypeKey>> data_collector_;
std::shared_ptr<DataReaderWorkerGroup> worker_group_;
//还有各种tensor:label_tensors_、dense_tensors_、row_offsets_tensors_、value_tensors_等
DataReader(...) {
// 初始化heap,这个类后面介绍
csr_heap_.reset(new HeapEx<CSRChunk<TypeKey>>(...));
// 为每个GPU初始化一个buffer
std::vector<std::shared_ptr<GeneralBuffer2<CudaAllocator>>> buffs;
for (size_t i = 0; i < local_gpu_count; i++) {
buffs.push_back(GeneralBuffer2<CudaAllocator>::create());
}
// create label and dense tensor
size_t batch_size_per_device = batchsize_ / total_gpu_count;
for (size_t i = 0; i < local_gpu_count; i++) {
// Tensor2并不持有内存或者显存,是在buffs里
{
Tensor2<float> tensor;
buffs[i]->reserve({batch_size_per_device, label_dim_}, &tensor);
label_tensors_.push_back(tensor);
}
{
Tensor2<float> tensor;
buffs[i]->reserve({batch_size_per_device, dense_dim_}, &tensor);
dense_tensors_.push_back(tensor.shrink());
}
}
...
// 这里又出现一个DataCollector类
data_collector_.reset(new DataCollector<TypeKey>(...);
data_collector_->start();
// buffs在每个GPU上分配显存
for (size_t i = 0; i < local_gpu_count; i++) {
CudaDeviceContext context(resource_manager_->get_local_gpu(i)->get_device_id());
buffs[i]->allocate();
}
}
详细介绍一下上面出现的类:
(1)CSR:一种用来压缩稀疏矩阵的存储格式,例子如下
假如有这样一组数据
* 4,5,1,2
* 3,5,1
* 3,2
用CSR可以表示为
row offset: 0,4,7,9
value: 4,5,1,2,3,5,1,3,2
这里的CSR由于是用来存储slot里的sparse key,其实少了column index,因为一个slot里的sparse key直接顺序存就好了,CSR可以参考这篇文章。总是令人想起百度paddle的lodtensor。
(2)HeapEx:为每个数据解析的线程维护了三个队列,ready queue 、 wait queue 和 credit queue,队列中的元素就是CSR存储。当credit queue非空,意味着有空闲的CSR可以用来存储解析好的数据。
(3)DataReaderWorker:就是上面的解析数据线程。
(4)DataCollector:就是上面的读数据线程。把数据从CSR拷贝到GPU。它会启动一个线程不断的执行如下函数:
template <typename TypeKey>
void DataCollector<TypeKey>::collect_() {
std::unique_lock<std::mutex> lock(stat_mtx_);
CSRChunk<TypeKey>* chunk_tmp = csr_heap_->checkout_data_chunk();
while (stat_ != READY_TO_WRITE && stat_ != STOP) {
usleep(2);
}
...
cudaMemcpyAsync 做拷贝
...
cudaStreamSynchronize
...
csr_heap_->return_free_chunk();
stat_ = READY_TO_READ;
这里checkout_data_chunk从一个队列里取出一个CSR,拷贝完成后再调用return_free_chunk归还。
为了清晰一点表示流程,我画了个简易的图,绿色的线是数据生产消费,红色是数据归还。data reader worker获取到空闲的CSR就解析数据填进去,并放到ready queue中,而data collector发现有可用的CSR,就拷贝到GPU中,然后归还CSR。可以说,data reader worker和data collector是相互独立的,两者通过存放数据的队列联系起来。

还有一些细节值得注意:
(1)hugectr还实现了两外两种data reader worker,一种是DataReaderWorkerRaw,它读取的数据是通过mmap直接映射到内存。还有一种是DataReaderWorkerGroup,读取parquet格式的文件。
(2)data reader worker解析数据放到CSR的细节:
// 返回的是get_batchsize训练配置的batch size
for (i = 0; i < csr_chunk->get_batchsize(); i++) {
// dense输入
{
// label_dense_buffers的大小是当前节点的gpu卡数
// buffer_id就是这条样本落在哪张卡上
int buffer_id = i / (csr_chunk->get_batchsize() / label_dense_buffers.size());
// local_id是这条样本在当前卡上的偏移
int local_id = i % (csr_chunk->get_batchsize() / label_dense_buffers.size());
// 拷贝,从解析数据的buffer拷贝到CSR里
float* ptr = label_dense_buffers[buffer_id].get_ptr();
for (int j = 0; j < label_dense_dim; j++) {
ptr[local_id * label_dense_dim + j] = label_dense[j]; // row major for label buffer
}
}
// sparse输入
for (auto& param : params_) {
for (int k = 0; k < param.slot_num; k++) {
// 省略了读取数据
...
// 下面这段代码,对理解embedding的两种存储方式很有帮助
if (param.type == DataReaderSparse_t::Distributed) {
// 所有节点的每张卡上都会存所有slot
for (int dev_id = 0; dev_id < csr_chunk->get_num_devices(); dev_id++) {
csr_chunk->get_csr_buffer(param_id, dev_id).new_row();
}
// 这里就是判断slot的key应该存在哪张卡上
for (int j = 0; j < nnz; j++) {
int dev_id = feature_ids_[j] % csr_chunk->get_num_devices();
dev_id = std::abs(dev_id);
T local_id = feature_ids_[j];
csr_chunk->get_csr_buffer(param_id, dev_id).push_back(local_id);
}
} else if (param.type == DataReaderSparse_t::Localized) {
// 一个slot只会存在一张卡上
int dev_id = k % csr_chunk->get_num_devices();
csr_chunk->get_csr_buffer(param_id, dev_id).new_row();
for (int j = 0; j < nnz; j++) {
T local_id = feature_ids_[j];
csr_chunk->get_csr_buffer(param_id, dev_id).push_back(local_id);
}
}
}
}
}
(3)data collector拷贝数据的细节:
// total_device_count 所有节点的gpu之和
for (int ix = 0; ix < total_device_count; ix++) {
int i =
((id_ == 0 && !reverse_) || (id_ == 1 && reverse_)) ? ix : (total_device_count - 1 - ix);
int pid = resource_manager_->get_process_id_from_gpu_global_id(i);
int label_copy_num = (label_dense_buffers[0]).get_num_elements();
if (pid == resource_manager_->get_process_id()) {
...
for (int j = 0; j < num_params; j++) {
// 这里的i * num_params + j取的就是全局的偏移
unsigned int nnz = csr_cpu_buffers[i * num_params + j]
.get_row_offset_tensor()
.get_ptr()[csr_cpu_buffers[i * num_params + j].get_num_rows()];
// cudaMemcpyAsync 异步拷贝
}
我们发现:所有的节点都会解析所有的数据!在拷贝的时候,才会只拷贝出属于本节点的数据。这种实现,对于大数据量来说,性能是很值得怀疑的,带宽可能不够,并且会解析大量无用的数据。
一方面数据拷贝的时候会只保留属于本gpu的sparse key,另一方面本gpu中也只会存储属于本节点的sparse key,那么也就是说sparse pull和push的时候就不需要做节点间的通信了。当然后续还是需要做节点间通信,把数据拼成完整的batch做前向反向计算,得到梯度后做节点间的梯度平均。这块会在create embedding处详细展开。
实际上面的data reader worker 与 data collector就是本文开头的图里的第一、二级流水线了。接下来我们再看一下创建第三级流水线中的create_embedding部分。
创建embedding初始化,我们应该最关注的是如何存参数。在此之前,我们看看网络配置,看看是咋组织embedding的, 这里就以deepfm为例,首先看一下输入层
"dense": {
"top": "dense",
"dense_dim": 13
},
"sparse": [
{
"top": "data1",
"type": "DistributedSlot",
"max_feature_num_per_sample": 30,
"slot_num": 26
}
]
dense输入是deepfm的fm输入。sparse是deepfm的deep输入,包含了26个slot。再看embedding层的定义,max_vocabulary_size_per_gpu是一个gpu卡上的最大sparse key的个数,embedding_vec_size就是embedding向量维度,combiner表示查完embedding做pooling是sum还是avg。
{
"name": "sparse_embedding1",
"type": "DistributedSlotSparseEmbeddingHash",
"bottom": "data1",
"top": "sparse_embedding1",
"sparse_embedding_hparam": {
"max_vocabulary_size_per_gpu": 1447751,
"embedding_vec_size": 11,
"combiner": 0
}
}
hugectr有两种embedding:DistributedSlotSparseEmbeddingHash和 LocalizedSlotSparseEmbeddingHash。我们一个一个看。
大致扫一眼hashmap创建的代码,两者是一样的:
// 注意到hash table的value type是个size_t,这个是记录了embedding在存储中的偏移量
using NvHashTable = HashTable<TypeHashKey, size_t>;
// 这个是hashmap的定义,发现外面套了个vector,需要弄清楚vector每个元素是啥
std::vector<std::shared_ptr<NvHashTable>> hash_tables_;
// 原来vector大小是本地gpu数,也就是说每个gpu卡对应一个hash table
hash_tables_.resize(Base::get_resource_manager().get_local_gpu_count());
// 事先就固定了hash table容纳元素的最大数量为max_vocabulary_size_per_gpu_
#pragma omp parallel num_threads(Base::get_resource_manager().get_local_gpu_count())
{
size_t id = omp_get_thread_num();
CudaDeviceContext context(Base::get_local_gpu(id).get_device_id());
// construct HashTable object: used to store hash table <key, value_index>
hash_tables_[id].reset(new NvHashTable(max_vocabulary_size_per_gpu_));
Base::get_buffer(id)->allocate();
}
这里可以解答开头的第一个问题了,答案很简单粗暴,就是事先固定了哈希表的大小。
这样其实对于大规模稀疏来说,支持的参数规模不会很大,就像开头第三个问题算过的亿级别就得300G。因此hugectr支持的参数规模会因为这样的设计,而受到比较大的限制。
那是不是第三个问题无解了呢,其实不然,百度的aibox不存在的这样的限制,因为它采用了多级ps(ssd+mem+gpu),并且gpu ps的大小会随着当前训练的增量数据的key的多少而动态创建不同大小的hashmap。这里aibox暂时先不展开了,我后面会写一篇文章专门介绍它的论文。:)
继续看一下HashTable这个类
template <typename KeyType, typename ValType>
class HashTable {
// 查找key,如果key不在table里就insert
void get_insert(const KeyType* d_keys, ValType* d_vals, size_t len, cudaStream_t stream);
// 查找key
void get(const KeyType* d_keys, ValType* d_vals, size_t len, cudaStream_t stream) const;
// 把table里的kv都dump出来
void dump(KeyType* d_key, ValType* d_val, size_t* d_dump_counter, cudaStream_t stream) const;
HashTableContainer<KeyType, ValType>* container_
我们再看一下HashTableContainer,它是继承了concurrent_unordered_map这个类
template <typename KeyType, typename ValType>
class HashTableContainer
: public concurrent_unordered_map<KeyType, ValType, std::numeric_limits<KeyType>::max()> {
public:
HashTableContainer(size_t capacity)
: concurrent_unordered_map<KeyType, ValType, std::numeric_limits<KeyType>::max()>(
capacity, std::numeric_limits<ValType>::max()) {}
};
concurrent_unordered_map是固定大小的、在显存中的map,它支持并发insert,但是不支持并发insert和get。因为hugectr训练是同步的训练,pull的时候只会有get,push的时候只会有insert,并且不会同时做pull和push,因此这样的concurrent_unordered_map满足要求。
首先看一下它的get函数:
// __forceinline__ 强制指定为内联函数
// __host__ __device__ 这个函数会同时为主机端和设备端编译
__forceinline__ __host__ __device__ const_iterator find(const key_type& k) const {
// 对key做哈希
size_type key_hash = m_hf(k);
// 映射到table的一个index
size_type hash_tbl_idx = key_hash % m_hashtbl_size;
value_type* begin_ptr = 0;
size_type counter = 0;
while (0 == begin_ptr) {
value_type* tmp_ptr = m_hashtbl_values + hash_tbl_idx;
const key_type tmp_val = tmp_ptr->first;
// 找到了这个key
if (m_equal(k, tmp_val)) {
begin_ptr = tmp_ptr;
break;
}
// 这个位置是空的,或者找完了这个table也没找到
if (m_equal(unused_key, tmp_val) || counter > m_hashtbl_size) {
begin_ptr = m_hashtbl_values + m_hashtbl_size;
break;
}
hash_tbl_idx = (hash_tbl_idx + 1) % m_hashtbl_size;
++counter;
}
return const_iterator(m_hashtbl_values, m_hashtbl_values + m_hashtbl_size, begin_ptr);
}
可以看出,get一个key的时候,如果insert了这个key,可能还是get不到,或者get到的是错误的值(insert正在修改这个值的时候,get了这个值),或者旧的值。
再看一下insert,它的主要过程如下
const key_type insert_key = k;
bool insert_success = false;
size_type counter = 0;
while (false == insert_success) {
// 哈希表满了
if (counter++ >= hashtbl_size) {
return end();
}
key_type& existing_key = current_hash_bucket->first;
volatile mapped_type& existing_value = current_hash_bucket->second;
// existing_key == unused_key时,insert_key会被赋值给existing_key,因为这个位置是空的。
// existing_key == insert_key时,这个位置已经有这个key了,
// 如果这时候existing_value == m_unused_element,就说明其他线程正在insert且还没来得及修改existing_value
const key_type old_key = atomicCAS(&existing_key, unused_key, insert_key);
if (keys_equal(unused_key, old_key)) {
existing_value = (mapped_type)(atomicAdd(value_counter, 1));
break;
} else if (keys_equal(insert_key, old_key)) {
while (existing_value == m_unused_element) { }
break;
}
// 这个位置被其他key占了,继续往后遍历
current_index = (current_index + 1) % hashtbl_size;
current_hash_bucket = &(hashtbl_values[current_index]);
}
return iterator(m_hashtbl_values, m_hashtbl_values + hashtbl_size, current
atomicCAS函数参考这篇文章。
两种embedding:
(1)DistributedSlotSparseEmbeddingHash
void forward(bool is_train) override {
// Read data from input_buffers_ -> look up -> write to output_tensors
CudaDeviceContext context;
for (size_t i = 0; i < Base::get_resource_manager().get_local_gpu_count(); i++) {
context.set_device(Base::get_local_gpu(i).get_device_id());
functors_.forward_per_gpu(..., Base::get_local_gpu(i).get_stream());
}
// do reduce scatter
size_t recv_count = Base::get_batch_size_per_gpu(is_train) *
Base::get_slot_num() *
Base::get_embedding_vec_size();
functors_.reduce_scatter(recv_count, embedding_feature_tensors_,
Base::get_output_tensors(is_train), Base::get_resource_manager());
// scale for combiner=mean after reduction
if (Base::get_combiner() == 1) {
size_t send_count = Base::get_batch_size(is_train) * Base::get_slot_num() + 1;
functors_.all_reduce(send_count, Base::get_row_offsets_tensors(is_train),
row_offset_allreduce_tensors_, Base::get_resource_manager());
// do average
functors_.forward_scale(Base::get_batch_size(is_train), Base::get_slot_num(),
Base::get_embedding_vec_size(), row_offset_allreduce_tensors_,
Base::get_output_tensors(is_train), Base::get_resource_manager());
}
return;
}
我们先看forward,首先从当前gpu的hashmap做lookup,也就是functors_.forward_per_gpu,此时不需要做节点间通信,因为当前gpu对应的数据的key都在当前gpu。
接着做了reduce scatter,这个通信可以参考这篇官方文档
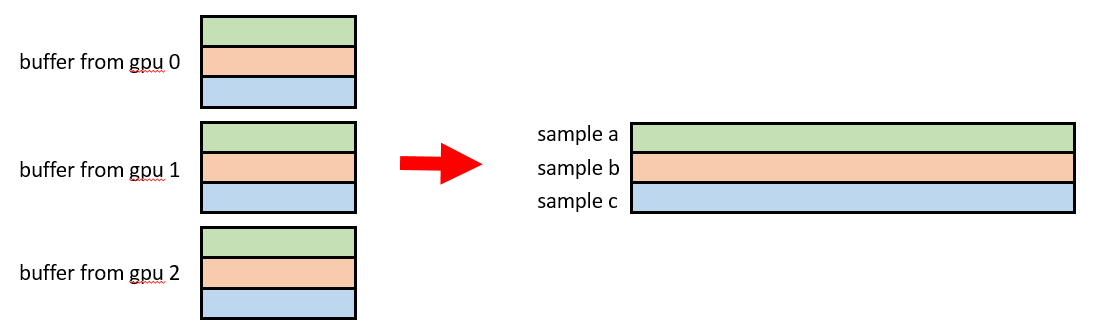
做完forward的时候,每个gpu的数据是batch size条,但是每条数据里的每个slot是一部分key。做完reduce scatter后,数据是完整的了,并且每个gpu上分到一部分完整的数据。
我们假设一共有2个gpu,batch size为2,一共3个slot,那么上面的过程如下:

如果是要做mean pooling,还需要做再做一次all reduce,拿到每个sample每个slot里的key的总个数(把csr里的offset求个allreduce,就可以得到全局offset了),然后把embedding的值除以这个个数,也就是求了平均。
再看一看backward
void backward() override {
// Read dgrad from output_tensors -> compute wgrad
// do all-gather to collect the top_grad
size_t send_count =
Base::get_batch_size_per_gpu(true) * Base::get_slot_num() * Base::get_embedding_vec_size();
functors_.all_gather(send_count, Base::get_output_tensors(true), embedding_feature_tensors_,
Base::get_resource_manager());
// do backward
functors_.backward(...);
return;
}
首先做all gather,每个gpu拿到当前batch所有样本的梯度,然后更新本地每个gpu上的参数。
void update_params() override {
#pragma omp parallel num_threads(Base::get_resource_manager().get_local_gpu_count())
{
size_t id = omp_get_thread_num();
CudaDeviceContext context(Base::get_local_gpu(id).get_device_id());
// accumulate times for adam optimizer
Base::get_opt_params(id).hyperparams.adam.times++;
// do update params operation
functors_.update_params(...);
}
return;
}
dump分为dump参数与dump优化器状态,两者代码比较类似,如下是dump参数:
// dump hash table from GPUs
for (size_t id = 0; id < local_gpu_count; id++) {
// dump key
hash_tables[id]->dump
// 拷贝到内存
cudaMemcpyAsync(...,cudaMemcpyDeviceToHost,...)
// dump value
functors_.get_hash_value
// 拷贝到内存
cudaMemcpyAsync(...,cudaMemcpyDeviceToHost,...)
}
functors_.sync_all_gpus(...)
for (size_t id = 0; id < local_gpu_count; id++) {
// 每个gpu上参数总大小
size_t size_in_B = count[id] * (sizeof(TypeHashKey) + sizeof(float) * embedding_vec_size);
// memcpy到file_buf
...
// rank0节点负责写文件
if (Base::get_resource_manager().is_master_process()) {
weight_stream.write(file_buf.get(), size_in_B);
} else {
// 其他节点把数据发给rank0节点
MPI_Send(file_buf.get(), size_in_B, ...);
}
}
// rank0节点收到数据
if (Base::get_resource_manager().is_master_process()) {
for (int r = 1; r < Base::get_resource_manager().get_num_process(); r++) {
for (size_t id = 0; id < local_gpu_count; id++) {
...
MPI_Recv(...);
weight_stream.write(file_buf.get(), size_in_B);
}
}
}
// 释放gpu显存
cudaFree
注意到dump的时候需要把参数和优化器状态都通过MPI_SEND发给一个节点,参数规模比较大时,0号节点就会成为瓶颈。不如每个节点dump自己的参数,还可以按分片组织参数。
load时候,每个节点都会加载所有模型文件,然后判断每个key是否属于自己:
TypeHashKey key = key_ptr[...];
size_t gid = key % global_gpu_count; // global GPU ID
int dst_rank = get_process_id_from_gpu_global_id(gid); // node id
if (my_rank == dst_rank) {
memcpy(...)
} else {
continue;
}
(2)LocalizedSlotSparseEmbeddingHash
void forward(bool is_train) override {
CudaDeviceContext context;
for (size_t i = 0; i < Base::get_resource_manager().get_local_gpu_count(); i++) {
context.set_device(Base::get_local_gpu(i).get_device_id()); // set device
functors_.forward_per_gpu(...);
}
functors_.all2all_forward(...);
// reorder:重新组织收到的数据buffer
functors_.forward_reorder(...);
// 保存每个sparse参数对应对的slot id
functors_.store_slot_id(...);
return;
}
all2all_forward的过程如下:

reorder的过程可以这样理解:
之所以要保存参数对应的slot id,是因为每个gpu上存不同的slot,加载的时候需要知道加载哪个slot的参数。
create_network主要是创建神经网络的各个层。
执行完前向反向后,首先多卡之间会平均梯度,然后再更新dense参数。
void Network::exchange_wgrad() {
CudaDeviceContext context(get_device_id());
ncclAllReduce((const void*)wgrad_tensor_.get_ptr(),
(void*)wgrad_tensor_.get_ptr(), wgrad_tensor_.get_num_elements(),
ncclFloat, ncclSum, gpu_resource_->get_nccl(),
pu_resource_->get_stream()));
}
说到这里,基本上整个训练流程应该是清楚了。这里再说一下混合精度训练,hugectr在官方介绍中的Highlighted features提到了混合精度训练。在hugectr中,embedding层的参数存储还是用的全精度float32。如果配置了使用mixed_precision,那么embedding层优化器状态用的是半精度fp16,其输出也为半精度fp16,并且其他dense支持fp16计算的层也会使用fp16计算。可以看这篇文章。
上面大致了解了hugectr之后,可以再运行一下hugectr官方代码库的例子。
看完代码后,这里小小的总结一下hugectr的优缺点:
优点:
缺点:

一、正则表达式概述 二、正则表达式在VBScript中的应用 三、正则表达式在VavaScr...
【排序算法】之lowb三人组冒泡、插入、选择 什么是lowb三人组 冒泡排序bubble so...
一石激起千层浪,继中国区浩浩荡荡的大裁员告一段落之后,甲骨文并未因此收起手...
前言 相信大家都知道在IDE中代码的智能提示几乎都是标配,虽然一些文本编辑器也...
本文将研究 ES6 的 for ... of 循环。 旧方法 在过去,有两种方法可以遍历 javas...
ADO对象: Connection Command Recordset Record Stream ASP支持的对象很多,可...
歌词编辑器 歌词编辑器 第一步:选择要播放的歌曲并播放 第二步:填写全部的歌词...
计算属性computed: 支持缓存,只有依赖数据发生改变,才会重新进行计算 不支持...
微信文件传输助手是微信电脑版与手机微信之间相互传输图片等文件的好工具,但很...
vbs:把一段文字中指定字符颜色变成红色的正则 functionc(Tstr,Word) Dimre Setre...

