


这是MaxCompute有关SQL优化器原理的系列文章之一。我们会陆续推出SQL优化器有关优化规则和框架的其他文章。
本文主要描述MaxCompute优化器实现的Auto Hash Join的功能。
简介
在MaxCompute中,Join操作符的实现算法之一名为"Hash Join",其实现原理是,把小表的数据全部读入内存中,并拷贝多份分发到大表数据所在机器,在 map 阶段直接扫描大表数据与内存中的小表数据进行匹配。Hash join执行方式效率很高,但是要求小表数据足够小以便放到内存中,假如小表数据太大,则任务在执行过程中会报OutOfMemory错误。
在MapCompute中,可以使用MapJoin关键字来实现Hash join,如下所示:

但是这种通过使用hint的方式还是不够智能。另外对于query复杂的情况,用户很可能因为无法确定join的某一路数据量大小而放弃使用mapjoin。在***的MaxCompute SQL 2.0中,基于代价的优化器(Cost Based Optimizer,CBO)包含了一个自动优化join为hash join的优化规则。
实现原理
在CBO中会对所有的operator的cost进行估计,这个cost包含rowcount、cpu、内存等等。有了各个operator的cost,就能估计其对应输出数据量的大小,公式可以简单的认为是:data_size = rowcount * averageRowSize。有了dataSize之后,就可以很容易知道这个任务是否适合使用HashJoin,其判定方法就是计算各个parent operator的data size之和是否小于某个阈值。假如估算出的data size在阈值范围之内,则会产生一个包含HashJoin的计划。同时对于Join,CBO也会产生一个普通的包含MergeJoin的计划,***在这两个计划中选择cost最小的作为***计划。
简单说来,在CBO中是否选择HashJoin作为***计划的步骤有两个:
举例,对如下sql进行优化:

上述sql在CBO中会翻译生成如下operator tree:
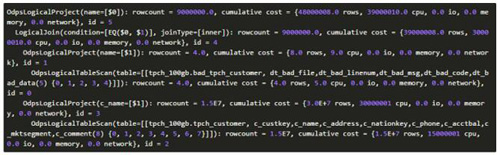
从上可以看到,join的parent operator有两个:

其中id为1的project其输出记录数是4行,且其输出列只有1列(bad_tpch_customer表中有5列),估算其输出数据量,认为其适合使用HashJoin,因此其产生的计划中包含两种:
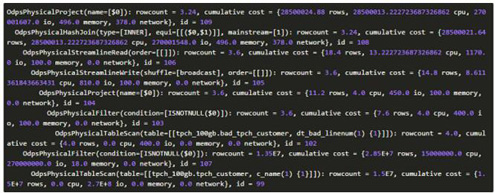
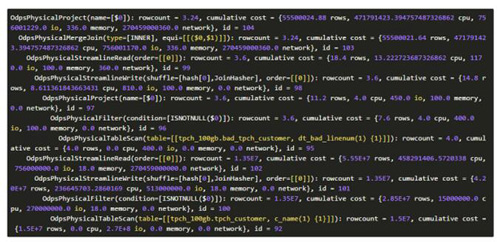
比较上述两个计划的cost,明显计划1的cost更小,因此选择包含HashJoin的计划1作为***计划。
总结
AutoHashJoin的一个很大的好处是能让用户免参与的进行这个优化,同时对于一些复杂的query也更有可能使用HashJoin。但是,因为CBO无法***估计数据量,会出现误判从而导致任务OOM的情况。针对这种情况,MaxCompute也进行了相应的调整,对于CBO误判导致HashJoin OOM的任务会关闭HashJoin rule来重试。
目前CBO中使用HashJoin的阈值比较保守,默认是25MB。主要原因是CBO对于数据量的估计有偏差,无法***估计数据量,而估计不准的原因有两个:
数据是压缩存储的,CBO拿到的statistics不准
CBO的估计算法有偏差
这两个问题也是CBO致力解决的问题。

计算属性computed: 支持缓存,只有依赖数据发生改变,才会重新进行计算 不支持...
vbs:把一段文字中指定字符颜色变成红色的正则 functionc(Tstr,Word) Dimre Setre...
ADO对象: Connection Command Recordset Record Stream ASP支持的对象很多,可...
一、正则表达式概述 二、正则表达式在VBScript中的应用 三、正则表达式在VavaScr...
一石激起千层浪,继中国区浩浩荡荡的大裁员告一段落之后,甲骨文并未因此收起手...
【排序算法】之lowb三人组冒泡、插入、选择 什么是lowb三人组 冒泡排序bubble so...
微信文件传输助手是微信电脑版与手机微信之间相互传输图片等文件的好工具,但很...
前言 相信大家都知道在IDE中代码的智能提示几乎都是标配,虽然一些文本编辑器也...
歌词编辑器 歌词编辑器 第一步:选择要播放的歌曲并播放 第二步:填写全部的歌词...
本文将研究 ES6 的 for ... of 循环。 旧方法 在过去,有两种方法可以遍历 javas...

