

本篇前言
C语言有各种各样的库函数,调用它们需要引用相应的头文件。由于C语言库函数较多,讲解原理的话涉及内容庞杂,作为替代这里给出C语言库函数(包括各种关键字)查询的网址供大家参考。有条件的小伙伴建议下载MSDN软件(相当于离线的知识站)辅助学习
抛开库函数,本篇所讲函数均为自定义函数
C语言中的库函数众多,但是仅仅是这些库函数,远远不能满足我们编程时对于函数的需求,所以我们需要学习自定义函数,自立门派。掌握自定义函数也有助于我们理解库函数的运作原理。
我们如何创建一个函数呢?
一个基本的函数应当由函数名、返回值类型、函数参数、函数体组成。函数名就是函数的名字,方便我们调用它,函数名要避免与库函数、关键字、已经定义过的函数名重名。一个函数一般会有一个返回值,可以理解为调用函数后产生的结果,它的数据类型就是返回值类型(也可以没有返回值,此时返回值类型为void)。函数参数分为实际参数和形式参数,具体见后文。函数体就是我们函数中的内容。一般函数的返回值用return关键字引出,写成return+返回值,如果有return语句,return语句就是函数结束的标志
定义函数语法:
返回值类型 函数名 (形式参数)
{
函数体;
( return 返回值;)
}
给出有返回值类型函数样例:
写一个函数可以判断一个数是不是素数
#include<stdio.h>
#include<math.h>
int sushu(int x)
{
int i = 0;
for (i = 2; i <= sqrt(x); i++)
{
if (x % i == 0)
return 0;
}
return 1;
}

上面的函数的意思就是:如果是素数就返回1,不是就返回0。需要注意的是,看似我们写了两个返回值的语句,但实际上我们只可能在同一时间得到一个返回值,当我们return 0时,函数已经结束,不会再执行下面的return 1,当我们return 1时,说明函数一次都没有读到return 0。关于函数体的意思,前文已经细致的讲解了判断素数的流程,不再赘述。
给出无返回值类型函数样例:
#include<stdio.h>
void hhh()
{
printf("哈哈哈\n");
}
这个函数并没有返回任何值,但这不妨碍它是一个函数
函数必须先声明再使用,声明的意思就是告诉编译器有这个函数的存在,然后我们才能使用它。函数的声明和函数的定义是两回事,函数声明是让函数存在的语句,函数定义是赋予函数意义的语句。
语法:
返回值类型 函数名 (形式参数类型);
用下面的例子来加深一下理解:
#include<stdio.h>
int main()
{
int a = 1;
int b = 2;
int Add(int, int);
printf("%d", Add(a, b));
}
int Add(int x, int y)
{
return x + y;
}
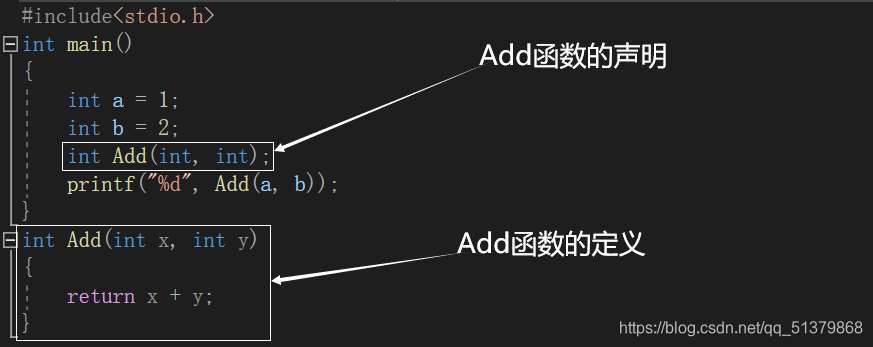
程序都是进主函数开始,出主函数结束,由于我们的Add函数定义在主函数的后面,所以如果我们不事先声明它,程序将面临一次都没有见过Add函数就要调用它的局面,那就会报错(现在有些比较智能的编译器已经不会报错了,但是我们需要养成好的代码风格,请坚持先声明再使用的原则)。
为什么我们平常写函数一般都不需要声明呢?因为如果函数在主函数之前定义的话,定义本身就是一种强有力的声明:
#include<stdio.h>
int Add(int x, int y)
{
return x + y;
}
int main()
{
int a = 1;
int b = 2;
printf("%d", Add(a, b));
}

传值调用是最基础的函数使用方法,意思就是我们只是把参数的值传给了函数,所以函数怎样处理这个值是函数的事儿,并不会改变原函数中的参数值。我们在文章开始写的判断素数的函数就是传值调用:
#include<stdio.h>
#include<stdio.h>
#include<math.h>
int sushu(int x)
{
int i = 0;
for (i = 2; i <= sqrt(x); i++)
{
if (x % i == 0)
return 0;
}
return 1;
}
int main()
{
int a = 0;
printf("打印100-200间的素数:\n");
for (a = 101; a < 200; a += 2)
{
if (sushu(a))
printf("%d ", a);
}
return 0;
}

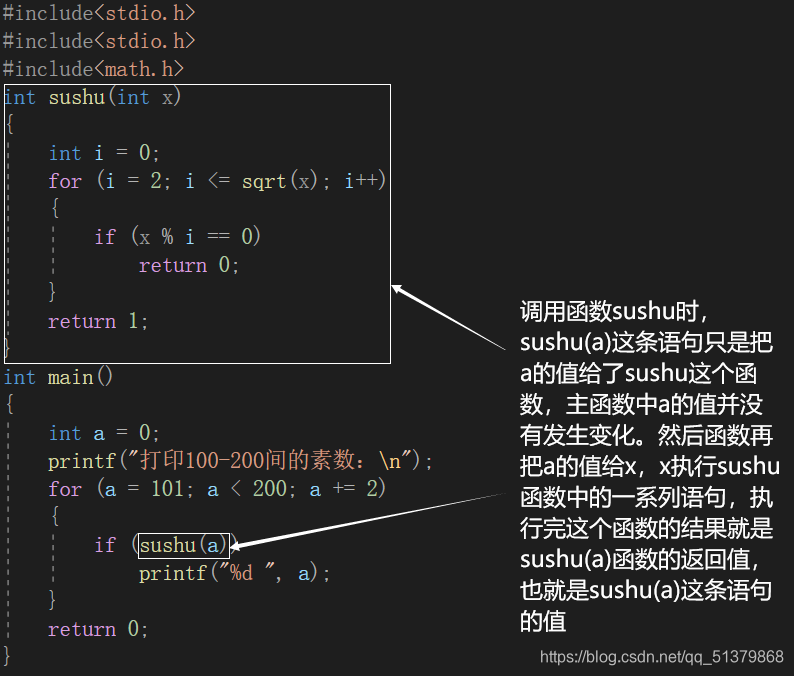
在上面这个程序中,a是负责传给函数值的参数;x是我们在函数中定义的,作用域仅在这个函数内部的,负责接收a的值并执行函数中语句的参数。我们把a叫做实际参数,把x叫做形式参数。实际参数a和形式参数x是两个不同的参数,它们在内存中会被分配不同的空间,所以实际参数a不会受到形式参数x的影响,而形式参数x由于有时需要接收实际参数a的值,所以会实际参数a的改变会影响形式参数x。我们可以把形式参数x当成实际参数a的一份临时拷贝。
传址调用的意思就是我们给函数传的不是参数的值而是参数的地址。我们什么时候需要用到传址调用呢?看下面的例子:
我们需要写一个函数,它能够交换输入的两个参数的值:
#include<stdio.h>
void change(int x, int y)
{
int z = 0;
z = x;
x = y;
y = z;
}
int main()
{
int a = 1;
int b = 2;
change(a, b);
printf("a=%d,b=%d", a, b);
}
这样写行不行呢?看一下结果:

这个函数调用是一个传值调用,我们刚刚才说过,传值调用中形式参数和实际参数是两块不同的空间,所以我们在函数中交换形式参数x和y的值并不会改变实际参数a和b的值,所以这样写是行不通的。
而如果我们使用传址调用,借助指针,就可以很好的解决这一问题:
#include<stdio.h>
void change(int* x, int* y)
{
int z = 0;
z = *x;
*x = *y;
*y = z;
}
int main()
{
int a = 1;
int b = 2;
change(&a, &b);
printf("a=%d,b=%d", a, b);
}


在此指针的作用就可见一斑了:指针可以在任何地方任何时间通过地址找到指定的变量进行操作。我们也可以这样总结传值调用和传址调用:函数内部需要对函数外部变量进行操作时用传址调用,函数内部只需要借用函数外部变量的值的时候用传值调用。
我们再练习一题:
编写一个函数让传入的参数+1(小伙伴们可以先尝试着写一下试试)
#include<stdio.h>
void Add_one(int* p)
{
(*p)++;
}
int main()
{
int x = 0;
Add_one(&x);
printf("%d",x);
return 0;
}
既然用到了指针,就不得不提一下指针使用中比较特殊的一类:数组
数组传参,传的不是数组的所有元素,而是数组首元素的地址
比如我们编写一个函数来输出数组的第二个元素:
写法一:
#include<stdio.h>
int s(int* pa)
{
int a = *(pa+1);
printf("%d", a);
}
int main()
{
int arr[10] = { 1,8989,3,4,5,6,7,8,9,10 };
s(arr);
}
写法二:
#include<stdio.h>
int s(int a[])
{
printf("%d", a[1]);
}
int main()
{
int arr[10] = { 1,8989,3,4,5,6,7,8,9,10 };
s(arr);
}
把两个写法放到一张图上对比分析一下:
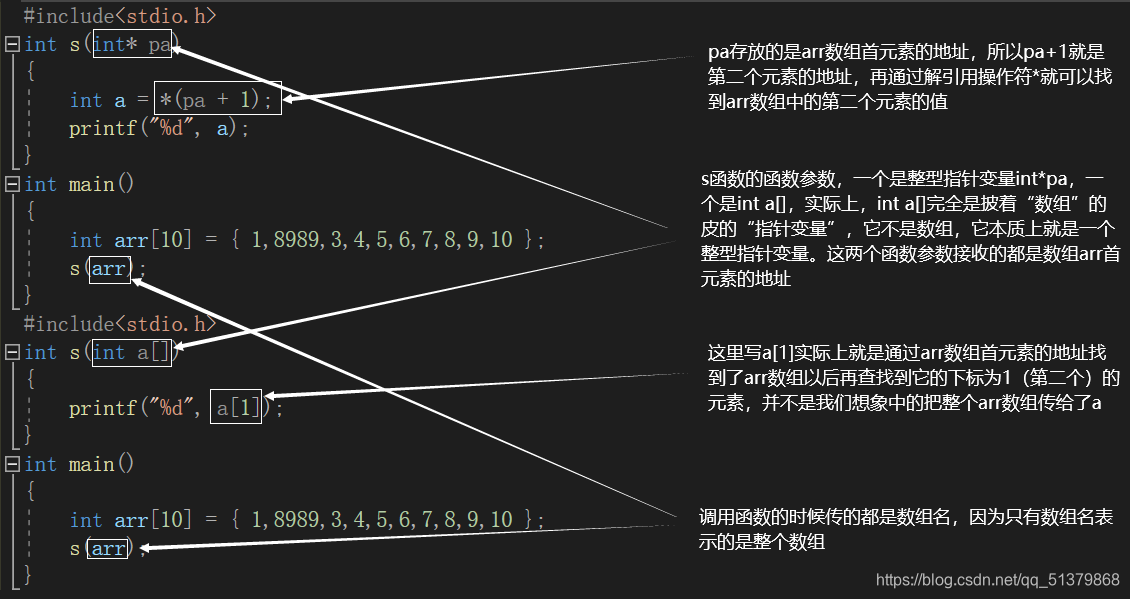
所以数组传参,看似传的是整个数组,实际上传的是数组首元素的地址
不相信的话我们再做个实验:
#include<stdio.h>
int s(int a[])
{
printf("%d\n", a);
}
int main()
{
int arr[10] = { 1,8989,3,4,5,6,7,8,9,10 };
printf("%d\n", &arr[0]);
printf("%d\n", arr);
s(arr);
}
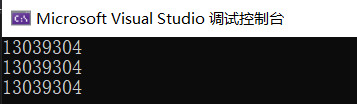
这下彻底证明了,打印数组名实际上打印的是数组首元素的地址、传参时传递数组名实际上传递的也是数组首元素的地址,这仨完全是一个东西,是披着不同马甲的同一只乌龟
函数与函数的地位是平等的,所以函数是不能嵌套定义的。但是函数允许嵌套调用。嵌套调用的意思就是函数里套用函数
举个例子:
#include<stdio.h>
void laugh1()
{
int i = 0;
for (i = 1; i <= 3; i++)
printf("哈哈 ");
}
void laugh2()
{
int j = 0;
for (j = 1; j <= 3; j++)
{
laugh1();
printf("\n");
}
}
int main()
{
laugh2();
return 0;
}

主函数调用了laugh2函数,laugh2函数里又调用了laugh1函数,这就是函数的嵌套调用。
某个函数的返回值作为了另一个函数的参数,这就是链式访问。
举例:
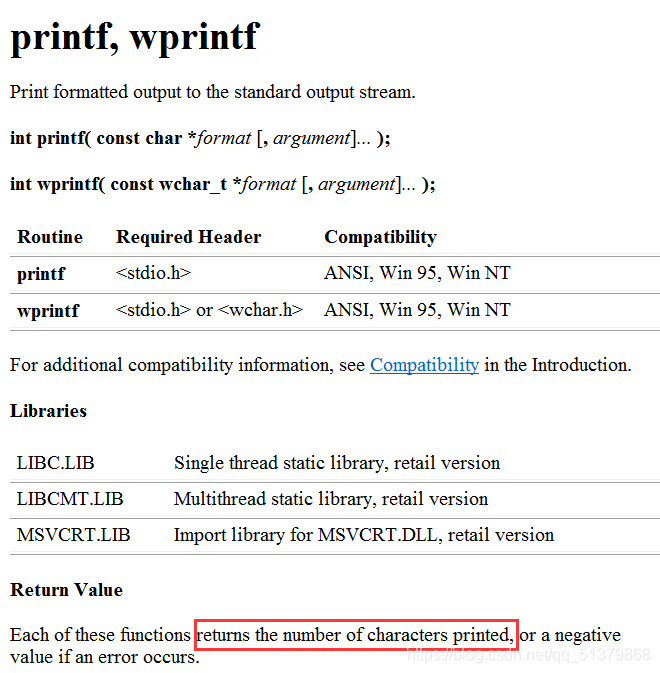
我们经常使用printf函数来打印一些东西,而printf是C语言的库函数,这个函数的返回值是什么呢?
通过查MSDN,我们发现printf打印出内容时的返回值是所打印元素的个数:
知道了这个我们来自己计算一下下面这段链式访问的代码的输出值:
int main()
{
printf("%d", printf("%d", printf("%d", 43)));
return 0;
}
答案是:

最内层的printf打印43,第二层的printf打印的是最内层printf的返回值,也就是“43”这个内容的元素个数——2,最外层打印的是“2”这个内容的元素个数——1。所以会打印出4321这四个数
程序间接或直接的调用自身的算法技巧就是递归,如果不设置限制条件,递归就会一直继续
我们通过下面的gif感性的理解一下:

这个gif就是一种常见的递归模型,但它是一个死递归,而我们使用递归必须避免出现死递归的。那该怎么正确使用递归技巧呢?我们来重点学习一下函数递归。
引例:我们需要设计这样一个程序,输入任意一个数字,然后从最低位到最高位输出它,比如输入12345,输出54321。该怎么做呢?我们把大问题拆解成小问题来看一下。拿到12345这个五位数,需要先输出5,那我们用12345%10就能得到5了;然后1234%10就可以得到4,123%10就可以得到3…对于整型变量12345,12345/10就可以得到1234,1234/10就可以得到123…也就是说,我们每一轮只需要先将输入数对10取模然后输出这个结果,再让函数参数/10得到下一轮的输入数。值得一提的是,如果仅仅是这样,函数会陷入死递归,因为没有帮助它跳出的触发条件,那我们就设置一个针对输入数的触发条件,我们发现如果输入数是1-9,也就是只有个位数,那么说明这就是最后一位了,到此就可以跳出递归。
给出原码:
#include<stdio.h>
void print(unsigned int n)
{
printf("%d", n % 10);
if (n > 9)
{
print(n / 10);
}
}
int main()
{
unsigned int num = 0;
scanf("%u", &num);
print(num);
return 0;
}


递归函数就是print函数,我们来剖析一下这个函数的运行过程

构建递归结构有两点需要注意:
1.递归必须有能够跳出递归的触发条件
2.递归时必须不断的趋近这个触发条件
否则,我们的递归很可能会变成死递归
有时候我们明明设置了跳出递归的触发条件,也确实在不断逼近这个条件,而且理论上是可以跳出递归的,但是程序仍然执行不了,比如我们看下面这个例子:
#include<stdio.h>
void print(int i)
{
printf("%d\n", i);
i++;
if (i < 10000)
print(i);
}
int main()
{
int a = 0;
print(a);
return 0;
}
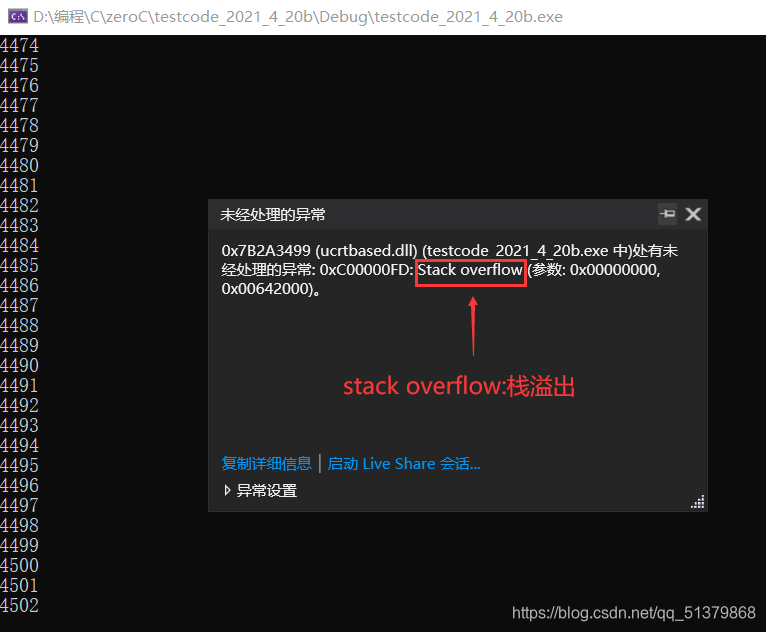
我们的程序按理来说会打印到10000然后跳出递归,但是我们的电脑打印到4502就打不动了,异常提示为栈溢出。那什么是栈溢出呢?今天我们先简单理解一下:
内存一般分为栈区、堆区、静态区三部分,栈区主要用于存放局部变量、函数的形式参数等等,属于临时分配的空间。

而我们每次调用函数都会为它在栈区分配一块临时空间
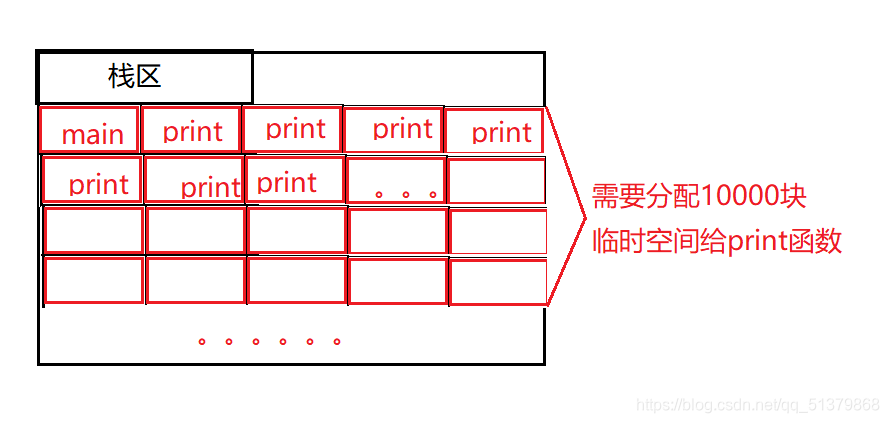
结果就是栈区的空间不足,导致栈溢出了。我们一般在程序中是使用一个函数,分配一块临时空间,用完得到函数的结果以后就销毁这块空间。但是递归函数比较庞大,几行代码可能就需要分配很多很多的空间,所以会出现栈溢出的现象。
教训就是我们在使用递归的时候不能递归太深。
我们之前讲的循环结构就是一种迭代。迭代是什么呢?我们可以简单的这样理解:
A重复调用A自身就是递归,A重复调用B就是迭代
递归的特点就是可以用极少的语句描述庞大的程序过程,可以让我们的代码变得简洁有力。迭代的特点是可读性高,较容易理解,但是语句就会相对多。有的问题只能使用递归,有的只能使用迭代,还有的既可以使用递归也可以使用迭代。
举个例子,我们都知道计算字符串长度的C库函数strlen,那我们能不能自己编写一个和它功能相同的函数my_strlen呢?
接下来分别用递归和迭代演示做法:
迭代做法:
#include<stdio.h>
int my_strlen(char* str)
{
int count = 0;
while (*str != '\0')
{
count++;
str++;
}
return count;
}
int main()
{
char arr[] = "tianxiao719";
printf("%d\n", my_strlen(arr));
return 0;
}
递归做法:
#include<stdio.h>
int my_strlen(char* str)
{
if (*str != '\0')
return 1 + my_strlen(str + 1);
else
return 0;
}
int main()
{
char arr[] = "tianxiao719";
printf("%d", my_strlen(arr));
}
函数在工程项目中最大的作用就是将大任务拆分成不同的任务块,分配给不同的程序设计师,大家每个人完成自己的那部分,最后再整合调用就好了。
比如我们需要写一个加减乘除的程序(假设都得用函数实现),目前有五位程序员abcde,a只会加法,b只会减法,c只会乘法,d只会除法,e啥都不会只会使用简单的C语言语法,所以分工就是abcd程序员将自己那部分用函数实现以后让e程序员整合
1.一般将函数的声明和函数的定义分开写,声明放在头文件(.h)中,定义放在源文件(.c)中
2.使用时需要先引头文件,语法是#include"头文件名.h"
以a程序员写的源文件和头文件为例:
声明add函数
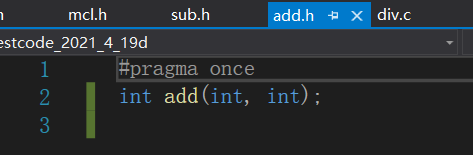
定义add函数
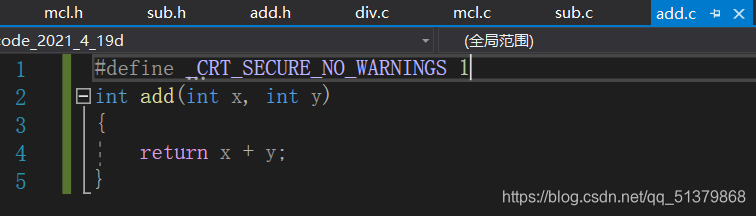
(图中出现的陌生语句大家跳过就好,不影响我们理解今天讲解的知识点)
将函数的定义与声明分开单独放在一个源文件中还有一个用处就是可以隐藏函数实现部分。比如我们以后写了一个程序,有一个懒惰的程序员想直接买来用,但是我们又不能直接给原码,那该怎么办呢?我们可以把这个程序写成一个函数,将函数的声明放在头文件中,将定义部分的文件转换成静态库,然后把头文件和静态库给客户,这样就做到了隐藏函数实现部分,但是函数还是可以正常使用了。
操作:右击项目名-配置属性-常规-配置类型-静态库-应用-确定-F5编译
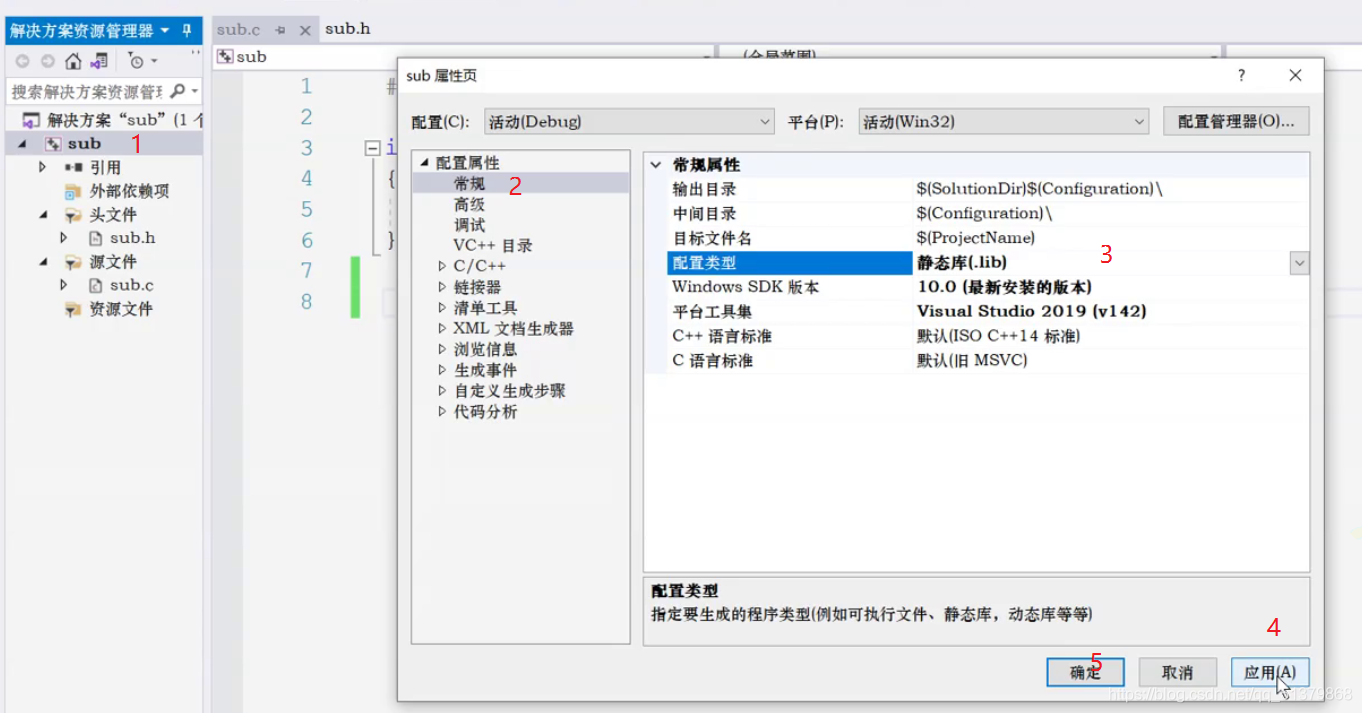
在目录中就会生成静态库文件
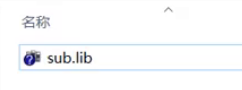
这个静态库文件和头文件sub.h就是我们卖给客户的文件
那客户怎么使用呢?只需要把这两个文件拷贝到自己解决方案下的文件夹中,然后在解决方案中打开头文件sub.h再在程序中加上这一行代码导入静态库:
#pragma comment(lib,"sub.lib")
即可

在HTML中,中文的好好学习可以表示为好好学习 在项目中,需要对接短信告警,短信...
歌词编辑器 歌词编辑器 第一步:选择要播放的歌曲并播放 第二步:填写全部的歌词...
这篇文章介绍了英国《卫报Guardian》为什么和如何从Mongo迁移到Postgres,英国卫...
ajax局部刷新 script setInterval("refreshTime()",1000); //每格1秒刷新一次 fu...
复制代码 代码如下: 匹配中文字符的正则表达式: [\u4e00-\u9fa5] 评注:匹配中...
但是最近发现使用这种方式会产生问题,见代码: 复制代码 代码如下: !DOCTYPE HT...
DevOps还未彻底发展成熟。如果用人的一生来比喻,那么DevOps还只是位少年虽然早...
本文实例讲述了PHP中abstract(抽象)、final(最终)和static(静态)原理与用法。分...
上图是ST正式发布的涨价通知2021年1月1日起全线产品涨价 由于晶圆代工产能持续紧...
系列文章目录 文章目录 系列文章目录 前言 一、数据类型介绍 1.类型的基本归类 1...

