


在玩爬虫的时候,总会遇到一些无法通过xpath提取的数据,通常都会存放在JSON格式中,所我这学一下jsonpath。
可以看看我这篇博客,不过有不全的地方请多多担待,提出来一起学习一起进步!
JSON学习笔记
jsonpath是对JSON格式提取文件的东西,看看这熟悉的path,有没有联想到xpath?差不多,都是用来提取数据的东西
先安装jsonpath第三方库
pip install jsonpath -i https://pypi.doubanio.com/simple
| 符号 | 描述 |
|---|---|
| $ | 查询的根节点对象,用于表示一个json数据,可以是数组或对象 |
| @ | 过滤器(filter predicate)处理的当前节点对象 |
| * | 获取所有节点 |
| . | 获取子节点 |
| … | 递归搜索,筛选所有符合条件的节点 |
| ?() | 过滤器表达式,筛选操作 |
| [start:end] | 数组片段,区间为[start,end),不包含end |
| [A]或[A,B] | 迭代器下标,表示一个或多个数组下标 |
我们的数据是从王者网站拿的——王者网站
大概就是张这个样子
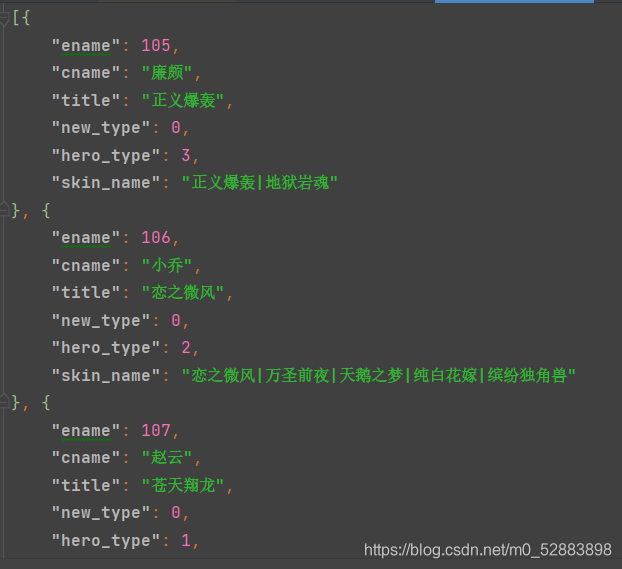
然后我们开始联系jsonpath吧
import jsonpath # 导入jsonpath包
import json # 导入json包
import requests # 导入爬虫包
with open("王者英雄.json",'wb') as f:
f.write(requests.get('https://pvp.qq.com/web201605/js/herolist.json').content)
# 将json文件保存到本地
with open('王者英雄.json', 'r', encoding="utf-8") as f:
js = f.read()
# 读取
c = json.loads(js) # 转成python数据
print(jsonpath.jsonpath(js, '$.*.cname')) # 使用jsonpath将英雄名字取出来
'''
$.:根目录
*:根目录下所有节点
cname:所有cname元素的值
'''
运行结果:

拜拜 学习如逆水行舟,不进则退,所以一定要在学习后多加练习~~~~~
那么今天就到这里了哦,( _ )/~~


文章目录 1 前言 2 笔试 2.1 以下哪些类可被继承 2.2 List与Map等集合相关 2.3 ...
阿里妹导读:突然而至的疫情,让线下娱乐几乎停摆。全国人民对于线上娱乐需求激...
微软对Windows 10上的复制粘贴功能进行了全新升级,其带来了更大的便利。 微软现...
由于一中考评系统要加入一个新的功能“调查问卷”,我想沿用别人做好的调查问卷...
本文实例讲述了php7 错误处理机制修改。分享给大家供大家参考,具体如下: 一、...
今天给大家分享四个在实际开发中,比较实用的SQL Server脚本函数,希望对大家能...
在今天更新的官方博文中,微软解释了如何让终端用户和网络管理员更快安装 Window...
在我们进行项目开发期间,避免不了使用各式各样的组件, Element 是由饿了么公司...
目录 介绍 区块链 世界状态 账户 交易 消息(Message) 去中心化数据库 原子性和顺...
% '为了支持原创,请保留该处注释,谢谢! '作者:草上飞 '获取主域名 Functiong...

