

在以前的项目中,最常见的两种主键类型是自增Id和UUID,在比较这两种ID之前首先要搞明白一个问题,就是为什么主键有序比无序查询效率要快,因为自增Id和UUID之间最大的不同点就在于有序性。
我们都知道,当我们定义了主键时,数据库会选择表的主键作为聚集索引(B+Tree),mysql 在底层是以数据页为单位来存储数据的。
也就是说如果主键为自增 id 的话,mysql 在写满一个数据页的时候,直接申请另一个新数据页接着写就可以了。如果一个数据页存满了,mysql 就会去申请一个新的数据页来存储数据。如果主键是UUID,为了确保索引有序,mysql 就需要将每次插入的数据都放到合适的位置上。这就造成了页分裂,这个大量移动数据的过程是会严重影响插入效率的。
一句话总结就是,InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的。
但是为什么很多情况又不用自增id作为主键呢?
容易导致主键重复。比如导入旧数据时,线上又有新的数据新增,这时就有可能在导入时发生主键重复的异常。为了避免导入数据时出现主键重复的情况,要选择在应用停业后导入旧数据,导入完成后再启动应用。显然这样会造成不必要的麻烦。而UUID作为主键就不用担心这种情况。不利于数据库的扩展。当采用自增id时,分库分表也会有主键重复的问题。UUID则不用担心这种问题。那么问题就来了,自增id会担心主键重复,UUID不能保证有序性,有没有一种ID既是有序的,又是唯一的呢?
当然有,就是雪花ID。
什么是雪花IDsnowflake是Twitter开源的分布式ID生成算法,结果是64bit的Long类型的ID,有着全局唯一和有序递增的特点。
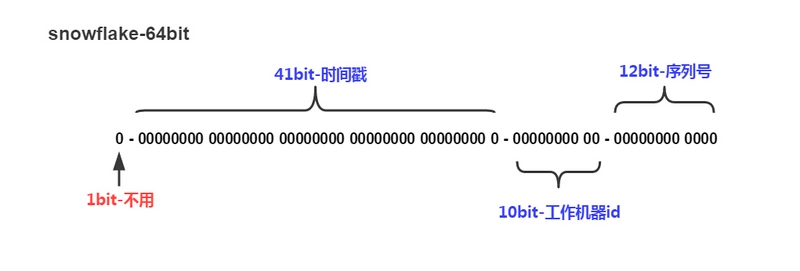
缺点也是有的,就是强依赖机器时钟,如果机器上时钟回拨,有可能会导致主键重复的问题。
Java实现雪花ID下面是用Java实现雪花ID的代码,供大家参考一下。
public class SnowflakeIdWorker {
* 开始时间:2020-01-01 00:00:00
private final long beginTs = 1577808000000L;
private final long workerIdBits = 10;
* 2^10 - 1 = 1023
private final long maxWorkerId = -1L ^ (-1L workerIdBits);
private final long sequenceBits = 12;
* 2^12 - 1 = 4095
private final long maxSequence = -1L ^ (-1L sequenceBits);
* 时间戳左移22位
private final long timestampLeftOffset = workerIdBits + sequenceBits;
* 业务ID左移12位
private final long workerIdLeftOffset = sequenceBits;
* 合并了机器ID和数据标示ID,统称业务ID,10位
private long workerId;
* 毫秒内序列,12位,2^12 = 4096个数字
private long sequence = 0L;
* 上一次生成的ID的时间戳,同一个worker中
private long lastTimestamp = -1L;
public SnowflakeIdWorker(long workerId) {
if (workerId maxWorkerId || workerId 0) {
throw new IllegalArgumentException(String.format("WorkerId必须大于或等于0且小于或等于%d", maxWorkerId));
this.workerId = workerId;
public synchronized long nextId() {
long ts = System.currentTimeMillis();
if (ts lastTimestamp) {
throw new RuntimeException(String.format("系统时钟回退了%d毫秒", (lastTimestamp - ts)));
// 同一时间内,则计算序列号
if (ts == lastTimestamp) {
// 序列号溢出
if (++sequence maxSequence) {
ts = tilNextMillis(lastTimestamp);
sequence = 0L;
} else {
// 时间戳改变,重置序列号
sequence = 0L;
lastTimestamp = ts;
// 0 - 00000000 00000000 00000000 00000000 00000000 0 - 00000000 00 - 00000000 0000
// 左移后,低位补0,进行按位或运算相当于二进制拼接
// 本来高位还有个0 63,0与任何数字按位或都是本身,所以写不写效果一样
return (ts - beginTs) timestampLeftOffset | workerId workerIdLeftOffset | sequence;
* 阻塞到下一个毫秒
* @param lastTimestamp
* @return
private long tilNextMillis(long lastTimestamp) {
long ts = System.currentTimeMillis();
while (ts = lastTimestamp) {
ts = System.currentTimeMillis();
return ts;
public static void main(String[] args) {
SnowflakeIdWorker snowflakeIdWorker = new SnowflakeIdWorker(7);
for (int i = 0; i i++) {
long id = snowflakeIdWorker.nextId();
System.out.println(id);
}main方法,测试结果如下:
184309536616640512 184309536616640513 184309536616640514 184309536616640515 184309536616640516 184309536616640517 184309536616640518 184309536616640519 184309536616640520 184309536616640521总结
在大部分公司的开发项目中里,雪花ID是主流的ID生成策略,除了自己实现之外,目前市场上也有很多开源的实现,比如:
美团开源的Leaf百度开源的UidGenerator有兴趣的可以自行观摩一下,那么这篇文章就写到这里了,感谢大家的阅读。
觉得有用就点个赞吧,你的点赞是我创作的最大动力~
我是一个努力让大家记住的程序员。我们下期再见!!!

客户简介 深圳盒子信息科技有限公司成立于2011年,是国家高新技术企业、深圳市高...
最大传输单元(Maximum Transmission Unit,MTU)是指一种通信协议的某一层上所...
1、智能语音点餐机解决方案方案架构 架构特点 基于达摩院特有的多模态交互技术 ...
在过去的一年中,云计算已经成为组织应对冠状病毒疫情对其业务不利影响的关键技...
中台有机衔接稳定的后台系统和灵活多变的前端业务场景 通过抽取后台系统的数据 ...
MongoDB是一个基于分布式文件存储的数据库。 由C++语言编写。旨在为WEB应用提供...
怎么防御udp攻击?UDP Flood是日渐猖厥的流量型 ddos 攻击。常见的情况是利用大...
发布会传送门 : https://yqh.aliyun.com/live/aiotfa 近日,阿里云AIoT春季产品...
3月Techo Youth高校公开课Demo实操演练 【活动已结束】 3月Techo Youth高校公开...
2020年7月9日,2020年世界人工智能大会(the World Artificial Intelligence Con...

