

增强现实(AR)技术想必大家都不陌生了,2016年,由任天堂制作的AR手游Pokeman Go横空出世,一度造成万人空巷,大家在全世界各个角落都开始拿着手机“抓怪兽”的盛况。但是唯独在国内的小伙伴们无法享受到这款游戏的乐趣,为什么呢?这要从这款游戏的技术背景说起,Pokeman Go看起来是一个场景巨大到全世界的AR游戏,但其实它依赖的技术却并不复杂,如果简单来说,就是基于Google Map的定位,地面检测,局部的相机姿态跟踪以及渲染能力。
首先,利用Google Map提供的手机位置信息,玩家就可以随时遇见事先被放置好的“怪兽”,为了增强游戏的趣味性,游戏公司会特意在特定的地方(比如公园)放置稀有“怪兽”,吸引玩家集中到某个地方来抓。当玩家用手机发现“怪兽”后,通过手机配置的摄像头与惯性测量传感器,算法会大致推断地面的位置,之后将怪兽的三维模型放到地面上,并计算手机相对于怪兽的姿态,最后像拍照一样,把怪兽实时地渲染到手机屏幕上,玩家就能看到一个栩栩如生的怪兽出现在前方草地上了。

图一:五千人在芝加哥街头用手机抓“怪兽”

图二:AR手游:Pokeman Go
其实,以上描述的“抓怪兽的过程”,就是目前应用最广泛的AR技术基础链路。首先,全局定位能力(Global Localization)。我们需要设定一个场景,并且,我们需要具备在这个场景中自我定位的能力。在Pokeman Go这款游戏中,可以认为场景就是背靠Google Map的全世界(除中国大陆地区)。在户外,定位能力就是Google Map结合GPS信号等信息提供手机位置的能力。第二,简单的场景理解能力(Scene Understanding)。游戏中,算法利用手机上的传感器计算出地面的大致三维位置,就可以将任意的虚拟三维模型放置在地面上方恰当的地方。第三,求解手机摄像头与虚拟三维模型之间的相对姿态(位置和角度)。这是一种利用图像间的特征匹配和手机上的惯性测量单元(IMU),进行实时手机姿态解算的能力,此处就不展开讨论了,感兴趣的读者可以搜索关键字(Visual inertial odometry). 最后,渲染能力(Rendering)将虚拟物体与真实场景叠加,显示在手机屏幕上。
读到这里,读者应该知道为什么我们在大陆地区没法最好地体验这款游戏了。因为Google Map在国内无法访问。这,也就引出了目前AR应用的一个核心问题。在搭建任何AR应用前,我们都需要一张地图,在室外,目前的地图服务商Google Map,高德,百度帮我们提供了地图和定位能力。那如果是在无法获取GPS的室内,或者GPS信号较弱的市区,商圈,景区呢?一个可以支持AR应用的地图从何而来呢?对于当前规模越来越大的城市建筑,如何在保证一定地图精度的同时,达到高效地地图采集呢?在这篇文章里,我们想和大家分享,阿里云人工智能实验室在向大规模AR应用迈进的道路上,对高效构建精确AR地图的探索。
二. 全局定位技术概述在讲述如何构建AR地图之前,我们需要弄清楚什么是AR地图。在上一节中,我们讲到,AR应用的基础是全局定位功能,也就是说,AR地图必须要服务于定位能力。所以,我们有必要简单介绍一下定位算法。定位算法的输出,根据不同的场景,各有不同。对于简单的户外游戏应用,GPS提供的经纬度和海拔信息可能就足够了。但是,对于复杂的室内场景应用,如AR导航,我们通常需要得到相机六个自由度的位姿信息 (在三维空间,六个自由度包括三个坐标轴上的平移与旋转角度信息。)
那么如何得到相机六个自由度的位姿呢?下方图三是相机成像原理的简化示意图,图四是更加复杂的相机投影数学模型。在这里,我们先略过数学原理,简要来说,我们借助三维重建技术,如果已知(图三中)真实空间中大树的顶端和底端的三维位置,以及对应图像中,树顶和树根的图像坐标,我们就可以通过一种被称之为Perspective-n-Points(PnP)的方法求解得到拍摄这张图像的相机位姿。当然,实际情况比这里描述的过程复杂得多,问题在于两点:一,我们怎么获取一张图片上的图像坐标和三维空间位置的对应关系呢?二,我们怎么知道大树顶端和底端的真实三维位置呢?
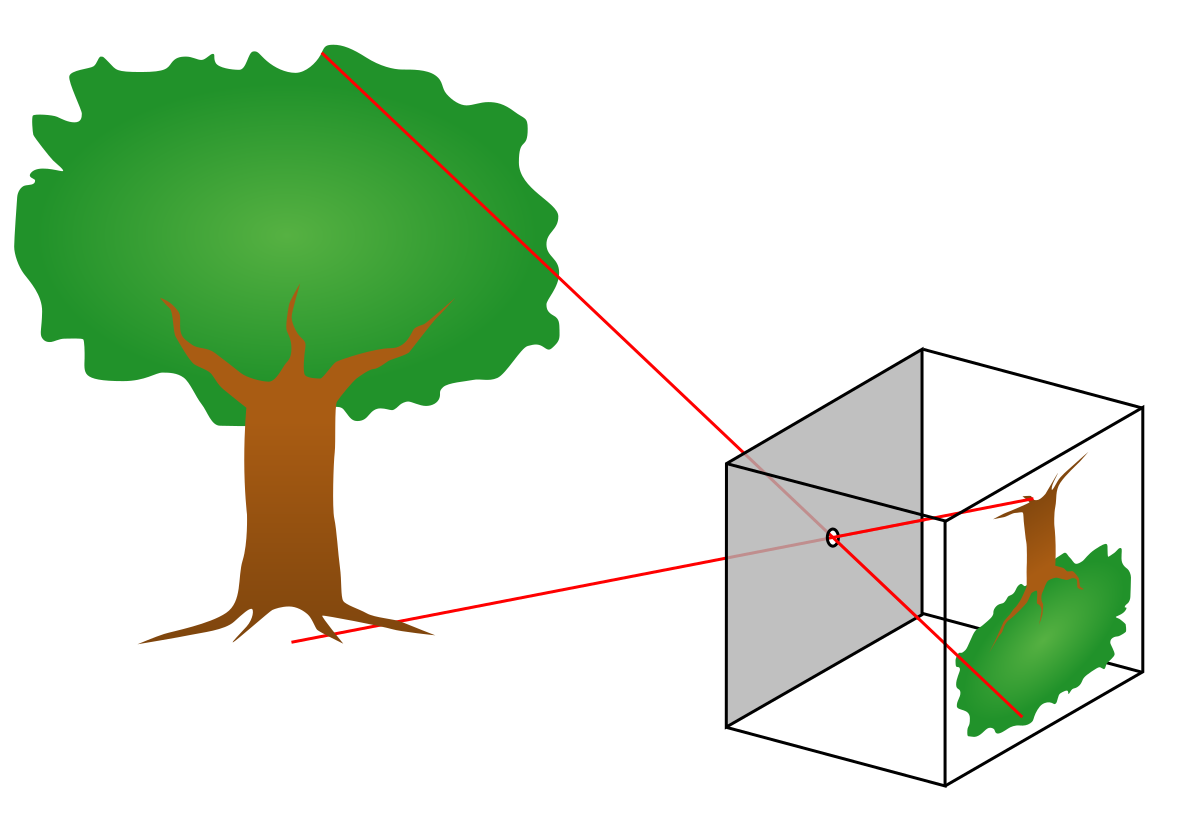
图三:相机成像原理示意图
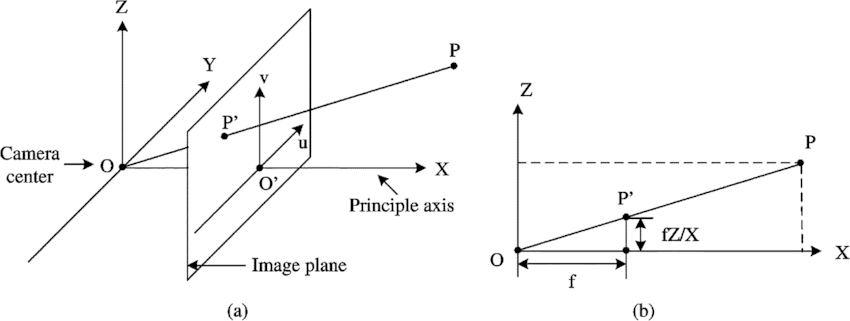
图四:相机投影数学模型
定位算法试图解决的,就是第一个问题。而通过构建图像坐标到三维位置对应关系,来求解相机位姿的定位方法,我们可以称之为“基于结构的”定位方法(structure-based) (另外一种“基于回归的”定位方法(regression-based)利用神经网络“记住”场景,并通过传入的图像直接回归相机位姿。这里不做展开,感兴趣的同学可以参阅[3,4,5])。如果继续细分,“基于结构的”定位方法又可以分为两种技术路线:
a. 稀疏特征匹配(sparse feature matching)。如图五所示,稀疏图像特征,也就是一张图片中极具特点(distinctive)的像素点。如图五中所示,目前基于SuperPoint神经网络[1]提取到的特征点,以及经过深度学习训练的特征匹配器SuperGlue[2],已经可以在光照环境,拍摄视角迥异的两张图片中,找到对应特征点,如果我们已知,右图中特征点对应的三维位置,我们就可以以之为中介,得到左图的特征点对应的三维位置,从而求解左图的相机位姿。
b. 稠密场景坐标回归(dense scene coordinate regression)。如图六所示,这种方法利用一个场景中,事先采集的图片与三维信息对神经网络进行训练,使得神经网络对输入的彩色图像可以直接估算稠密的三维坐标。注意,是对每一个像素点,都利用网络回归出它的三维信息,从而通过稠密的图像坐标与三维坐标对应关系,求解相机的位姿。

图五:基于CNN网络的Sparse feature matching
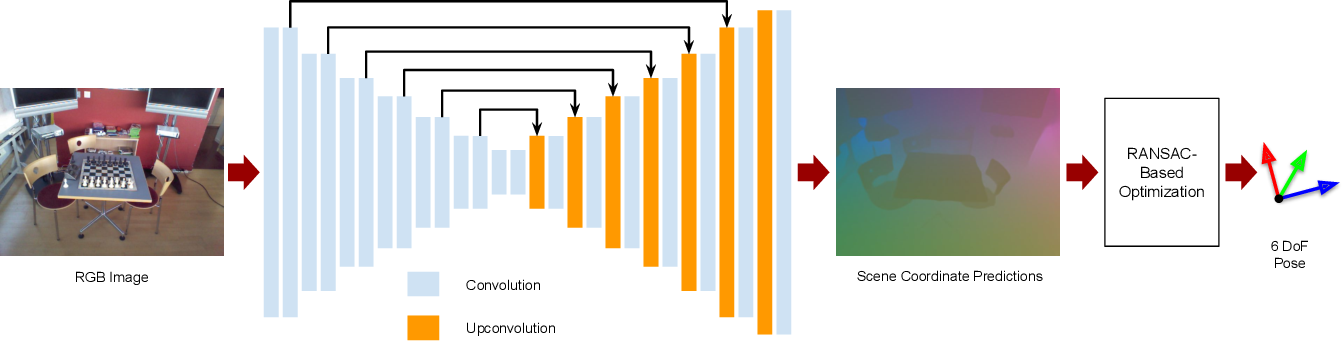
图六:稠密场景坐标回归方案
三. 什么是AR地图上一节中,我们花了一些篇幅介绍了前沿的视觉定位算法,我们发现要满足定位需求,所需要的输入信息包括:特定场景中采集的彩色图片,以及它们对应的三维信息以及相机位姿。我将这些信息的集合称为AR地图。当然,AR地图是满足定位需求的最小集合,我们也可以以此为基础,加入其他可以用来辅助定位的信息,比如场景中的语义信息等。我们定义了AR地图的主要元素,并不代表我们就能制作满足条件的AR地图,还需要回答下面三个问题:
1.如何高效地采集并且更新AR地图,来应对变换频繁的室内场景?
2.如何设计一套建图算法,来保证AR地图的精度?
3.如何有效地评估AR地图,是否达到了AR应用对于地图的要求?
接下来,我们就围绕这三个问题,来介绍我们的AR地图构建方法。
在AR地图中,最为重要的是和彩色图片对应的三维信息。那么,我们目前是通过什么手段获取三维信息的呢。如图七中所示,我们是通过不同的传感器,获取到不同类型的三维数据,再经过算法的加工,最后将三维世界数字化的。这些传感器各有特点,也各有利弊。比如,多线激光雷达通过旋转的激光发射器,直接获取周围环境的深度信息,但是由于造价和工艺结构的约束,单个雷达能扫描到的范围非常有限,深度值测量也很离散。彩色相机虽然可以捕捉到场景中大范围的色彩信息,但是需要复杂的算法流程才能恢复出三维信息。而且相机常常受到光照变化和运动模糊的影响。惯导设备IMU可以测量自身感受到的加速度和角速度等信息,但是由于IMU一般存在较大的累积漂移误差,也不能直接用来测量自身的三维位姿。所以将不同传感器进行组合,才能以最优的方式获取到场景的精确三维信息。

图七:我们通过不同传感器获取真实三维世界的数据,然后利用算法构建AR地图中的三维数据
所以,我们自研了一款以背包为形态(如图八所示),搭载多种传感器的移动扫描设备。这款设备装配有全景相机,激光雷达,惯性测量单元(IMU)。所有传感器通过我们自研的时间同步板进行同步。在对特定的场景进行扫描的时候,使用者背负着背包扫描设备,并且手持搭载有采集程序的平板电脑进行数据采集。采集过程中,激光雷达不停旋转扫描,获取原始扫描点云数据,当需要采集全景图时,使用者会停止走动,通过采集程序中的采集按钮,进行全景图图像采集。因为拍摄全景图片所需时间很短,我们可以在场景中的任意位置密集采样全景图。当对某个场景的数据采集完成后,我们得到的是背包设备输出的原始数据,这些数据包括全景相机的图片,激光雷达的单帧点云,以及IMU的原始测量数据。
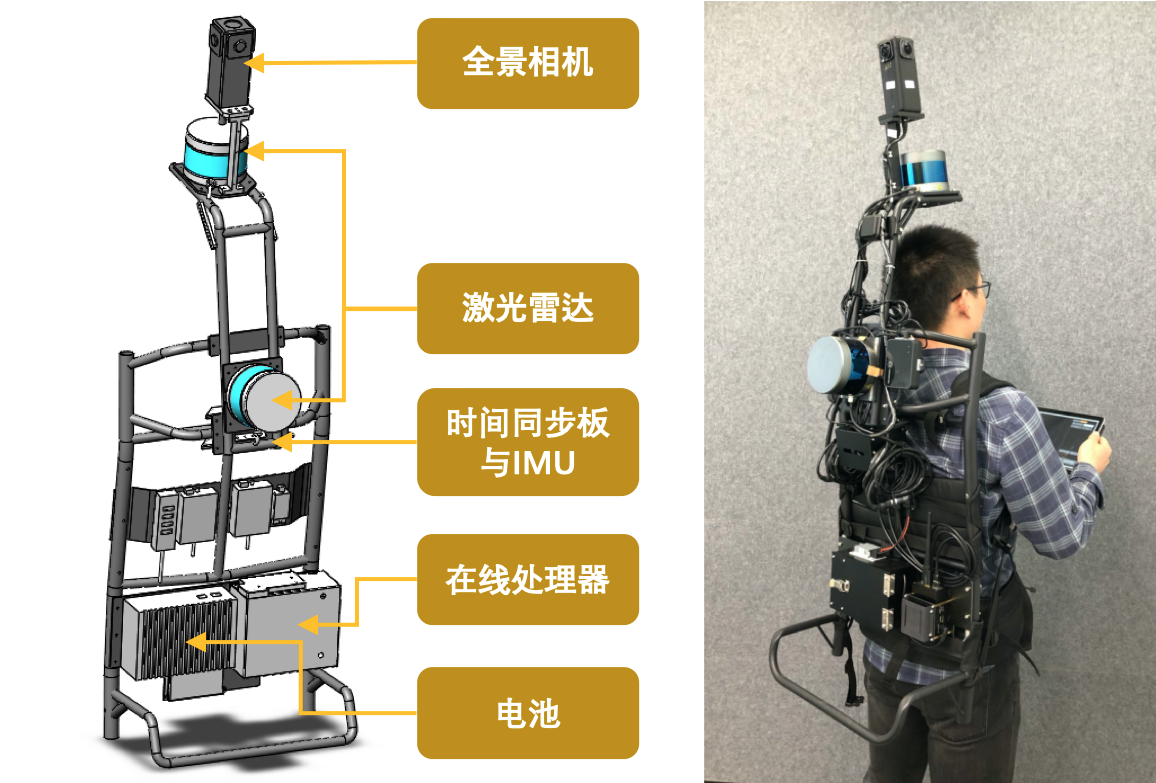
图八:背包结构示意图
借助自研背包扫描设备以及扫描距离达到150米的激光雷达,我们就能按照正常的行走速度在大场景里面进行高效数据采集了。然而,我们获取的原始数据还需要建图算法的加工,才能生成包括三维模型和相机位姿在内的三维数据。我们首先通过一套自研的多传感器标定算法,将背包上各个传感器的相对位姿求解出来。这套标定算法克服了传统方法需要反复采集多个点位数据,以及传感器间必须保证视角重叠区域的约束。只需要一个点位的采集数据,就可以得到多相机与多雷达间的相对关系。感兴趣的读者请关注我们团队关于多传感器标定的文章。
五. AR地图生产流程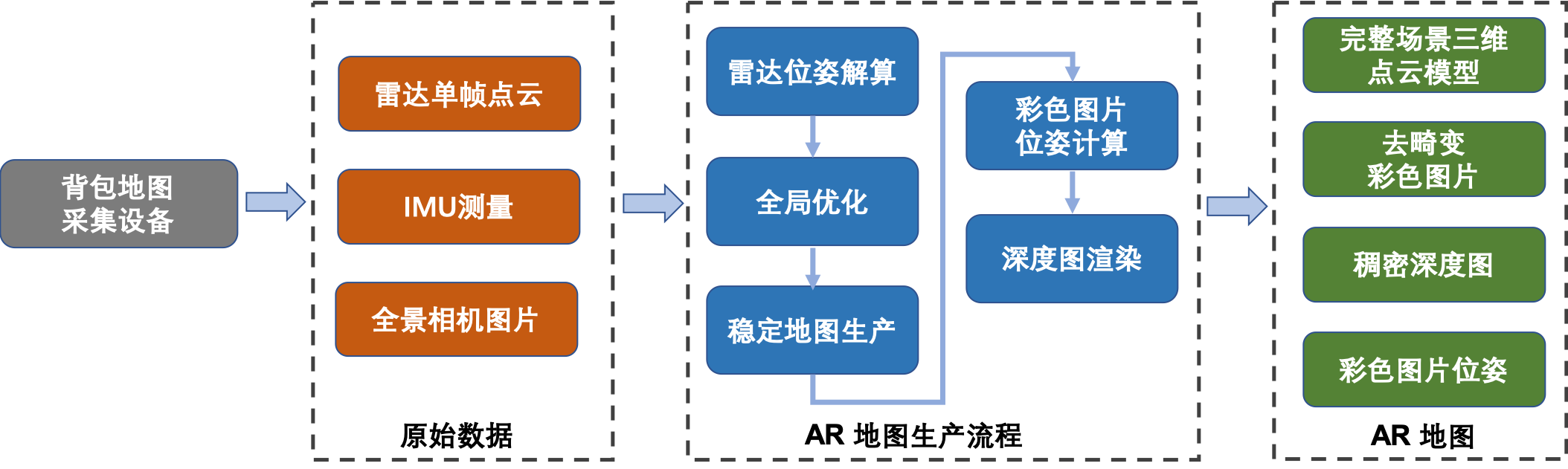
图九:AR地图的生产流程图
如图九所示,AR地图的生产流程主要包括五个子模块:雷达位姿解算,全局优化,稳定地图生产,彩色图片位姿计算和深度图渲染。以下对这五个子模块进行描述:
1.雷达位姿解算:根据输入的连续的单帧雷达点云数据,求解相邻两帧点云数据之间的位姿转换关系,该转换关系包括相邻两帧雷达数据的平移与旋转关系。通过不断积累两帧之间的转换关系,得到每一帧雷达在全局坐标系下的位置与旋转信息。
背包扫描设备上装配的两个16线激光雷达,扫描平面呈25度。每个雷达连续旋转扫描,在0.1秒内旋转360度,并产生75个数据包(data packet),我们称0.1秒的雷达数据为单帧扫描点云。雷达位姿解算就是通过求解连续两帧的雷达点云相对关系,来推算雷达的位姿。这里我们通常用到的算法称之为ICP-Iterative closest point. 通过查找两帧点云中的最近点,迭代地优化雷达在两帧间的相对位姿(如下图十)。但是由于每帧点云的数量很大,ICP中的最近邻查询算法会非常耗时。所以2014年的RSS上,Zhang JI提出了经典的LOAM算法 [6],通过计算局部点云的分布情况(图十一),提取单帧点云中的平面点与角点 (planar feature and corner feature), 这样减少了相邻两帧点云的匹配关系数量,提高了位姿解算的效率。
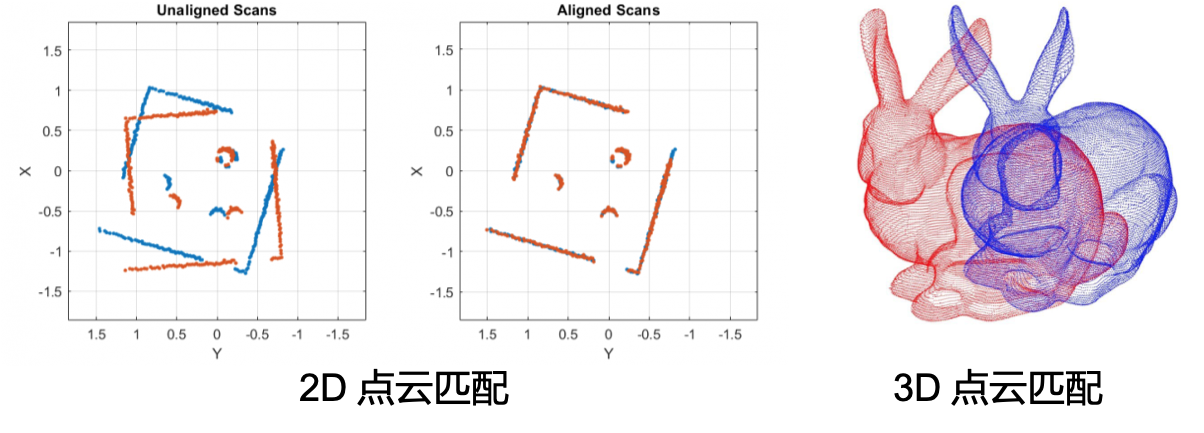
图十:二维和三维点云的ICP匹配示意图
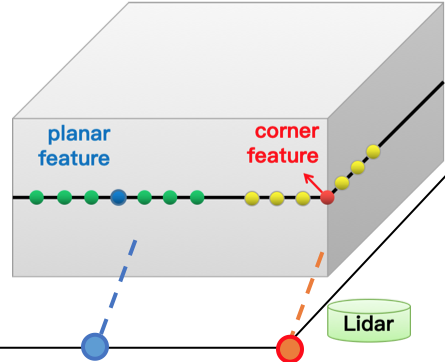
图十一:LOAM中的点云特征点提取
我们利用在每一帧点云中提取得到的平面点(蓝色)与角点(红色),与上一帧点云中“平面”和“边缘”建立对应关系,通过最小化“点到平面”与“点到线”的距离,优化得到两帧间的相对位姿。边缘点特征是通过计算相邻点的相对距离来决定的,与相邻点重心距离较大的点,会被提取为边缘特征 (如图十中所示)。但是由于室内场景复杂,常常因为遮挡,噪声,以及深度不连续的问题,会引入不少“伪”特征点(如图十二所示)。这些“伪”特征点会形成错误的特征匹配关系,影响位姿估计。为了消除“伪”特征带来的影响,我们设计的“伪”特征过滤机制(公式一),可以过滤掉大部分的“伪特征”。
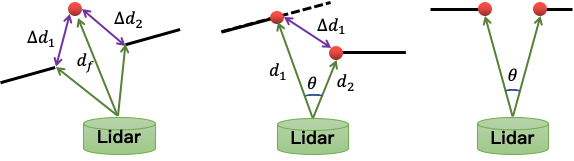
图十二:“伪”特征点生成的三种方式:离群点,深度不连续,以及遮挡导致的不连续。
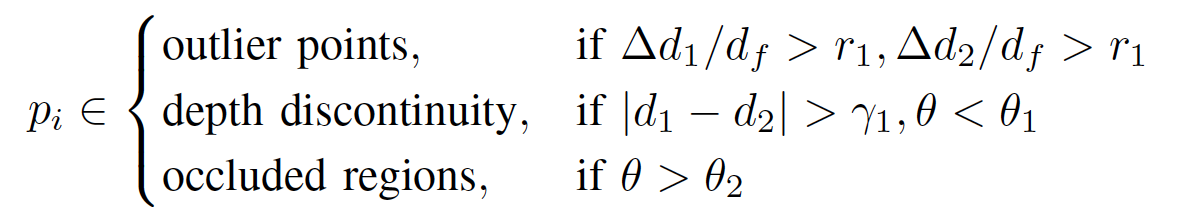
公式一:“伪”特征过滤机制
如图十三所示,在户外场景中,草地往往会引入大量的“伪”边缘点,影响位姿的估算,针对性的实验证明,我们的过滤机制可以去除这些噪声。

图十三:伪边缘点的去除
2.全局优化:由于相邻两帧雷达的相对位姿解算存在误差,经过长时间积累得到的全局位姿会存在较大的累积误差,全局优化模块通过回环检测对所有雷达位姿进行优化,减小累积误差。我们在传统的位姿图优化的基础上,加入了保持相邻子点云地图间,点云一致性的约束,使得全局优化后的点云地图仍然能保持较好的局部一致性(图十四)。
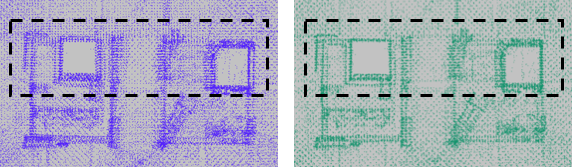
图十四:不加入与加入点云一致性的全局优化结果对比,注意左侧的点云存在较大分层现象,右侧的点云结构更加清晰。
3.稳定地图生产:在得到所有单帧雷达点云的位姿后,我们可以将点云拼接得到场景完整的三维点云模型。由于场景中的动态物体会引入杂点,我们通过过滤杂点,得到稳定完整的三维点云(图十五)。我们称之为稳定地图点生成模块。

图十五:在繁忙室内环境的点云地图结果,人来人往,带入了很多杂点,右侧是经过杂点过滤的点云地图,消除了动态点引入的噪声。
4.彩色图片位姿计算:我们最终需要得到彩色图片对应的的相机位姿,通过事先标定得到的雷达与全景相机的转换关系,我们将雷达的位姿转换得到对应时刻的相机位姿。
5.深度图渲染:如图十六所示,在得到完整的三维点云与彩色图片相机位姿之后,我们可以通过投影渲染的方式得到对应的深度图。深度图可以用来快速索引彩色图片上某一点的三维坐标。
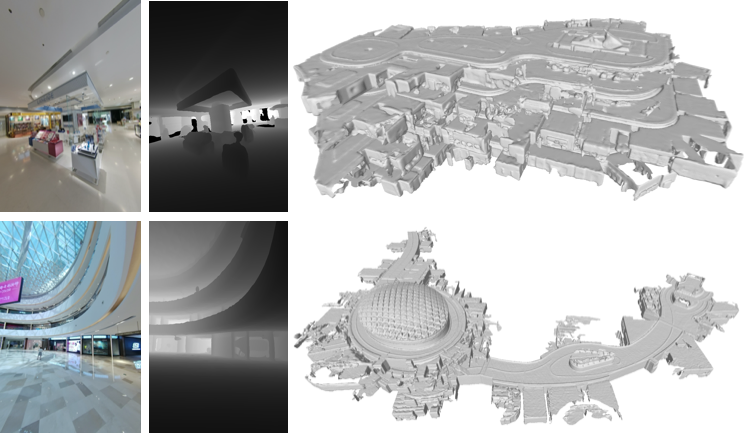
图十六:两个大型商场AR地图中的彩色图片,深度图,以及基于三维点云生成的三维模型。
六. AR地图的评估我们生产的AR地图中主要包含的是场景三维模型与彩色图片的位姿信息。所以,我们从两个方面对AR地图的精度进行评估:1. 点云地图的精度;2. 彩色图片位姿与深度图的精度。
首先,为了评估点云地图的精度,我们利用工业级的扫描设备Leica BLK360对场景进行扫描,再将其生成的点云地图作为参考真值,评估背包扫描地图的精度(图十七)。

图十七:在办公室与户外园区场景下,Leica BLK360与背包设备生成点云地图的对比。
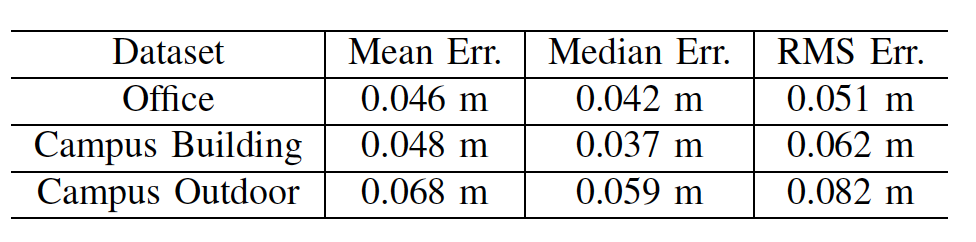
表格一:在三个不同场景Office,Campus Building, Campus Outdoor的点云地图精度评测结果。
其次,为了统计局部图像位姿与深度的一致性,我们计算了图像间特征匹配(图十八)的重投影误差e1与对极约束误差e2。

图十八:图像间的特征点匹配
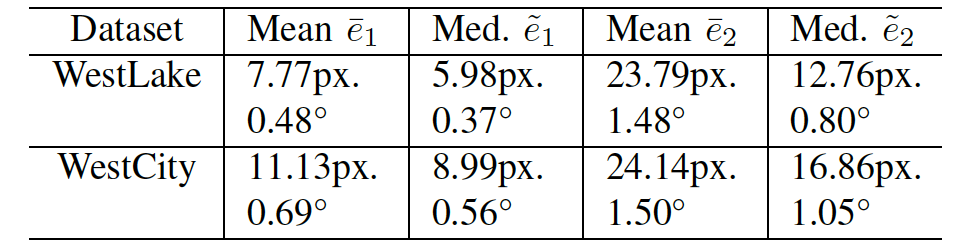
表格二:在西湖与西城两个场景中,图像间的特征重投影误差均值和中位数。
最后,我们用iPhone11在场景中随机采集图像,并利用AR地图进行定位(图十九),在全部110张手机图像中,97张(88.2%)可以被成功定位, 也证明了AR地图在定位模块中的可用性。

图十九:在大型商场场景中的定位结果。第一行为AR地图中的示例图片以及场景中的位姿。第二行为iphone11采集得到的查询图片,以及在AR地图中的定位结果。
七. 更多应用案例:VR内容生产我们生产的AR地图同样可以用于VR的内容生成。我们采集了办公室,商场,园区,地下管廊等场景的AR地图,并通过我们团队的“万花筒”VR漫游生产系统,生成VR漫游效果。


图二十:EFC商场(上图)以及办公室(下图)的VR漫游效果。
八. 总结无论是增强现实(AR)或是虚拟现实(VR),都将在未来成为人们与真实世界交互的新方式。在这篇文章中,我们介绍了阿里云人工智能实验室在构建大场景室内AR/VR地图数据上的探索。我们提供了一套从高效硬件采集设备,AR地图构建算法,到评估体系的全链路解决方案。这套解决方案能在包括大型商场,园区等场景高效构建精确的AR地图数据,也为我们之后能支持大场景下的AR应用,打下了坚实的基础。
参考文献
[1] DeTone, Daniel, Tomasz Malisiewicz, and Andrew Rabinovich. "Superpoint: Self-supervised interest point detection and description."Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2018.
[2] Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4938–4947, 2020. 1, 2, 5, 6
[3] Alex Kendall and Roberto Cipolla. Modelling uncertainty in deep learning for camera relocalization. In 2016 IEEE international conference on Robotics and Automation (ICRA), pages 4762–4769. IEEE, 2016. 1, 2
[4] Alex Kendall and Roberto Cipolla. Geometric loss functions for camera pose regression with deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5974–5983, 2017. 1, 2
[5] Alex Kendall, Matthew Grimes, and Roberto Cipolla. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE international conference on computer vision, pages 2938–2946, 2015. 1, 2, 5
[6] Zhang, Ji, and Sanjiv Singh. "LOAM: Lidar Odometry and Mapping in Real-time."Robotics: Science and Systems. Vol. 2. No. 9. 2014.

一、背景 ? 我们大部分人的编程习惯都是线性编程,所谓线性编程就是一个请求涉及...
本文转载自公众号读芯术(ID:AI_Discovery) 如果你即将要面临大型科技公司的技术...
最近,在为 Coco 优化分层架构之时,我陷入了各种决策困难之中。所以我通过不断...
游戏市场的热度已经不言而喻,随着民众生活水平的提升,大家对于精神娱乐生活的...
开源 RPC 框架有哪些呢?一类是跟某种特定语言平台绑定的,另一类是与语言无关即...
一、数据中台是真的热 在2018年之前可能只有一少部分人在谈中台,从2018年下半年...
来源 | 阿里飞天CIO学堂微信公众号 金融数字化转型过程中,市场的细微变化,客户...
为了使伸缩组自动加入的实例自动部署应用,您需要创建私有镜像,确保该镜像上有...
计算的下一步发展是什么,将如何影响组织的战略?专家预测了边缘计算在2021年的发...
与普通的IDC机房或服务器厂商相比,阿里云提供的云服务器ECS具有高可用性、安全...

