


目录
一、Python 命名规范
二、发送 get 请求
1.安装 requests
cmd 中安装 requests:
安装:pip install requests
卸载:pip uninstall requests
查看:pip list
切记安装的时候把抓包工具关了。
如果安装报错 timeout,因为没 fq,可以这样装:
- pip install -i http://mirrors.aliyun.com/pypi/simple/ requests
附上国内常见的镜像源
requests 官方文档:https://requests.readthedocs.io/zh_CN/latest/
2.发送 get 请求
一个完整的 get 请求,应该包括请求行(url)和请求头(headers)、请求参数(params)。
- import requests
- # get请求:url+params请求参数
- url="http://v.juhe.cn/laohuangli/d"
- # params 建议参数单独拿出来,这样写
- p={"key":"abf91475fc19f66c2f1fe567edd75257",
- "date":"2014-09-11"}
- a=requests.get(url,params=p) #发请求
- print(a.status_code)#状态码
- print(a.text)#raw 文本内容
- print(a.headers)#dict
- print(a.headers['Date'])#key
- print(a.cookies)#RequestsCookieJar
3.如何判断发送 get 请求要不要传请求头部?
先在 fiddler 中去掉请求头部,用这个接口发下请求试试,如果是正常返回 200 就可以不传头部,如果在工具中发送请求后,提示 403 - Forbidden: Access is denied,那么就需要传头部。
请求头中那么多参数,哪些参数需要呢?
在工具中把请求头中的参数挨个删掉试试,不行的话就要加上了。
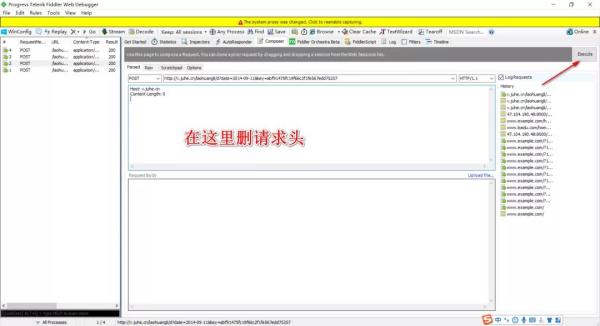
这个是看开发怎么实现的了,自己写接口自动化代码的时候最好写上请求头,这样规范一些。
4.传入请求头
头部写成字典格式,headers=headers,传入请求头。
有些响应内容是 gzip 压缩的,text 只能打印文本内容,用 content 是二进制流。一般获取返回值内容,推荐用 content。
- import requests
- url="https://www.baidu.com"
- # 构建请求头
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36'
- }
- r=requests.get(url,headers=headers)
- print(r.status_code)
- print(r.text)# html乱码
- print(r.content.decode("utf-8")) #decode解压缩展示中文
5.权限被拒:403 - Forbidden: Access is denied
url 和请求参数都对,却没权限。可能原因:服务器识别到你是代码请求的,防脚本机制。
解决办法:需要身份验证,代码中的请求头部加上 cookies)。例如:
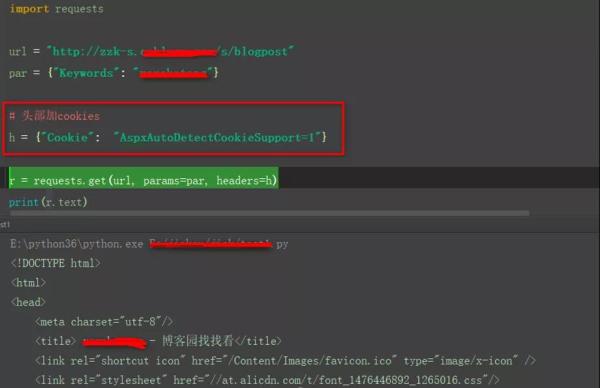
图片来自网络
三、response 的返回内容还有其它更多信息
注:本篇文章写的是用代码发送简单的 get 请求,我有自己整理笔记的习惯,虽然网上这类的教程很多,但是坑也很多,自己写的自己看放心一些。不喜勿喷,如有需要,自行抱走,后续会更新深入一些的文章。
本文转载自微信公众号「清菡软件测试」,可以通过以下二维码关注。转载本文请联系清菡软件测试公众号。


来源 | 阿里飞天CIO学堂微信公众号 金融数字化转型过程中,市场的细微变化,客户...
游戏市场的热度已经不言而喻,随着民众生活水平的提升,大家对于精神娱乐生活的...
一、数据中台是真的热 在2018年之前可能只有一少部分人在谈中台,从2018年下半年...
本文转载自公众号读芯术(ID:AI_Discovery) 如果你即将要面临大型科技公司的技术...
一、背景 ? 我们大部分人的编程习惯都是线性编程,所谓线性编程就是一个请求涉及...
计算的下一步发展是什么,将如何影响组织的战略?专家预测了边缘计算在2021年的发...
最近,在为 Coco 优化分层架构之时,我陷入了各种决策困难之中。所以我通过不断...
开源 RPC 框架有哪些呢?一类是跟某种特定语言平台绑定的,另一类是与语言无关即...
为了使伸缩组自动加入的实例自动部署应用,您需要创建私有镜像,确保该镜像上有...
与普通的IDC机房或服务器厂商相比,阿里云提供的云服务器ECS具有高可用性、安全...

