

https://github.com/Ccww-lx/JavaCommunity
在实际的工作项目中, 缓存成为高并发、高性能架构的关键组件 ,那么Redis为什么可以作为缓存使用呢?首先可以作为缓存的两个主要特征:
在分层系统中处于内存/CPU具有访问性能良好,
缓存数据饱和,有良好的数据淘汰机制
由于Redis 天然就具有这两个特征,Redis基于内存操作的,且其具有完善的数据淘汰机制,十分适合作为缓存组件。
其中,基于内存操作,容量可以为32-96GB,且操作时间平均为100ns,操作效率高。而且数据淘汰机制众多,在Redis 4.0 后就有8种了促使Redis作为缓存可以适用很多场景。
那Redis缓存为什么需要数据淘汰机制呢?有哪8种数据淘汰机制呢?
Redis缓存基于内存实现的,则其缓存其容量是有限的,当出现缓存被写满的情况,那么这时Redis该如何处理呢?
Redis对于缓存被写满的情况,Redis就需要缓存数据淘汰机制,通过一定淘汰规则将一些数据刷选出来删除,让缓存服务可再使用。那么Redis使用哪些淘汰策略进行刷选删除数据?
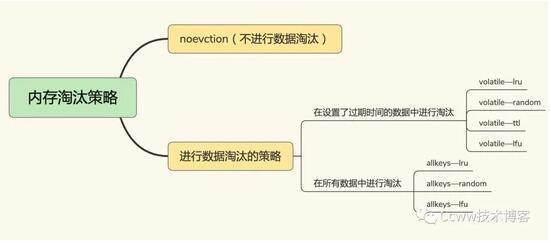
在Redis 4.0 之后,Redis 缓存淘汰策略6+2种,包括分成三大类:
不淘汰数据
noeviction ,不进行数据淘汰,当缓存被写满后,Redis不提供服务直接返回错误。
在设置过期时间的键值对中,
volatile-random ,在设置过期时间的键值对中随机删除
volatile-ttl ,在设置过期时间的键值对,基于过期时间的先后进行删除,越早过期的越先被删除。
volatile-lru , 基于LRU(Least Recently Used) 算法筛选设置了过期时间的键值对, 最近最少使用的原则来筛选数据
volatile-lfu ,使用 LFU( Least Frequently Used ) 算法选择设置了过期时间的键值对, 使用频率最少的键值对,来筛选数据。
在所有的键值对中,
allkeys-random, 从所有键值对中随机选择并删除数据
allkeys-lru, 使用 LRU 算法在所有数据中进行筛选
allkeys-lfu, 使用 LFU 算法在所有数据中进行筛选
Note: LRU( 最近最少使用,Least Recently Used)算法, LRU维护一个双向链表 ,链表的头和尾分别表示 MRU 端和 LRU 端,分别代表最近最常使用的数据和最近最不常用的数据。
LRU 算法在实际实现时,需要用链表管理所有的缓存数据,这会带来额外的空间开销。而且,当有数据被访问时,需要在链表上把该数据移动到 MRU 端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
其中,LRU和LFU 基于Redis的对象结构 redisObject 的 lru 和 refcount 属性实现的:
- typedef struct redisObject {
- unsigned type:4;
- unsigned encoding:4;
- // 对象最后一次被访问的时间
- unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
- * LFU data (least significant 8 bits frequency
- // 引用计数 * and most significant 16 bits access time). */
- int refcount;
- void *ptr;
- } robj;
Redis 的 LRU 会使用 redisObject 的 lru 记录最近一次被访问的时间,随机选取参数 maxmemory-samples 配置的数量作为候选集合,在其中选择 lru 属性值最小的数据淘汰出去。
在实际项目中,那么该如何选择数据淘汰机制呢?
优先选择 allkeys-lru 算法,将最近最常访问的数据留在缓存中,提升应用的访问性能。
有顶置数据使用 volatile-lru 算法 ,顶置数据不设置缓存过期时间,其他数据设置过期时间,基于LRU 规则进行筛选 。
在理解了Redis缓存淘汰机制后,来看看Redis作为缓存其有多少种模式呢?
Redis缓存模式基于是否接收写请求,可以分成只读缓存和读写缓存:
只读缓存:只处理读操作,所有的更新操作都在数据库中,这样数据不会有丢失的风险。
Cache Aside模式
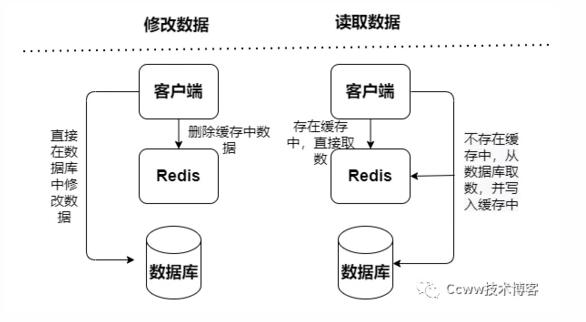
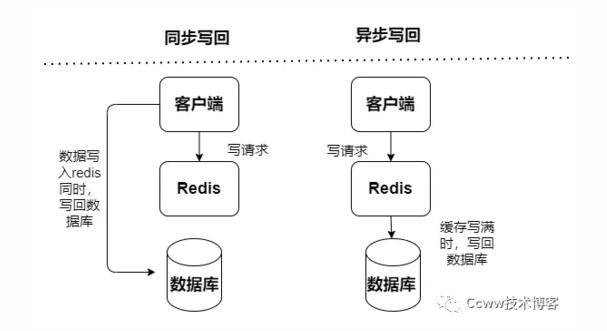
读写缓存,读写操作都在缓存中执行,出现宕机故障,会导致数据丢失。缓存写回数据到数据库有分成两种同步和异步:
同步:访问性能偏低,其更加侧重于保证数据可靠性
Read-Throug模式
Write-Through模式
异步:有数据丢失风险,其侧重于提供低延迟访问
Write-Behind模式

【51CTO.com快译】 数据可视化工具不断发展,提供更强大的功能,同时改善可访问...
前提条件 请您在购买前确保已完成注册和充值。详细操作请参见 如何注册公有云管...
建站 什么 虚拟主机 够用?这要看搭建的是什么类型的网站。比如个人博客类型的网...
从 10.0.0 版开始,异步迭代器就出现在 Node 中了,在本文中,我们将讨论异步迭...
2021年3月24日,主题为《数据的世界,世界的数据》的星环科技2021春季新品发布会...
在Python语言中有如下3种方法: 成员方法 类方法(classmethod) 静态方法(staticm...
摘要 元旦期间 订单业务线 告知 推送系统 无法正常收发消息,作为推送系统维护者...
Docker生成新镜像版本的两种方式 There are two ways Docker can generate new m...
信息化2.0时代提出开展智慧教育创新发展行动。2019年2月,中共中央、国务院印发...
本文整理自直播《Hologres 数据导入/导出实践-王华峰(继儒)》 视频链接: https:/...

