

在系统设计中,会用到消息中间件来做服务异步化,系统解耦,或者是做流量削峰,常用的消息中间件有rabbitMq,activeMq以及阿里的RocketMq等等,都各自有各自的优势,但是就吞吐量来说,kafka是其中的佼佼者。在单机情况下,网友做的对比如下:

为什么kafka会这么快呢?
发布订阅模式
一个普通的发布订阅模型如下图所示:
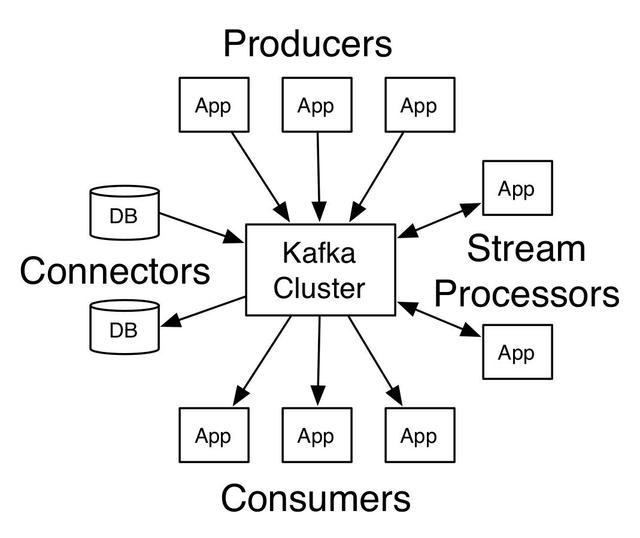
以kafka为例,生产者产生消息,并将消息Push到kafka集群,消费者主动去kafka集群Pull数据。这种模型有个好处,消费的速率完全由消费者控制,kafka集群类似于一个蓄水池,避免因生产者产生消息过快消费者来不及消费而导致消费者被压垮的现象。
kafka为什么快要从两方面分析,生产者产生的消息写入集群时快和消费者消费消息时从集群读取快。
写入快
写入快主要是两方面原因:顺序写入和MMFile。
顺序写入
kafka将消息存储在硬盘,通常认为硬盘的读写是比较慢,但是为什么kafka快呢?平时所说的磁盘读写慢是指随机读写比较慢,因为磁盘每次随机读写都要物理寻址,这是非常耗时的操作,顺序读写的速度还是比较快的。如下图所示:

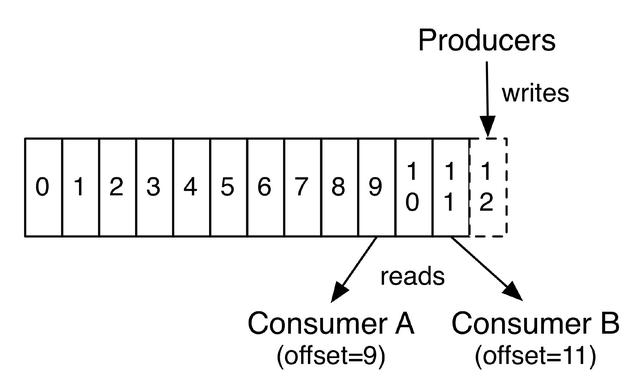
kafka每次收到新的消息之后都会将消息存储在尾部,按照顺序存储消息。但是消息一旦存储无法删除。
当消费者消费时也是顺序消费,每个消费者会有一个偏移量,记录当前消费的消息的位置。如下图所示:
MMFile
MMFile是指Memory Mapped Files,即内存映射技术。操作系统为了解决内存和硬盘读写速度之间的差异,采用了内存映射技术,内存被划分为若干页,每一页被映射到一块磁盘空间,因为内存是远远小于磁盘空间的,所以分页经常会按照一定的算法加载到内存,例如先进先出(FIFO),最近最少使用(LRU)等。内存中分页和磁盘空间对应,操作系统会在合适的时候将内存分页中的数据定时刷磁盘中去。这种方式为什么可以提高写入效率呢?通常CPU执行过程中为了安全分为内核态和用户态。只有内核态才能操作iO设备,内存空间分为内核空间和用户空间。通常内存中的数据写入到磁盘要以下几步:
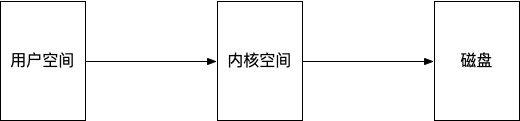
数据会先从用户空间拷贝到内核空间,然后再由内核空间写入IO设备。而MMFile则省去了一次用数据从户空间到内核空间复制的开销。
读取快
读取快主要是因为零拷贝(Zero Copy)技术。上面介绍到数据从内存空间写入磁盘的步骤,那么从磁盘读取数据刚好相反,具体过程如下:

数据先从磁盘读取到内核空间,然后再从内核空间复制到用户空间,然后再到Socket,最后传输到消费者。
Linux提供了一种sendFile系统调用,可以将数据直接由磁盘拷贝到内核空间。省去了一次数据从用户空间到内核空间的复制。这就是所谓的零拷贝技术。
上面从读写两个角度分析了为什么kafka吞吐量高,其实还有一个重要的原因。
批量数据压缩
kafka不会对每个消息都做压缩,而是对一批消息压缩,然后将数据统一发送。将所有的消息变为一个批量文件,然后直接丢给消费者。
综上所述,kafka通过MMFile技术快速将数据顺序写入磁盘,在读取时通过零拷贝技术快速读取,然后通过批量数据压缩将数据传输到消费者。这就是kafka快的秘诀。然而鱼与熊掌不可兼得,速度和可靠性不可能同时满足,需要根据实际业务情况在二者之间作出取舍。例如当用kafka做日志聚合和网站用户行为分析时速度要比可靠性重要,而在某些消息不允许丢失的场景,可靠性可能是首选。

2021年3月24日,主题为《数据的世界,世界的数据》的星环科技2021春季新品发布会...
信息化2.0时代提出开展智慧教育创新发展行动。2019年2月,中共中央、国务院印发...
建站 什么 虚拟主机 够用?这要看搭建的是什么类型的网站。比如个人博客类型的网...
摘要 元旦期间 订单业务线 告知 推送系统 无法正常收发消息,作为推送系统维护者...
从 10.0.0 版开始,异步迭代器就出现在 Node 中了,在本文中,我们将讨论异步迭...
Docker生成新镜像版本的两种方式 There are two ways Docker can generate new m...
本文整理自直播《Hologres 数据导入/导出实践-王华峰(继儒)》 视频链接: https:/...
在Python语言中有如下3种方法: 成员方法 类方法(classmethod) 静态方法(staticm...
【51CTO.com快译】 数据可视化工具不断发展,提供更强大的功能,同时改善可访问...
前提条件 请您在购买前确保已完成注册和充值。详细操作请参见 如何注册公有云管...

