


在深度学习模型的部署中,最难处理的是大体积的机器学习依赖安装以及深度学习模型参数的储存问题。通常而言,机器学习的库大小能接近1G,而深度模型一般也有100M起步。对于函数计算来说,为了减少平台的冷启动,都会设置代码包大小限制,阿里云的函数计算代码包必须在100MB以内。因此,我们需要一个云存储来解决依赖调用与模型参数加载的问题。在本示例中,我们使用NAS(Network Attached Storage)来存放我们的依赖与模型。NAS,简单来说说就是连接在网络上,具备资料存储功能的储存系统,我们可以通过挂载的方式对NAS进行访问。
开通阿里云NAS服务,并创建一个文件系统,根据业务需求我们可以选择不同的配置。将获得的NAS地址写入配置,并将VPC设置为自动。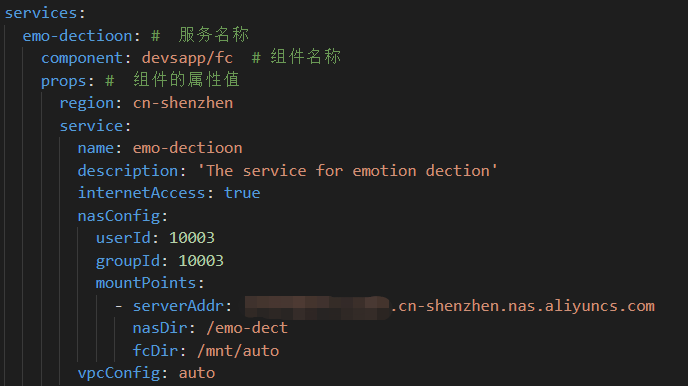
简单来说,我们可以将基于serverless devs的工程分成三个部分。.s文件夹中存放部分配置文件,以及我们build出来的依赖和代码;src文件夹存放我们的源代码和深度学习模型参数;s.yaml文件存放我们对函数计算的配置。

其中,src文件夹的index.py文件一般存放我们的函数入口,这里给出部分示例代码。在本项目中,我们需要对用户上传的图片进行处理。为了方便获取图片,这里我们使用flask框架。需要注意的是,对于每次执行都会进行的操作如加载模型参数,为了减少模型推理时间,我们将其放置在initialize函数中,这样这段代码只会被执行一次。
# -*- coding: utf-8 -*-
import logging
import numpy as np
from PIL import Image
import io
from skimage.transform import resize
import torch as torch
import torch.nn.functional as F
from flask import Flask, request
from models import VGG
import transforms as transforms
net = VGG('VGG19')
class_names = ['Angry', 'Disgust', 'Fear',
'Happy', 'Sad', 'Surprise', 'Neutral']
logger = logging.getLogger()
app = Flask(__name__)
def initialize(context):
# Get parameters from NAS
ROOT_DIR = r'/mnt/auto/'
# ROOT_DIR = r''
MODEL_PATH = ROOT_DIR + 'vgg_emo_dect.t7'
# Load the VGG network
logger.info('load the model ...')
checkpoint = torch.load(
MODEL_PATH, map_location=torch.device('cpu'))
net.load_state_dict(checkpoint['net'])
net.eval()
@app.route("/", methods=["POST", "GET"])
def predict():
logger.info('processing ...')
# get the image buffer
image = request.files.get('file').read()
# transform it to the np array
image_data = np.array(Image.open(io.BytesIO(image)))
# return the final result
inputs = preprocess(image_data)
score, predict = infer(inputs)
res = dict(zip(class_names, score.tolist()))
logger.info(class_names[int(predict)])
res['pred'] = class_names[int(predict)]
return res本地调试由于本地的调试环境与远程的函数计算环境往往不同,为了兼容性,我们最好使用Docker拉取函数计算远程镜像进行调试。
下载docker(如果本机没有docker的话)使用命令s build --use-docker进行依赖安装使用命令s local invoke/start进行本地调试。
构建简单测试,对本地接口进行调用,示例测试代码:
import requests
files = {'file':('1.jpg',open('1.jpg','rb'),'image/jpg')}
url = 'http://localhost:7218/2016-08-15/proxy/emo-dectioon/get-emotion/'
res = requests.post(url=url, files=files)
print(res.text)上传依赖与模型参数上传依赖与模型参数到NAS上传依赖:s nas upload -r .s/build/artifacts/emo-dectioon/get-emotion/.s/python nas:///mnt/auto/python上传模型:s nas upload src/vgg_emo_dect.t7 nas:///mnt/auto


上传成功后,我们可以在代码中简单使用路径获取对应文件:)
模型部署在本地调试时,我们模型参数和依赖的路径都是本地路径。现在,我们要将这些路径转化为NAS的路径,并删去本地模型参数和调试生成的依赖(不然因代码包过大而无法进行部署)。需要注意的是,对于依赖,我们需要修改python的引用路径,这体现在我们的配置文件中:
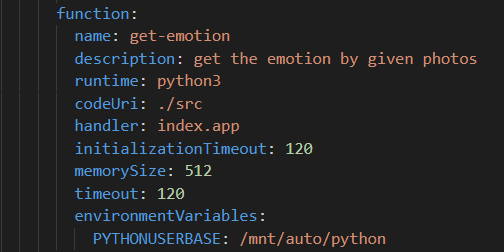
接着,运行命令s depoly即可将代码部署到远程:

用上述测试代码调用远程接口进行测试:

完整代码链接:Emotion Dection: The AI model deployment based on Serverless Devs

本文作者 吴数傑 阿里云智能 开发工程师 1. 概述 本文主要讲解MaxCompute Spark...
域名 过期多少天可以注册?域名过期大概60天以后会被注册局删除,删除之后就可以...
上一篇介绍了MFCCs提取的原理和流程,本文介绍使用python实现MFCCs。 回顾下MFCC...
在如今信息化高速发展的时代,服务器已经成为很多企业必不可少的设备,对于什么...
大家在开发Python的过程中,一定会遇到很多反斜杠的问题,很多人被反斜杠的数量...
什么是 域名 赎回?域名到期后会有0-30天左右的域名续费期,每个后缀的续费期可...
疫情之下,所有的行业都失去了运转惯性。为了有效防控疫情,社区封闭、门店关停...
一些站长朋友问“ 虚拟主机100M有多大 ”,虚拟空间主要是存放网站的文件和资料...
可能每个人都听说过Docker,并且大多数开发人员都熟悉并使用过Docker,诸如构建D...
作者 贺科学 技术一号位不是岗位 更多的是技术人员在公司中做事的一种心态 这个...


