


深度学习和神经网络并不简单,但好在面试官能测试的数量有限。在梳理了数百个数据科学面试问题之后,本文总结出了10个最常出现的深度学习概念。话不多说,让我们开始吧!
1.激活函数(Activation Functions)
如果你对神经网络及其结构的还没有基本了解,那么建议阅读Terence Shin的文章《神经网络初学者指南》(“A Beginner-Friendly Explanation of How Neural Networks Work”)。
对神经元或节点有基本了解之后,你就会发现激活函数像电灯开关一样,能够决定是否激活神经元。
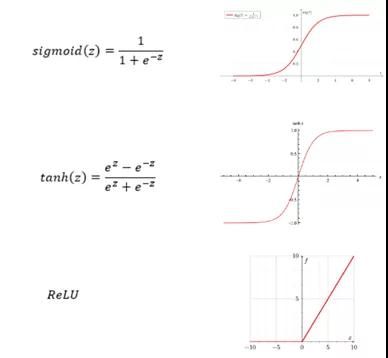
激活函数有几种类型,但是最流行的激活函数是整流线性单元函数,也称为ReLU函数。ReLU函数优于S型函数和双曲正切函数函数,因为它执行梯度下降的速度更快。
请注意,在图像中,当x(或z)很大时,斜率非常小,这会显著减缓梯度下降,但这种情况不会出现在ReLU函数中。
2.代价函数(Cost Function)
神经网络的代价函数类似于其他机器学习模型的成本函数。它衡量的是神经网络的预测值与实际值相比有多“好”。代价函数与模型的质量成反比——模型质量越高,代价函数越低,反之亦然。
代价函数是最优化值。通过缩小神经网络的代价函数,可以获得模型的最佳权重和参数,从而最大程度地发挥模型的性能。
有几种常用的代价函数,包括二次方代价(quadratic cost)、交叉熵成本(cross-entropy cost)、指数成本(exponential cost)、Hellinger distance、Kullback-Leibler散度等。
3.反向传播算法(Backpropagation)
反向传播算法是一种与成本函数密切相关的算法。具体来说,它是一种用于计算成本函数梯度的算法。与其他算法相比,反向传播速度快、效率高,因而备受欢迎。
在这个算法中,梯度的计算从权重的最后一层的梯度开始,然后反向传播到权重的第一层梯度。因此,第k层的误差取决于k + 1层。“反向传播”也因此得名。
通常,反向传播的工作原理如下:
4.卷积神经网络(Convolutional Neural Networks)
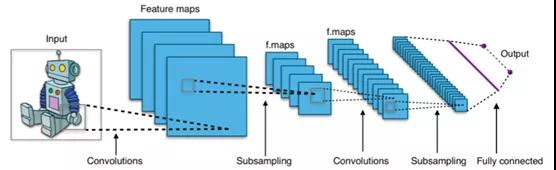
卷积神经网络(CNN)是一种神经网络,它提取输入信息(通常是图像),按照重要程度将图像的不同特征进行分类,然后输出预测。CNN优于前馈神经网络的原因在于,它可以更好地捕获整个图像的空间(像素)依赖性,这意味着它可以更好地理解图像的组成。
CNN使用一种称为“卷积”的数学运算。维基百科这样定义卷积:对两个函数的数学运算产生了第三个函数,该函数表示一个函数的形状如何被另一个函数修改。因此,CNN在其至少一层中使用卷积代替通用矩阵乘法。
5.循环神经网络(Recurrent Neural Networks)
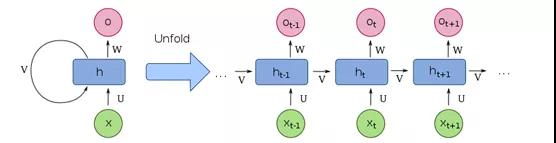
循环神经网络(RNN)是另一种神经网络,能够摄取各种大小的输入信息,因此可与序列数据配合使用,效果极佳。RNN既考虑当前输入也考虑先前给定的输入,这意味着相同的输入在技术上可以基于先前的给定输入产生不同的输出。
从技术上讲,RNN是一种神经网络,其中节点之间的连接沿时间序列形成有向图,从而使它们可以使用其内部存储器来处理可变长度的输入序列。
6.长短期记忆网络(Long Short-Term Memory Networks)
长短期记忆网络(LSTM)是一种递归神经网络,可弥补常规RNN的一大劣势:短期记忆。
具体来说,如果序列太长,即滞后时间大于5-10个步长,则RNN倾向于忽略先前步骤中提供的信息。例如,如果我们将一个段落输入RNN,则它可能会忽略该段落开头提供的信息。为了解决这个问题,LSTM诞生了。
7.权重初始化(Weight Initialization)
权重初始化的要点是保证神经网络不会收敛到无效解。如果权重全部初始化为相同的值(例如零),则每个单元将获得完全相同的信号,并且每一层的输出都是一样的。
因此,你要随机初始化权重,使其接近零,但不等于零。用于训练模型的随机优化算法就要达到这样效果。
8.批量梯度下降和随机梯度下降(Batch vs. Stochastic Gradient Descent)
批量梯度下降和随机梯度下降是用于计算梯度的两种不同方法。
批量梯度下降仅使用整个数据集计算梯度。特别是对于较大的数据集,它要慢得多,但对于凸或平滑误差流形来说效果更好。
在随机梯度下降的情况下,一次使用单个训练样本来计算梯度。因此,它的计算速度更快且成本更低。然而,在这种情况下达到全局最优值时,它趋向于反弹。这会产生好的解决方案,但不是最优解决方案。
9.超参数(Hyper-parameters)
超参数既是调节网络结构的变量,也是控制网络训练方式的变量。常见的超参数包括:
10.学习率(Learning Rate)
学习率是神经网络中使用的超参数,每次更新模型权重时,神经网络都会控制该模型响应估计的误差调整模型的数量。
如果学习率太低,则模型训练将进行得非常缓慢,因为每次迭代中对权重进行的更新最少。因此,在达到最低点之前需要进行多次更新。如果将学习率设置得太高,则由于权重的急剧更新,会对损失函数造成不良的发散行为,并且可能无法收敛。
以上就是深度学习中最常出现的10个概念。认真学习这10个概念,将有助于你在深度学习领域奠定坚实的基础。希望这对你的面试有所帮助。
本文转载自微信公众号「读芯术」,可以通过以下二维码关注。转载本文请联系读芯术公众号。


本节通过调用一系列IMS的API使用 云服务器 来创建私有镜像。 API的调用方法请参...
自1804年穿孔卡片可编程式提花织机问世,编程语言已经存在200多年。人类社会奔涌...
对于企业级用户,如果客户仅是香港、台湾、日本客户,建议选择香港服务器, 因为...
数据映射是数据处理的重要组成部分。 数据映射中的一个错误可以在组织中引起连锁...
本文转载自微信公众号「石杉的架构笔记」,作者崔皓。转载本文请联系石杉的架构...
提到DevOps这个词,相信很多人一定不会陌生。 作为一个热门的概念,DevOps近年来...
今天下午,在2020年腾讯 Techo Park 开发者大会上,腾讯云联合英特尔、VMware威...
挂机用什么 云服务器 ?很多游戏玩家,对挂机可能耳熟能详,大家平常忙,会需要...
在Cortex Building Intelligence中从学习到将机器学习投入生产的五个要点 在过去...
云服务器 ftp是什么东西? 云服务器 ftp是用于上传文件到云服务器,或是下载云服...


