


大家好,今天总结了一下老生常谈的 JVM,这也是面试必问的知识。
话不多说,整起来!
一、JVM 是什么?
1、Java 虚拟机(Jvm)是可运行 Java 代码的假想计算机。
2、Jvm 充当着一个翻译官的角色,我们平常所编写出的 Java 程序,是不能够被操作系统所直接识别的,这时候 JVM 的作用就体现出来了,它负责把我们的程序翻译给系统“听”,告诉它我们的程序需要做什么操作。
3、Jvm 针对每个操作系统开发其对应的解释器,所以只要其操作系统有对应版本的 Jvm,那么这份 Java 编译后的代码就能够运行起来,有句话大家一定听说过:「Java 能一次编译到处运行」,这就是原因所在。
二、Jvm 的体系架构?
Jvm 是这四部分组成:
下面就聊聊这四个部分~~
2.1 运行区数据
Java 虚拟机在执行 Java 程序的过程中会把它所管理的内存划分为若干个不同的数据区域,这些区域各有各的作用,各有各的生命周期。
有些区域随着虚拟机进程的启动而存在,有些区域则依赖用户线程的启动和结束建立和销毁。
运行区数据的划分:方法区、虚拟机栈,本地方法栈、堆、程序计数器
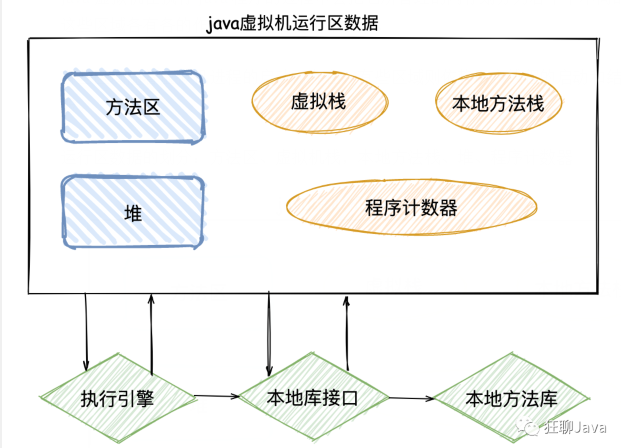
上面这张图大家一定都见过,其实可以划分的更细点,看下面的这两张图:
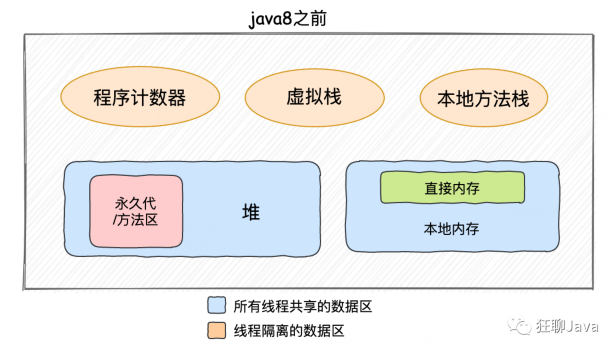
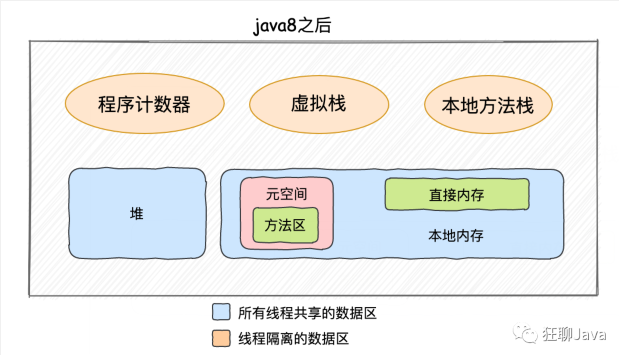
能看出 1.8 版本前后的差别么,下面就看看这些区域都干啥的~~
程序计数器
特点:1、占用很小的内存 2、各线程私有
就比如下面字节码一样,每一行开头的黄色数字,我们就可以认为它是程序计数器所存储的内容:
- public void doSth1();
- descriptor: ()V
- flags: ACC_PUBLIC
- Code:
- stack=2, locals=3, args_size=1
- 0: ldc #5
- 2: dup
- 3: astore_1
- 4: monitorenter
- 5: getstatic #2
- 8: ldc #3
- 10: invokevirtual #4
- 13: aload_1
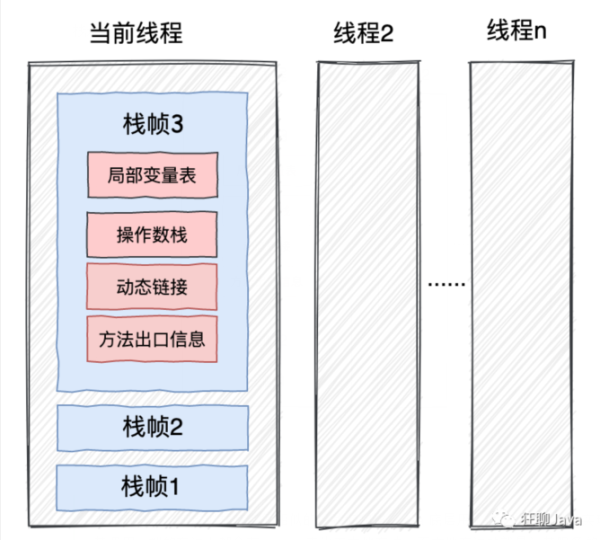
虚拟机栈
特点:1、随线程而生、随线程而死 2、先进后出
栈示意图:
本地方法栈
特点:1、各线程私有 2、和本地方法有关
native 修饰的方法:
- public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
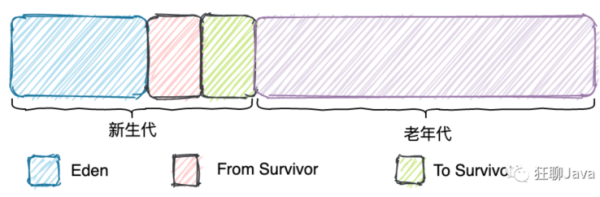
堆
特点:1、所有线程共享 2、占用大的内存空间 3、先进先出
堆的划分:
方法区
特点:1、所有线程共享 2、1.8 之后移到了元空间 3、涉及到常量池
直接内存
从上面的图中,看到有直接内存这个区域
2.2 类加载器
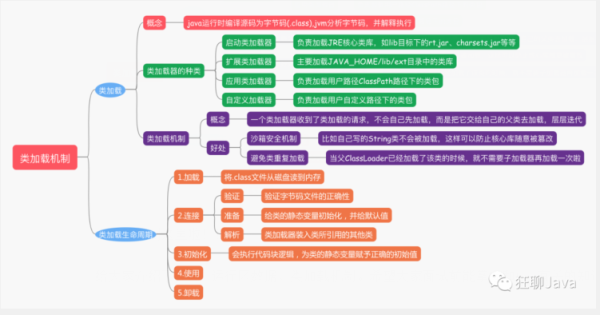
1、什么是类加载机制?
JVM 运行时,java 虚拟机会把描述类的数据从 Class 文件加载到内存,并对数据进行校验、转换、解析和初始化,最终形成可以被 jvm 可以直接使用的类型,这就是类加载机制。
2、说说类加载的过程?
开局一张图:
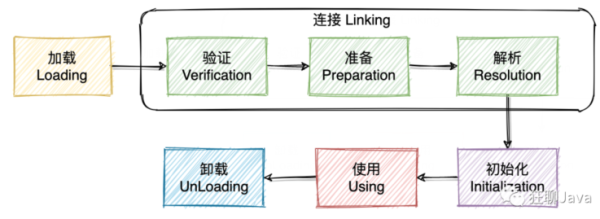
这张图说明了类从加载到虚拟机内存开始,到卸载出内存为止,它的整个生命周期。
一般来说,我们把 Java 的类加载过程分为三个主要步骤:加载、链接、初始化,具体行为在 Java 虚拟机规范里有非常详细的定义。
1、首先是加载阶段
2、第二阶段是链接,这是核心的步骤,简单说是把原始的类定义信息平滑地转化入 JVM 运行的过程中。这里可进一步细分为三个步骤:
① 验证
② 准备
这里的初始化是指:
1、8 种基本数据类型的默认初始值是 0。
2、引用类型默认的初始值是 null。
3、对于有 static final 修饰的常量会直接赋值,例如:static final int x=123;则 x 直接会初始化为 123。
③ 解析
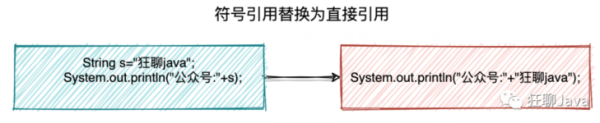
3、最后是初始化阶段
这一步真正去执行类初始化的代码逻辑,包括静态字段动作,以及执行类定定义中的静态初始化块内的逻辑编译器在编译阶段就会把这部分逻辑整理好,父类型的初始化逻辑优先于当前类型的逻辑。
初始化顺序:
三、什么时候会对类进行初始化?
通过 new 关键字实例化对象、读取或设置类的静态变量、调用类的静态方法
通过反射发生上面的三种行为
初始化子类时,会触发父类的初始化
作为程序入口运行,就是指的 main 方法
四、类加载器有哪些?
启动类加载器:负责加载环境变量下 jre/lib 下面的 jar 文件
扩展类加载器:负责加载环境变量下 jre/lib/ext 目录下面的 jar 包
应用类加载器:就是加载我们熟悉的 classpath 的内容
自定义加载器:继承 ClassLoader 就可以实现
五、了解双亲委派模型吗?
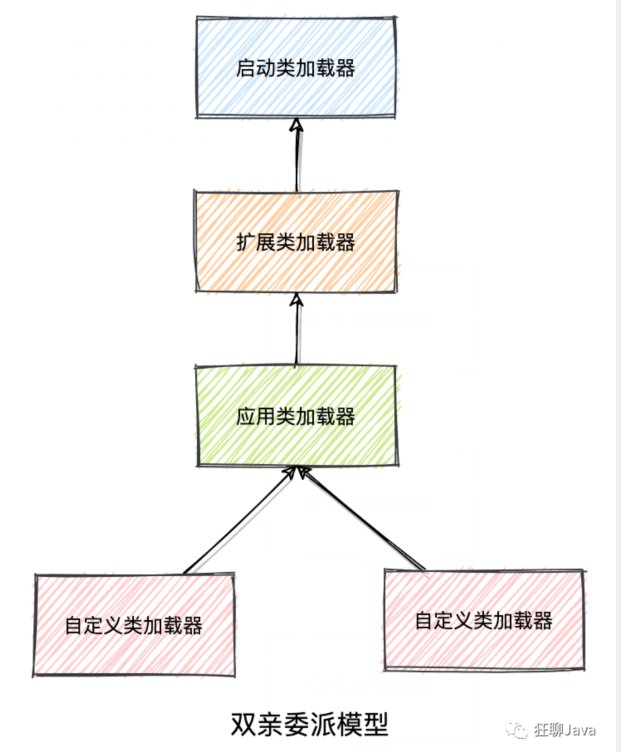
这是一张很经典的图,通常情况下,各个类加载器的协作关系就是这样的。
概念:就是说一个类加载器收到了类加载的请求,不会自己先加载,而是把它交给自己的父类去加载,层层迭代。
用上图来说明就是如果应用程序类加载器收到了一个类加载的请求,会先给扩展类加载器,然后再给启动类加载器,如果启动类加载器无法完成这个类加载的请求,再返回给扩展类加载器,如果扩展类加载器也无法完成,最后才会到应用类加载器。
好处:1、避免重复加载 Java 类型 2、沙箱安全机制:保证核心的类不会被篡改。
六、classLoader与class.forName区别
七、脑图
最后送大家一张自己总结的脑图呀
今天就写到这里啦!!
给大家介绍了JVM、运行区数据、类加载机制。希望大家面试前能掌握和Jvm有关的知识。


建站 什么 虚拟主机 够用?这要看搭建的是什么类型的网站。比如个人博客类型的网...
从 10.0.0 版开始,异步迭代器就出现在 Node 中了,在本文中,我们将讨论异步迭...
【51CTO.com快译】 数据可视化工具不断发展,提供更强大的功能,同时改善可访问...
Docker生成新镜像版本的两种方式 There are two ways Docker can generate new m...
本文整理自直播《Hologres 数据导入/导出实践-王华峰(继儒)》 视频链接: https:/...
摘要 元旦期间 订单业务线 告知 推送系统 无法正常收发消息,作为推送系统维护者...
信息化2.0时代提出开展智慧教育创新发展行动。2019年2月,中共中央、国务院印发...
前提条件 请您在购买前确保已完成注册和充值。详细操作请参见 如何注册公有云管...
在Python语言中有如下3种方法: 成员方法 类方法(classmethod) 静态方法(staticm...
2021年3月24日,主题为《数据的世界,世界的数据》的星环科技2021春季新品发布会...

