

Lambda Architecture 概念
Mathan Marz的大作Big Data: Principles and best practices of scalable real-time data systems介绍了Lambda Architecture的概念,用于在大数据架构中,如何让real-time与batch job更好地结合起来,以达成对大数据的实时处理。
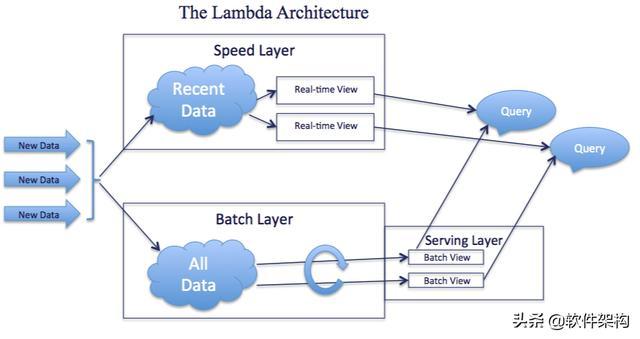
大数据平台中包括批量计算的Batch Layer和实时计算的Speed Layer,通过在一套平台中将批计算和流计算整合在一起。
例如使用Hadoop MapReduce、Spark进行批量数据的处理,使用Apache Storm、Spark Streaming 进行实时数据的处理。
这种架构在一定程度上解决了不同计算类型的问题,但是带来的问题是框架太多,会导致平台复杂度过高、运维成功高等。
Lambda架构的主要思想就是将大数据系统构建为多个层次,如下图所示:
我们来梳理一下他们是如何分工协助的:
基于Lambda架构,一旦数据通过Batch layer进入到Serving layer,在Real-time view中的相应结果就不再需要了。
小 结
Lambda架构结合了实时处理与批处理的结果,很好的反馈了查询需求,并且在速度和可靠性之间求取了平衡,具有足够的扩展性。理想状态下,所有的查询都可以定位成一个函数:
- Query = Function(Data)
但是,若数据达到相当大的一个级别(例如PB),且还需要支持实时查询时,就需要耗费非常庞大的资源。
而Lambda架构将数据和计算系统进行细分:
- Query = Batch(Old_Data) + RealTime(New_Data)
但是这种架构同样存在一些问题:需要运维两套不同的计算系统,并且合并查询结果,这一定程序上带来了复杂性的增加。

9月17日,2020云栖大会上,阿里云正式发布工业大脑3.0。 阿里云智能资深产品专家...
定义 this是函数运行时自动生成的内部对象,即调用函数的那个对象。(不一定很准...
很长时间没有更新原创文章了,但是还一直在思考和沉淀当中,后面公众号会更频繁...
本文转载自网络,原文链接:https://mp.weixin.qq.com/s/vlOUg46B5bcmToX-fjavJQ...
最近,DevOps的采用导致了企业计算的重大转变。除无服务器计算,动态配置和即付...
中国最?好的一朵云飘进了华瑞银行。阿里云将进一步助力华瑞银行All in Cloud。 -...
在TOP云(zuntop.com)科技租赁过服务器的站长都知道独立服务器在价格上比VPS主...
一、PostgreSQL行业位置 一 行业位置 首先我们看一看RDS PostgreSQL在整个行业当...
查看表结构,sbtest1有主键、k_1二级索引、i_c二级索引 CREATE TABLE `sbtest1` ...
2020年对于云计算行业来说是突破性的一年,因为公共云供应商增加了收入,而疫情...

