


本文转载自微信公众号「codeasy」,作者阎华。转载本文请联系codeasy公众号。
用UOW模式实现Repository
看了《无法实施富领域模型的罪魁祸首找到了》这一篇文章后,很多人都会问这种Repository是这么实现的。这种Repository的实现背后用了一个叫做 “Unit of Work (UOW)”的模式:
Maintains a list of objects affected by a business transaction and coordinates the writing out of changes and the resolution of concurrency problems.Unit of Work --Martin Fowler
UOW模式是在业务用例的操作中跟踪对象的所有更改(增加、删除和更新),并将所有更改的对象保存在一个列表中。在业务用例的终点,通过事务,一次性提交所有更改,以确保数据的完整性和有效性。总而言之,UOW协调这些对象的持久化及并发问题。
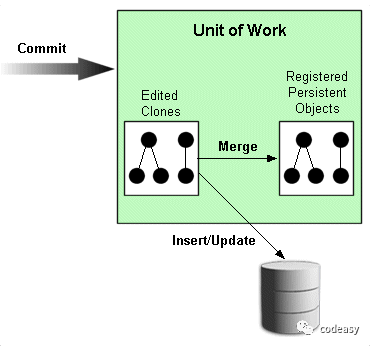
很多实现了UOW模式的框架都采用了保存快照的方式来跟踪对象状态的变化,如上图所示,通过对比开始时对象的状态和编辑后的对象的状态,从而决定如何更新数据库。这样做的好处是可以增量按需更新。
重点是最后一次性保存变更,跟踪对象状态的变更不是必须的,我们看看IDDD_Sample是怎么实现的。
IDDD_Sample使用了LevelDB来存储数据,以 agilepm.port.adapter.persistence.LevelDBSprintRepository 为例:
- void save(Sprint aSprint, LevelDBUnitOfWork aUoW) {
- LevelDBKey primaryKey = new LevelDBKey(PRIMARY, aSprint.tenantId().id(), aSprint.sprintId().id());
- aUoW.write(primaryKey, aSprint);
- }
其中 LevelDBUnitOfWork 的write方法是这么实现的:
- public void write(LevelDBKey aKey, Object aValue) {
- String serializedValue = this.serializer.serialize(aValue);
- this.batch.put(aKey.keyAsBytes(), serializedValue.getBytes());
- }
它把整个聚合序列化后存储了。由于没有跟踪对象变更,所以也无法实现增量的更新,只能粗暴地用最新的聚合序列化后完全覆盖之前的聚合存储了。 但这种方式对我们大部分场景参考性不大,一个原因是我们最常用的还是关系型数据库, 另一个原因是这种非增量的更新开销还是比较大的。
合适的就是最好的,我有个朋友曾用MongoDB作存储,使用了这样的模式,效果很好,他所做的那个应用数据量不大,并发不高,用这种方式大大节约了开发和维护的成本。
那我们看看当使用关系型数据库的时候有什么框架可以选择。
使用JPA实现Repository
JPA (Java Persistence API) 是一个Java 持久化规范,最流行的一个实现是Hibernate,它可以大大简化对数据库的操作,然而,JPA在国内不受待见:
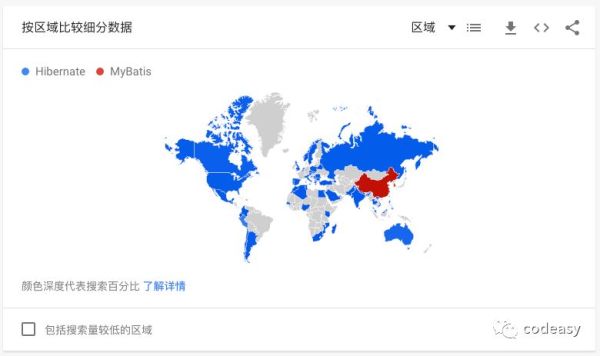
国内外使用Hibernate和MyBatis的对比
然而要实现UOW模式的Repository,使用JPA依然是最佳选择,你几乎不用自己做任何的工作,只要把聚合中的对象和表映射好就可以了。
JPA/Hibernate还提供了易用的乐观锁功能,在聚合根上维护一个乐观锁非常简单
JPA/Hibernate在国内不受待见的一个重要原因,不是它不好用,而是太好用了——隐藏了很多实现细节有时候显得不太灵活,提供了太多的高级功能用不好容易踩坑。
所以,使用JPA,请遵循以下几点建议:
嫌弃JPA不够精简的人很多,以至于Spring的官方推出了 Spring-Data-JDBC,一个专门为DDD的聚合存储设计的ORM框架,它比JPA轻量很多,简单很多,然而,为了轻量简单,它也没有对对象状态修改进行跟踪,所以在保存聚合的时候无法像JPA一样按需更新数据库,而是如IDDD_Sample一样,粗暴地覆盖更新,甚至会先删除聚合下所有子实体后再重新插入(无论子实体数据有没有变更),这可能会带来不可控的性能问题。
如果我们又想用关系数据库,又不能使用JPA,那还有别的办法吗?
自己写代码实现资源库
前段时间我尝试过一种方法:自己手写Repository的实现,在聚合保存前,先从库里load出来一个聚合,把这两个聚合里的对象进行比较(diff),找出差异,生成操作数据库的SQL语句,去增量更新数据库。
这样做的问题是需要写很多的Repository代码,而且很容易出错也不容易维护,我试图做一些抽象来简化代码,最后发现抽象越多越像JPA了。
这样做还有一个问题是需要在保存前额外加载一次,如果想避免这个问题,可以看看《DDD之聚合持久化应该怎么做?| https://zhuanlan.zhihu.com/p/334344752》,但这种方法还是没有避免需要写很多代码的问题。
自己编码实现的好处是可控,比如容易处理分库分表的问题。但实现起来太复杂,编写和维护成本高,也容易出问题,这大大打击了使用富领域模型的热情。
总之,实现Repository,还没有一件称手的家伙。
再次审视端口适配器模型
前面我们提到过DDD提倡的六边形模型,即端口适配器模型,Repository就是一个例子。比如接口 agilepm.domain.model.product.sprint.SprintRepository 这是一个接口,即所谓的端口,它和领域对象在同一个包里;而 agilepm.port.adapter.persistence.LevelDBSprintRepository这个实现是在另外的叫 adapter 的包下,这背后体现的是依赖倒置原则,这样可以让领域层和应用层不依赖于具体的技术实现。
Repository的实现只是一种adapter,下一篇我们讲一讲如何访问另一个上下文中的服务,那本质上也是一种port/adapter,但有更多的不一样的细节需要注意。

本文转载自微信公众号「沉默王二」,可以通过以下二维码关注。转载本文请联系沉...
提到响应式三个字,大家立刻想到啥?响应式布局?响应式编程? 从字面意思可以看...
背景 最近对负责的项目进行了一次性能优化,其中包括对 JVM 参数的调整,算是进...
看了火箭和勇士的G6大战,最终火箭3比4出局。 在火箭的近五年季后赛,一共有四次...
为了提高大家开发 React 项目的效率, 笔者结合自己的实际工作经验, 汇总如下Reac...
swagger 在 egg 项目中的最佳实践 Write By CS逍遥剑仙 我的主页: csxiaoyao.com...
随着科技和工业的发展,空间中存在大量的无意电磁辐射,如汽车点火器辐射、电晕...
一次性购买 域名 买断多少钱?域名是无法一次性买断的,可以一次注册多年,一次...
如今全球网络的高速发达,依托后端采用多种操作系统平台的WEB服务器,提供用户丰...
2021年3月,物联网安全服务示范系统边缘版(阿里云IoT安全管理一体机)率先通过...

