


在 pandas 中,DataFrame 是我们经常用到的工具。有时候,我们可能会需要对数据按某个字段进行分组,然后每个组取N项。例如:

现在,我想每个职位任取三个用户。
相信有同学会使用 for 循环,依次循环每一行,每个职位选3个,存入一个临时的列表里面。循环完成以后再转成一个新的 DataFrame。但这个方式显然不够智能。
那么,我们有没有什么办法能够不使用循环就做到这一步呢?也许有同学想到了使用 groupby。我们来看看效果。
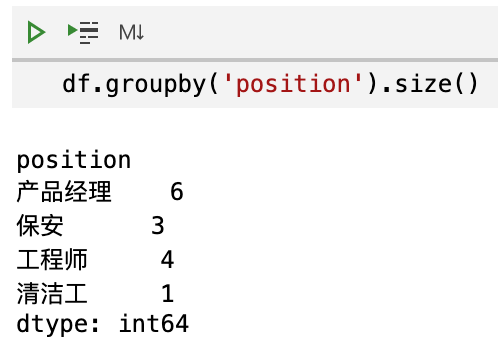
看起来仅仅是统计了每个职位的数量。那么,如何才能保留所有字段呢?
实际上我们可以把.size()改成.head(3):
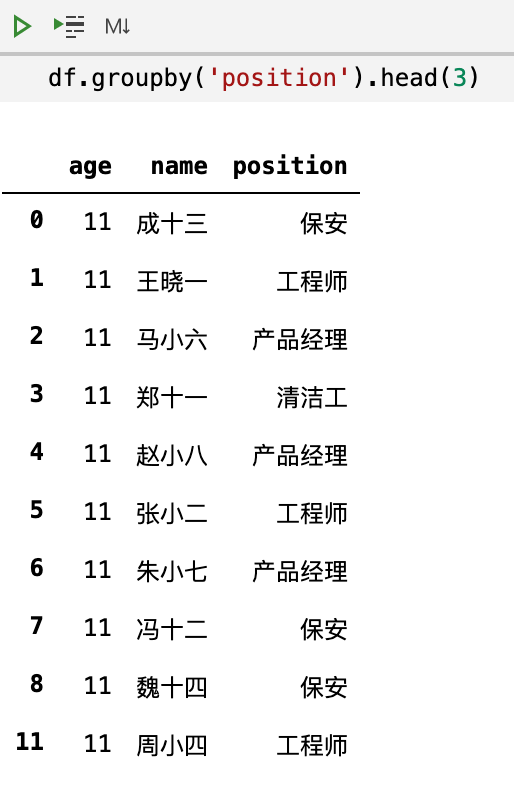
看起来这里的.head(3)似乎没有什么作用。这个时候,我们思考一下 Python 里面,如果要使用itertools.groupby,官方文档里面有这样一段话:
Generally, the iterable needs to already be sorted on the same key function.
如下图所示:

这段话告诉我们,要使用itertools.groupby,我们需要提前对被分组的字段进行排序。
那么,我们试一试在如果提前对 DataFrame 进行排序,然后再 groupby 会怎么样:

成功了。每个职位都取了3个。
可能大家发现最左边的索引是乱序,看起来不好看。那么我们还可以重设一下索引:

至此,问题完美解决。
本文转载自微信公众号「未闻Code」,可以通过以下二维码关注。转载本文请联系未闻Code公众号。


桥接模式 我走进她的房间,发现她正在看电视剧. 最近好像觉醒年代很火,大家都在看...
本文的英文原标题是「10 Rules of Dashboard Design」,其中 Dashboard 如果翻译...
域名 联系不到商家怎么实名制?域名的实名认证是在 域名注册 服务商处进行,提供...
TOP云 (west.cn)1月6日消息,今天早晨一枚7字符的杂米 域名 178good.online在T...
前言 今天继续二叉树相关的算法题 题目 输入某二叉树的前序遍历和中序遍历的结果...
据ResearchAndMarkets发布的边缘计算分析报告,在全球范围内,边缘计算市场将在...
背景1.?什么是Terraform Terraform是一种开源工具 用于安全高效地预览 配置和管...
案例背景 一场突如其来的新冠病毒肺炎疫情,让在无数在备考阶段的高三学子陷入苦...
作者|李小平 前天我参加了信通院的云原生产业大会,参加会议的企业非常多,并且...
中小型企业较为青睐虚拟主机,原因就在于它的价格以及操作方便等方面,另外,选...

