

本章节将介绍在第七代高主频ECS实例上,利用Analytics Zoo和第三代智能英特尔?至强?可扩展处理器提供的bfloat16特性提高人工智能应用的性能。
背景信息
- 阿里云第七代高主频ECS实例构建于第三代神龙平台之上,基于第三代智能英特尔?至强?可扩展处理器创建。相对于上一代,阿里云ECS云服务器第七代高主频实例计算性能最大可以提升260%。在ECS上使用Analytics Zoo,可以利用Analytics Zoo的高级流水线特性,比如使用英特尔优化的深度学习框架(例如TensorFlow、PyTorch等)开发深度学习应用。
- 第三代智能英特尔?至强?可扩展处理器提供了业界领先、经工作负载优化的平台,并内置了AI加速功能--增强型英特尔?Deep Learning Boost(英特尔?DL Boost)。增强型英特尔?DL Boost通过业界首次对bfloat16的x86支持,增强了人工智能推理和训练性能。
第三代智能英特尔?至强?可扩展处理器可运行复杂的人工智能工作负载。增强型英特尔?DL Boost将人工智能训练最高提升1.93倍,图像分类性能最高提升1.87倍,自然语言处理的训练性能提升1.7倍,推理提升1.9倍。新的bfloat16处理支持使医疗保健、金融服务和零售业的人工智能训练工作负载受益匪浅。
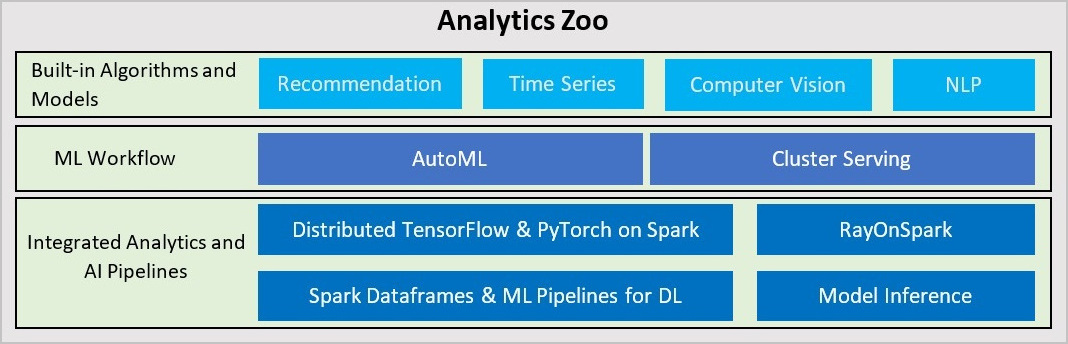
- Analytics Zoo是英特尔开源的统一的大数据和AI平台,它可以无缝的将TensorFlow、Keras、PyTorch等AI程序扩展到分布式Spark、Flink、Ray等大数据平台上运行。Analytics
Zoo提供了以下特性:
- 为基于TensorFlow、PyTorch、OpenVINO等的AI模型提供运行在大数据平台之上的端到端的流水线。例如开发者可以在Spark代码中嵌入TensorFlow或者PyTorch代码,进行分布式的训练和推理。开发者可以在Spark ML流水线中使用原生的深度学习支持如TensorFlow、Keras、PyTorch、BigDL等。
- 为自动化的机器学习任务提供了高级ML工作流支持,例如自动的TensorFlow、PyTorch、OpenVINO等模型的分布式推理Cluster Serving以及可扩展的时序数据预测的AutoML功能。
- 内置提供了Recommendation、Time Series、CV、NLP等应用常用的模型。
- bfloat16是一种业界广泛用于神经网络的数字格式。
- Resnet50是一个50层的残差网络(Residual Network),该神经网络广泛用于目标分类等领域。
操作步骤
如果您想在ECS上使用Analytics Zoo对人工智能应用进行bfloat16加速,按照以下步骤在ECS上加速人工智能应用:
步骤一:创建高主频ECS实例
完成以下操作,创建一台ECS实例。
- 在实例列表中,找到创建的实例,单击实例ID。查看并确认实例规格。
步骤二:在ECS上准备带有bfloat16优化支持的Analytics Zoo环境
Analytics Zoo提供了预先创建的支持bfloat16的docker image,按照方法一可以轻松在阿里云ECS上获取Analytics Zoo的docker image。您也可以按照方法二使用Analytics Zoo nightly build来支持bfloat16。相关代码说明请参见代码示例:Analytics Zoo如何利用bfloat16加速深度模型训练。
- 方法一:在ECS上获取Analytics Zoo预先创建的docker image创建。
- 连接ECS实例。具体步骤,请参见连接ECS实例。
- 运行以下命令安装并运行Docker。
yum install docker-io -y systemctl start docker - 运行以下命令获取支持bfloat16的Analytics Zoo docker image。
docker pull intelanalytics/analytics-zoo:0.8.1-bigdl_0.10.0-spark_2.4.3-bf16 - 运行以下命令运行docker container。
docker run -itd --name az1 --net=host --privileged intelanalytics/analytics-zoo:0.8.1-bigdl_0.10.0-spark_2.4.3-bf16 - 运行以下命令进入container。
docker exec -it az1 bash
- 方法二:用户使用Analytics Zoo nightly build来支持bfloat16手动创建。
- 连接ECS实例。具体步骤,请参见连接ECS实例。
- 运行以下命令下载并解压最新的Analytics Zoo nightly build pre-build package。
wget https://oss.sonatype.org/content/repositories/snapshots/com/intel/analytics/zoo/analytics-zoo-bigdl_0.11.1-spark_2.4.3/0.9.0-SNAPSHOT/analytics-zoo-bigdl_0.11.1-spark_2.4.3-0.9.0-20201026.210040-51-dist-all.zip unzip analytics-zoo-bigdl_0.11.1-spark_2.4.3-0.9.0-{datetime}-dist-all.zip -d analytics-zoo - 运行以下命令安装git。
yum -y install git - 运行以下命令下载TensorFlow源代码。
git clone https://github.com/Intel-tensorflow/tensorflow.git git checkout v1.15.0up1 - 运行以下命令编译TensorFlow。
bazel build --cxxopt=-D_GLIBCXX_USE_CXX11_ABI=0 --copt=-O3 --copt=-Wformat --copt=-Wformat-security --copt=-fstack-protector --copt=-fPIC --copt=-fpic --linkopt=-znoexecstack --linkopt=-zrelro --linkopt=-znow --linkopt=-fstack-protector --config=mkl --define build_with_mkl_dnn_v1_only=true --copt=-DENABLE_INTEL_MKL_BFLOAT16 --copt=-march=native //tensorflow/tools/lib_package:libtensorflow_jni.tar.gz //tensorflow/java:libtensorflow.jar //tensorflow/java:libtensorflow-src.jar //tensorflow/tools/lib_package:libtensorflow_proto.zip - 运行以下命令整理Analytics Zoo需要的库文件。
cd bazel-bin/tensorflow/tools/lib_package mkdir linux-x86_64 tar -xzvf libtensorflow_jni.tar.gz -C linux_x86-64 rm libtensorflow_framework.so rm libtensorflow_framework.so.1 mv libtensorflow_framework.so.1.15.0 libtensorflow_framework-zoo.so cp ../../../../_solib_k8/_U@mkl_Ulinux_S_S_Cmkl_Ulibs_Ulinux___Uexternal_Smkl_Ulinux_Slib/* ./ - 运行以下命令更新Analytics Zoo Jar。
cd ~/analytics-zoo/lib/ cp ~/tensorflow/bazel-bin/tensorflow/tools/lib_package/linux-x86_64 ./ jar -ufanalytics-zoo-bigdl_0.11.1-spark_2.4.3-0.9.0-SNAPSHOT-jar-with-dependencies.jar linux-x86_64/*
步骤三:在ECS实例上训练Resnet50模型和bfloat16的性能提升
代码示例:Analytics Zoo如何利用bfloat16加速深度模型训练
下面的代码用于说明Analytics Zoo如何利用bfloat16来加速深度学习模型的训练(例如Resnet50等)。在Analytics Zoo的docker image中已经包含,您不需要任何操作,仅作示例参考。


