

可以使用 config 文件指定多个任务和依赖关系,然后使用下面的命令提交:
bcs sub --file job.cfg # 文件名可以随意定
job.cfg 内容:
[taskname]cmd=python test.pyjob_name=democluster=img=img-ubuntu:type=ecs.sn1.mediumdescription=test jobnodes=1pack=./src/read_mount=oss://bucket/input/:/home/input/write_mount=oss://bucket/output/:/home/output/
config 文件也可以配置多个任务,可以指定任务间依赖关系。
job.cfg 内容:
[DEFAULT]job_name=log-countdescription=demoforce=Truedeps=split->count;count->merge#下面是任务公共配置env=public_key:value,key2:value2read_mount=oss://bucket/input/:/home/input/write_mount=oss://bucket/output/:/home/output/pack=./src/[split]cmd=python split.pycluster=img=img-ubuntu:type=ecs.sn1.mediumnodes=1[count]cmd=python count.pycluster=img=img-ubuntu:type=ecs.sn1.mediumnodes=3[merge]cmd=python merge.pycluster=img=img-ubuntu:type=ecs.sn1.mediumnodes=1
如果DAG如下:
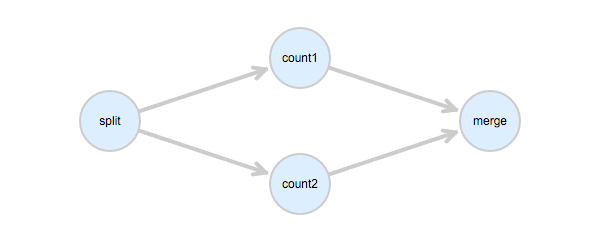
则deps配置:
deps=split->count1,count2;count1->merge;count2->merge
每个dep是一对多的形式: task1->task2,taks3
多个task之间用逗号隔开,多个dep用分号隔开。
./src/|-- split.py|-- ...
如果指定目录:pack=./src/, 则打包src下面的所有文件到 worker.tar.gz, 指定cmd时,需要从 ./src/目录下开始指定,如: cmd=python split.py
如果指定文件: pack=./src/split.py, 则只打包文件到worker.tar.gz, 指定cmd时,只需要指定文件名, 如: cmd=python split.py
pack可以在[DEFAULT]这个section中配置,也可以在每个task中配置, 当然也可以在命令行中指定。
read_mount 为只读挂载,将oss目录挂载到运行程序的虚拟机的文件系统中,linux可以挂载为一个目录,window下只能挂载为一个Driver,如:”E:”。
如果挂载多个,可以使用英文逗号隔开,如:read_mount=oss://bucket/input/:/home/input/,oss://bucket/input2/:/home/input2/。write_mount和mount也是如此。
write_mount 为可写挂载,将oss目录映射到运行程序的虚拟机的目录,只能映射为一个目录,如果这个目录不存在,需要程序创建一下。写入到这个目录的所有文件将会被上传到相应的oss目录。
mount可以用于 NAS 的挂载,比如:
mount=nas://xxxxxx-yyy50.cn-shenzhen.nas.aliyuncs.com:/:/home/mnt/:truevpc_id=vpc-xxxxxxxxxxyyyyyyvpc_cidr_block=192.168.0.0/16
注意:使用 NAS 时要指定 vpc_id 和 cidr_block。
这里mount信息中的 true/false 指的是是否支持可写。
有2种格式:
AutoCluster格式:
cluster=img=<img-id>:type=<instance-type>
AutoCluster指定任务运行时会自动创建相应配置的集群,运行完成后自动释放掉。
Cluster格式:
cluster=<cluster-id>
运行:bcs c 可以查看我的集群,如果没有,可以自行创建。
如:
bcs cc <cluster-name> -i <img-id> -t <instance-type> -n 3
使用集群可以大大缩短作业启动时间,但是由于集群是一直运行着的,会一直计费,请自行权衡。
格式如:
docker=myubuntu@oss://bucket/dockers/
使用docker,需要支持docker的ImageId才能运行成功。如果你没有指定cluster,默认的imageId是支持Docker的,或者你显式指定也行,或者使用clusterId,但是这个cluster的ImageId也要支持docker才行。
这里的myubuntu全名为:localhost:5000/myubuntu,制作docker镜像的时候,前缀必须为localhost:5000/, 因此这里可以省略掉前缀。后面的oss目录,是OSS私有docker镜像仓库目录,详情请看如何使用docker。
nodes 表示指定使用多少台虚拟机运行任务程序。
force 为 True,表示如果某台虚拟机运行程序出错,整个作业不会失败,继续运行。为False,则整个作业失败。默认为False。

反向域名解析提供通过IP地址查找域名的功能。 设置ECS服务器私网IP的反向解析,...
域名 必须实名制认证吗?分两种情况来回答这个问题,如果是目前相关管理机构明确...
调用ModifyADConnectorDirectory修改AD目录。 接口说明 仅支持状态为错误(ERROR...
在 C++ 中,对文件的读写可以通过使用输入输出流与流运算符 和 来进行。当读写文...
来源 | HaaS技术社区1、开发板介绍 N58开发板是一款搭载HaaS轻应用(JavaScript...
1. 接口描述 接口请求域名: lighthouse.tencentcloudapi.com 。 本接口(Delete...
1. 服务地址 API 支持就近地域接入,本产品就近地域接入域名为 batch.tencentclo...
信息化的快速发展带动了网络环境的不断优化,而对于现在人来说拥有服务器已经不...
理解代码的内存消耗,最关键是要知道自己所用编程语言的内存管理。 不同语言的内...
随着网络世界成为企业目前最大的市场,大数据成为他们拥有和使用的最强大的工具...

