

本文介绍如何将对象存储OSS里面的数据作为机器学习PAI的训练样本。
背景信息
本文通过OSS与PAI的结合,为一家传统的文具零售店提供决策支持。本文涉及的具体业务场景(场景与数据均为虚拟)如下:
一家传统的线下文具零售店,希望通过数据挖掘寻找强相关的文具品类,帮助合理调整文具店的货架布局。但由于收银设备陈旧,是一台使用XP系统的POS收银机,可用的销售数据仅有一份从POS收银机导出的订单记录(csv格式)。本文介绍如何将此csv文件导入OSS,并连通OSS与PAI,实现商品的关联推荐。
操作步骤
- 数据导入OSS
- 新建一个名为“oss-pai-sample”的Bucket。
- 记录其Endpoint为 oss-cn-shanghai.aliyuncs.com。
- 选择存储类型为标准存储。
说明 OSS中有三种存储类型,相关介绍请参见存储类型介绍。

- 单击Bucket名称(oss-pai-sample),然后依次单击,将订单数据Sample_superstore.csv上传至OSS。

- 上传成功,界面如下图所示:

- 创建机器学习项目
- 在控制台页面左侧选择机器学习,单击右上角的创建项目。
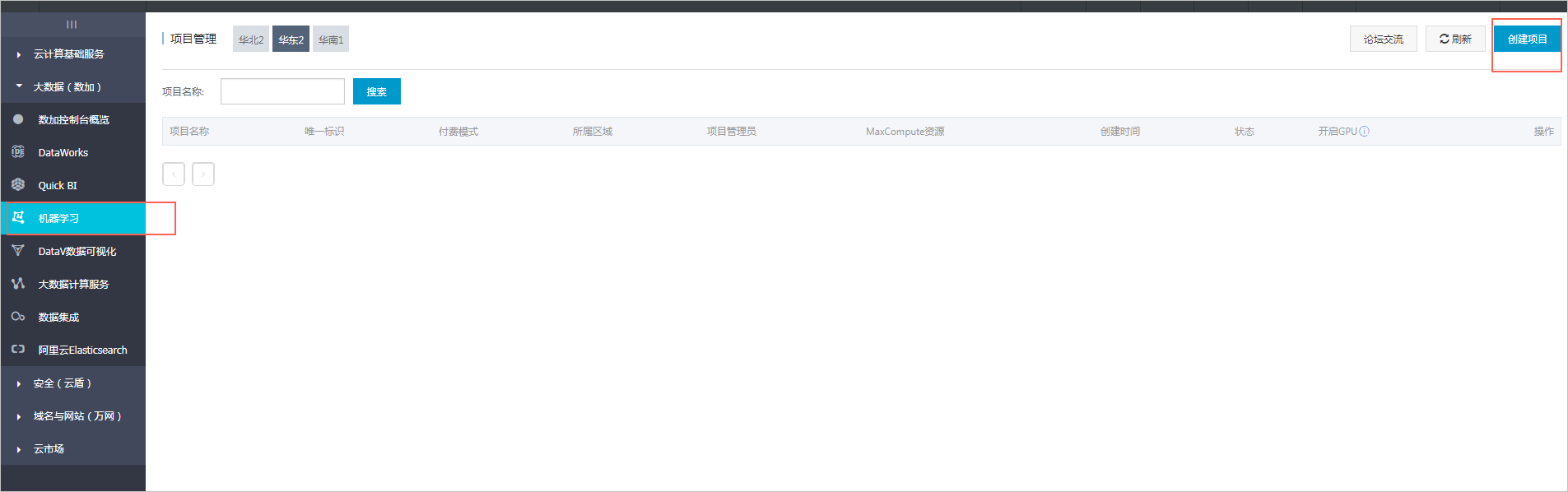
- 在显示的DataWorks新用户引导界面中,勾选region(本文中选择与OSS相同的region:华东2),并勾选计算引擎服务机器学习PAI,然后单击下一步。

- 项目创建成功后,开通服务列中会显示MaxCompute和机器学习PAI两个图标,如下图所示:
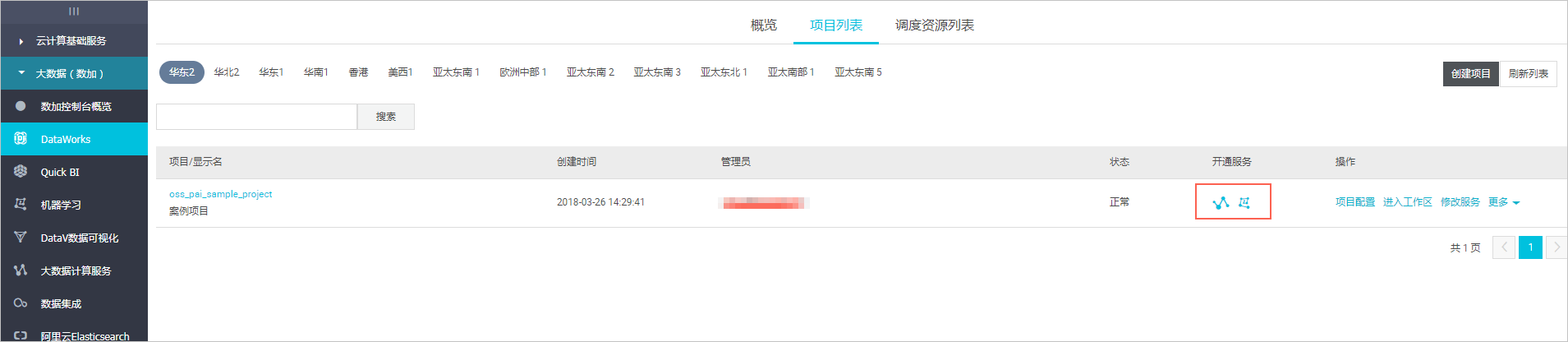
- 回到机器学习页面,点击进入机器学习。
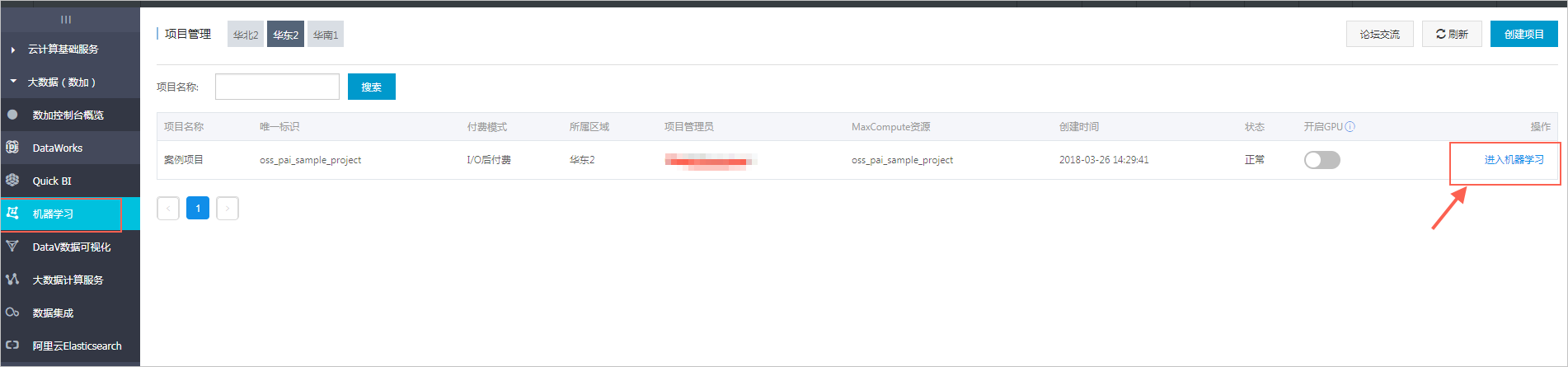
- 在控制台页面左侧选择机器学习,单击右上角的创建项目。
- 连通OSS与PAI。
- 在机器学习界面左侧选择组件,并将OSS数据同步组件拖拽至画布。
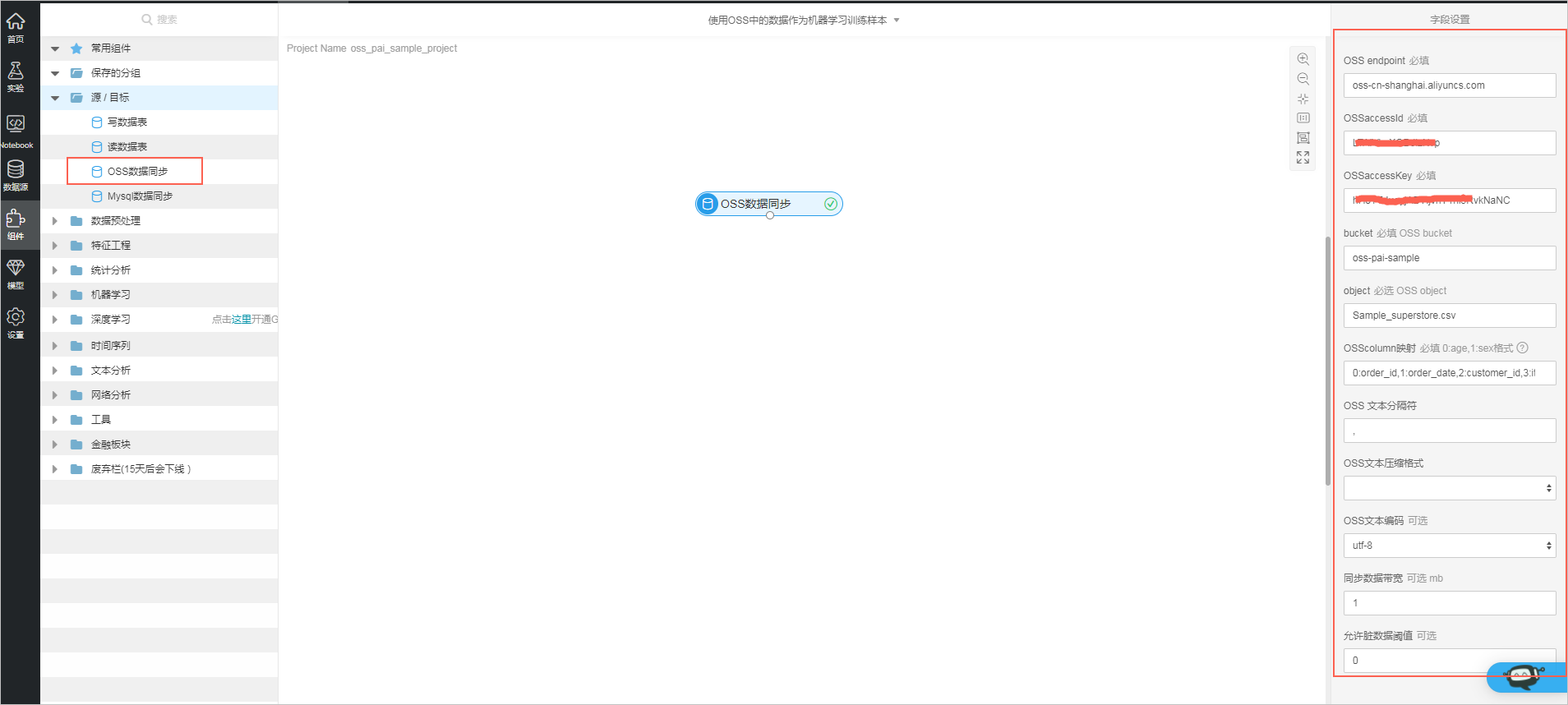
界面右侧会提示填入组件需要的以下信息:
- OSS endpoint:根据步骤一中记录的信息,endpoint 为 oss-cn-shanghai.aliyuncs.com。
-
OSSaccessId 和 OSSaccessKey 可以在对象存储OSS的界面中获取,如下图所示:
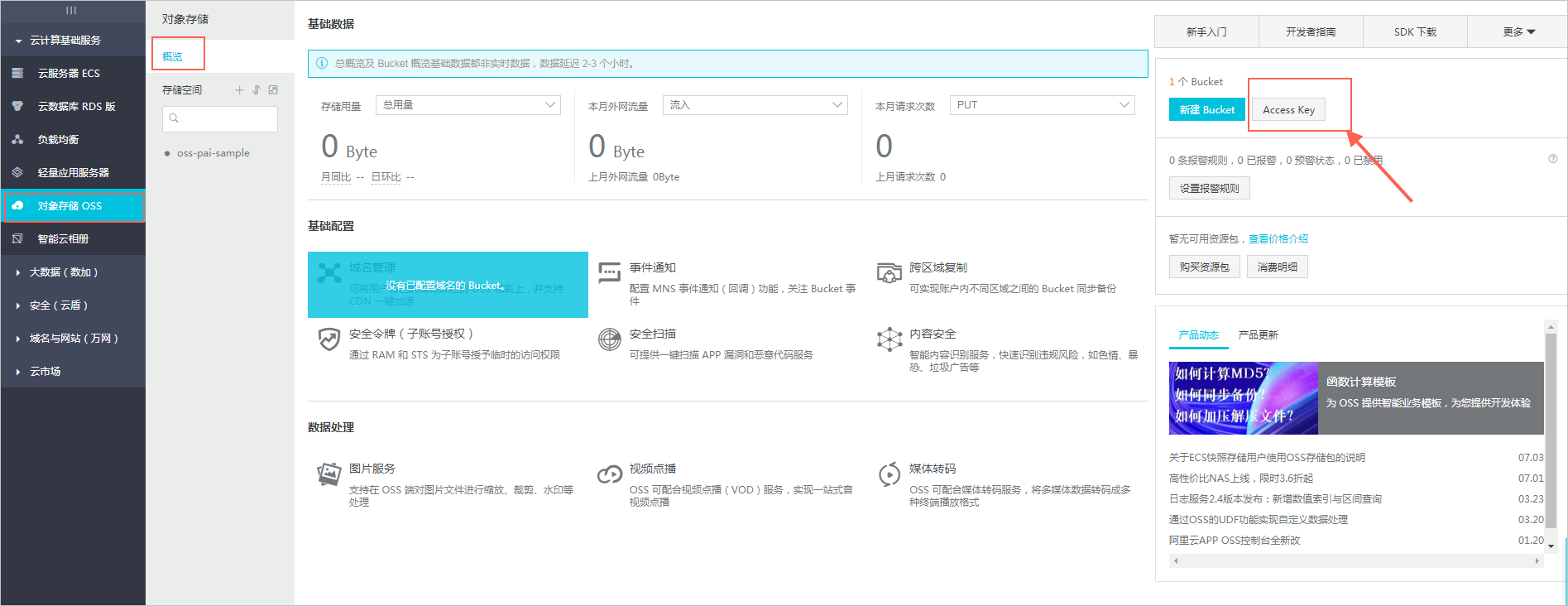

- OSSbucket 和 object 分别为 oss-pai-sample 和 Sample_superstore.csv。
- OSScolumn 映射的作用是为OSS中的csv文件增加列名。例如,虚拟数据Sample_superstore.csv共有如下6列:
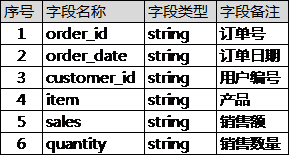
则OSScolumn映射应该填入:0:order_id,1:order_date,2:customer_id,3:item,4:sales,5:quantity
- 单击运行,成功后右键查看组件,可观察前100条数据,如下图所示:

此时OSS中的csv文件已经在MaxCompute中生成一张临时表:pai_temp_116611_1297076_1
至此,本案例最关键的步骤已经完成,OSS中的数据已经与PAI连通,可以作为机器学习的样本进行训练。
- 在机器学习界面左侧选择组件,并将OSS数据同步组件拖拽至画布。
数据探索流程
本文所用的主要算法组件为协同过滤。有关该组件的详细用法,请参见协同过滤做商品推荐。
本案例中的数据探索流程如下:
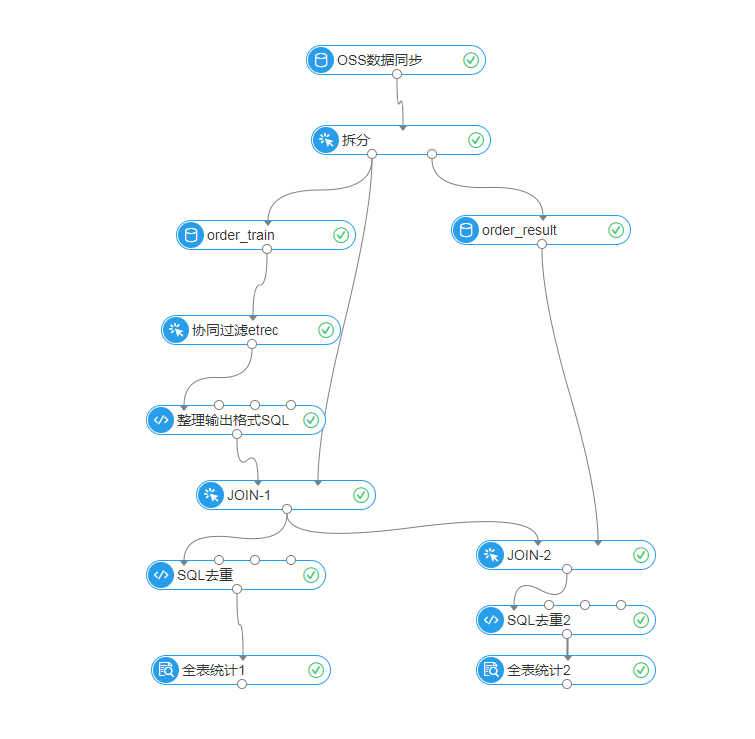
本案例按8:2的比例将源数据拆分为训练集和测试集,其中一个订单中可能有多个item,故ID列选择order_id,保证含有多个item的订单不会被拆分,如下图所示:

本案例中共有17个产品item。通过协同过滤算法组件,取相似度最高的item,结果如下表:

结论
通过机器学习,我们发现“纸张”与“订书器”二者的相似度较高,且与其它产品也有较高的相似度。
对于这家文具零售店来说,根据此数据发现可以有两种布局货架的方式:
-
纸张和订书器货架放在最中间,其它产品货架呈环形围绕二者摆放,这样无论顾客从哪个货架步入,都可以快速找到关联程度较高的纸张和订书器。
-
将纸张和订书器两个货架分别摆放在文具店的两端,顾客需要横穿整个文具店才可以购买到另外一样,中途路过其他产品的货架可以提高交叉购买率。当然,此布局方式牺牲了用户购物的便利性,实际操作中应保持慎重。


