

日志处理是一个很大范畴,其中包括实时计算、数据仓库、离线计算等众多点。这篇文章主要介绍在实时计算场景中,如何能做到日志处理保序、不丢失、不重复,并且在上下游业务系统不可靠(存在故障)、业务流量剧烈波动情况下,如何保持这三点。
为方便理解,本文使用《银行的一天》作为例子将概念解释清楚。在文档末尾,介绍日志服务LogHub功能,如何与Spark Streaming、Storm Spout等配合,完成日志数据的处理过程。
什么是日志数据?
原LinkedIn员工Jay Kreps在《The Log: What every software engineer should know about real-time data's unifying abstraction》描述中提到:append-only, totally-ordered sequence of records ordered by time。

- Append Only:日志是一种追加模式,一旦产生过后就无法修改。
- Totally Ordered By Time:严格有序,每条日志有一个确定时间点。不同日志在秒级时间维度上可能有重复,例如有2个操作GET、SET发生在同一秒钟,但对于计算机而言这两个操作也是有顺序的。
什么样的数据可以抽象成日志?
半世纪前说起日志,想到的是船长、操作员手里厚厚的笔记。如今计算机诞生使得日志产生与消费无处不在:服务器、路由器、传感器、GPS、订单、及各种设备通过不同角度描述着我们生活的世界。从船长日志中我们可以发现,日志除了带一个记录的时间戳外,可以包含几乎任意的内容,例如:一段记录文字、一张图片、天气状况、船行方向等。半个世纪过去了,“船长日志”的方式已经扩展到一笔订单、一项付款记录、一次用户访问、一次数据库操作等多样的领域。
在计算机世界中,常用的日志有:Metric、Binlog(Database、NoSQL)、Event、Auditing、Access Log 等。
在我们今天的演示例子中,我们把用户到银行的一次操作作为一条日志数据。其中包括用户、账号名、操作时间、操作类型、操作金额等。
2016-06-28 08:00:00 张三 存款 1000元
2016-06-27 09:00:00 李四 取款 20000元LogHub数据模型
为了能抽象问题,这里以阿里云日志服务下LogHub作为演示模型,详细可以参见日志服务下基本概念 。
- Log:由时间及一组Key-Value对组成。
- LogGroup:一组日志的集合,包含相同Meta(IP、Source)等。
两者关系如下。

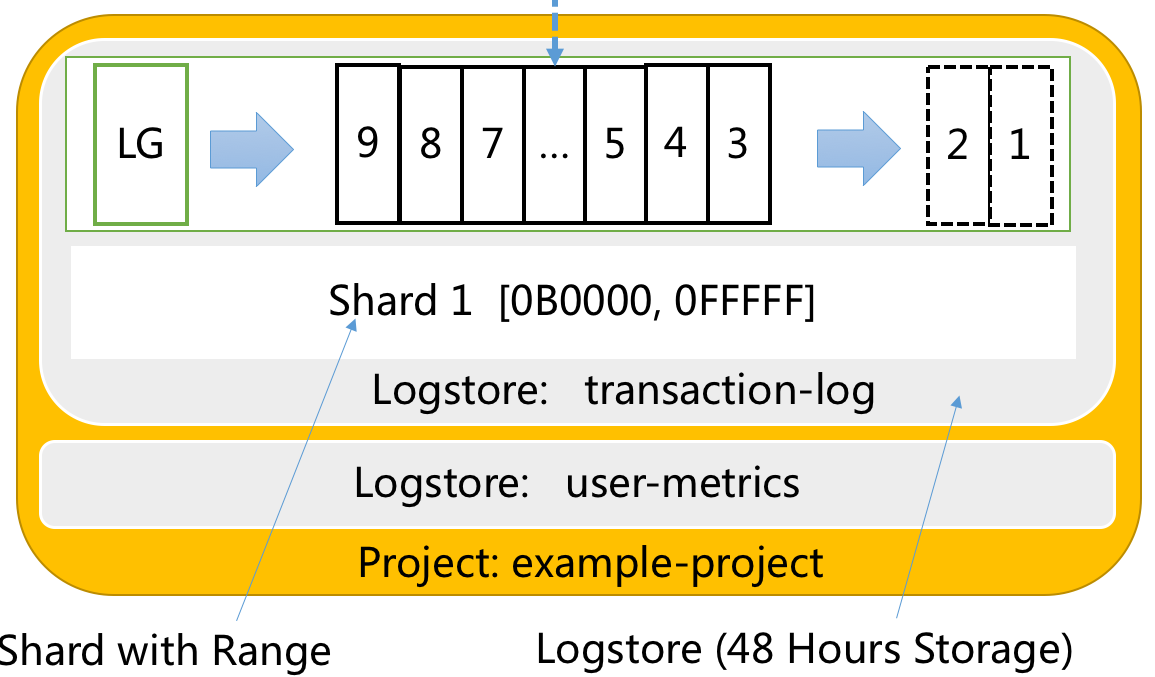
- Shard:分区,LogGroup读写基本单元,可以理解为48小时为周期的FIFO队列。每个Shard提供 5 MB/S Write,10 MB/S Read能力。Shard 有逻辑区间(BeginKey,EndKey)用以归纳不同类型数据。
- Logstore:日志库,用以存放同一类日志数据。Logstore是一个载体,通过由
[0000, FFFF..)区间Shard组合构建而成,Logstore会包含1个或多个Shard。 - Project:Logstore存放容器。
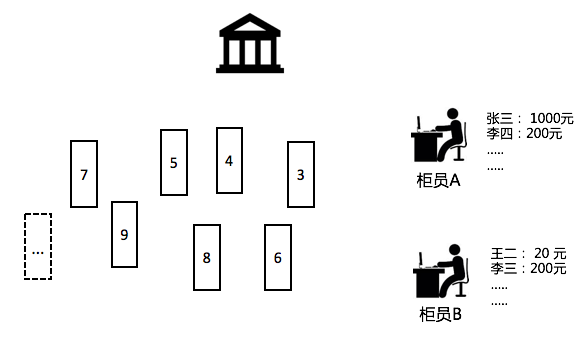
银行的一天
以19世纪银行为例。某个城市有若干用户(Producer),到银行去存取钱(User Operation),银行有若干个柜员(Consumer)。因为19世纪还没有电脑可以实时同步,因此每个柜员都有一个小账本能够记录对应信息,每天晚上把钱和账本拿到公司去对账。

- Log/LogGroup:用户发出的存取款等操作。
- 用户(User):Log/LogGroup生产者。
- 柜员(Clerk):银行处理用户请求的员工。
- 银行大厅(Logstore):用户产生的操作请求先进入银行大厅,再交给柜员处理。
- 分区(Shard):银行大厅用以安排用户请求的组织方式。
问题1:保序(Ordering)
银行有2个柜员(A,B),张三进了银行,在柜台A上存了1000元,A把张三1000元存在自己的账本上。张三到了下午觉得手头紧到B柜台取钱,B柜员一看账本,发现不对,张三并没有在这里存钱。
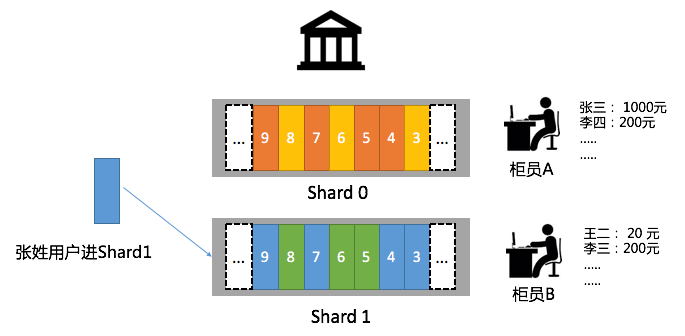
实现保序的方法很简单:排队,创建一个Shard,终端只有一个柜员A来处理。用户请求先进先出,一点问题都没有。但带来的问题是效率低下,假设有1000个用户来进行操作,即使有10个柜员也无济于事。这种场景怎么办?
假设有10个柜员,我们可以创建10个Shard。如何保证对于同一个账户的操作是有序的?可以根据一致性Hash方式将用户进行映射。例如我们开10个队伍(Shard),每个柜员处理一个Shard,把不同银行账号或用户姓名,映射到特定Shard中。在这种情况下张三 Hash(Zhang)= Z 落在一个特定Shard中(区间包含Z),处理端面对的一直是柜员A。
问题2:不丢失(At-Least Once)
张三拿着存款在柜台A处理,柜员A处理到一半去接了个电话,等回来后以为业务已经办理好了,于是开始处理下一个用户的请求,张三的存款请求因此被丢失。
虽然机器不会人为犯错,在线时间和可靠性要比柜员高。但难免也会遇到电脑故障、或因负载高导致的处理中断,因为这样的场景丢失用户的存款,这是万万不行的。这种情况怎么办呢?
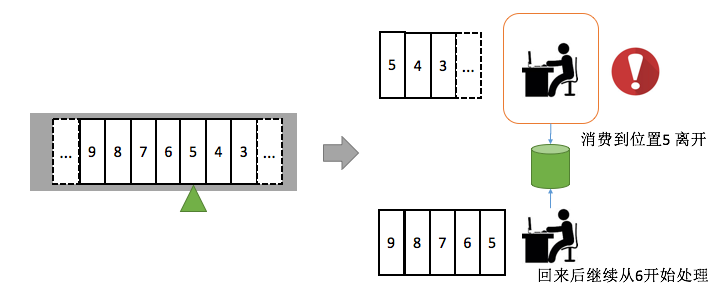
带来问题是什么?可能会重复。例如A已经处理完张三请求(更新账本),准备在日记本上记录处理到哪个位置之时,突然被叫开了,当A回来后,发现张三请求没有记录下来,A会把张三请求再次处理一遍,这就会造成重复。
问题3:不重复(Exactly Once)
重复一定会带来问题吗?不一定。
在幂等情况下,重复虽然会有浪费,但对结果没有影响。什么叫幂等:重复消费不对结果产生影响的操作叫做幂等。例如用户有一个操作 “查询余额”,该操作是一个只读操作,重复做不影响结果。对于非只读操作,例如注销用户这类操作,可以连续做两次。
但现实生活中大部分操作不是幂等的,例如存款、取款等,重复进行计算会对结果带来致命的影响。解决的方式是什么呢?柜员(A)需要把账本完成 + 日记本标记Shard中处理完成作为一个事物合并操作,并记录下来(CheckPoint)。
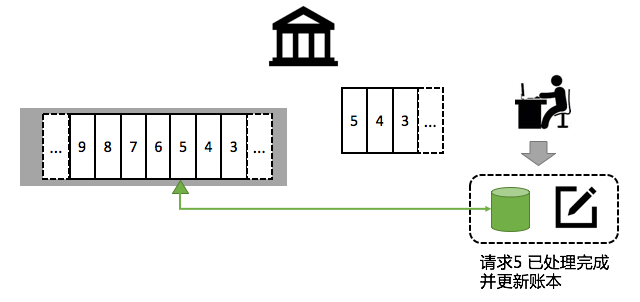
CheckPoint可以将Shard 中的元素位置(或时间)作为Key,放入一个可以持久化的对象中。代表当前元素已经被处理完成。
业务挑战
- 遇到发工资日子,用户数会大涨。
- 柜员(Clerk)毕竟不是机器人,也需要休假,需要吃午饭。
- 银行经理为了整体服务体验,需要加快柜员,以什么作为判断标准?Shard中处理速度?
- 柜员在交接过程中,能否非常容易地传递账本与记录?
现实中的一天
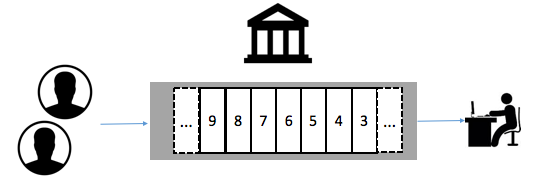
- 8点银行开门。
只有一个Shard0,用户请求全部排在Shard0下,柜员A也正好可以处理。
- 10点进入高峰期间。
银行经理决定把10点后Shard0分裂成2个新Shard(Shard1,Shard2),并且给了如下规定,姓名是[A-W]用户到Shard1中排队,姓名是
[X, Y, Z]到Shard 2 中排队等待处理,为什么这两个Shard区间不均匀?因为用户的姓氏本身就是不均匀的,通过这种映射方式可以保证柜员处理的均衡。10-12点请求消费状态。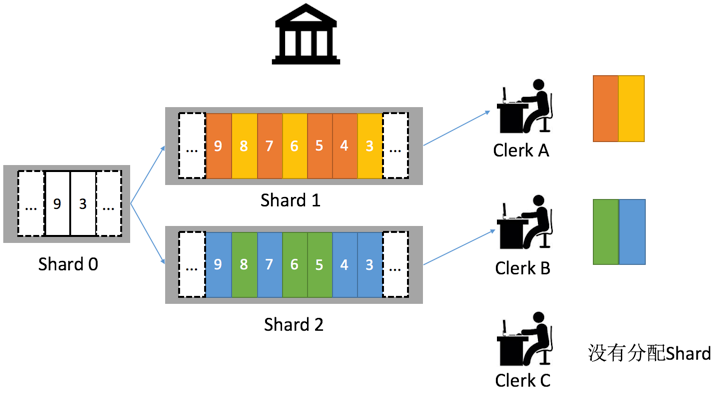
柜员A处理2个Shard非常吃力,于是经理派出柜员B、C出厂。因为只有2个Shard,B开始接管A负责一个Shard,C处于闲置状态。
- 中午12点人越来越多。
银行经理觉得Shard1下柜员A压力太大,因此从Shard1中拆分出(Shard3,Shard4)两个新的Shard,Shard3由柜员A处理、Shard4由柜员C处理。在12点后原来排在Shard 1中的请求,分别到Shard3,Shard4中。
12点后请求消费状态。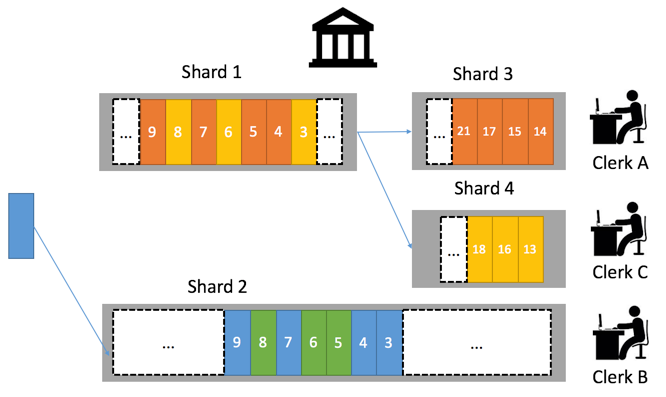
- 流量持续到下午4点后,开始逐渐减少。
因此银行经理让柜员A、B休息,让C同事处理Shard2,Shard3,Shard4中的请求。并逐步将Shard2与Shard3合并成Shard5,最后将Shard5和Shard4合并成一个Shard,当处理完成Shard中所有请求后银行关门。
现实中的日志处理
- 对Shard进行弹性伸缩。
- 消费者上线与下线能够对Shard自动适配,过程中数据不丢失。过程中支持保序。
- 过程中不重复(需要消费者配合)。
- 观察到消费进度,以便合理调配计算资源。
- 支持更多渠道日志接入(对银行而言开通网上银行、手机银行、支票等渠道,可以接入更多的用户请求)。
通过LogHub + LogHub Consumer Library 能够帮助您解决日志实时处理中的这些经典问题,只需把精力放在业务逻辑上,而不用去担心流量扩容、Failover等琐事。
另外,Storm、Spark Streaming已经通过Consumer Library实现了对应的接口,欢迎使用。日志服务的更多技术资讯和讨论,请参见日志服务。


