

一、简介
HDF5(Hierarchical Data Formal)是用于存储大规模数值数据的较为理想的存储格式。
其文件后缀名为h5,存储读取速度非常快,且可在文件内部按照明确的层次存储数据,同一个HDF5可以看做一个高度整合的文件夹,其内部可存放不同类型的数据。
在Python中操纵HDF5文件的方式主要有两种,一是利用pandas中内建的一系列HDF5文件操作相关的方法来将pandas中的数据结构保存在HDF5文件中,二是利用h5py模块来完成从Python原生数据结构向HDF5格式的保存。
本文就将针对pandas中读写HDF5文件的方法进行介绍。
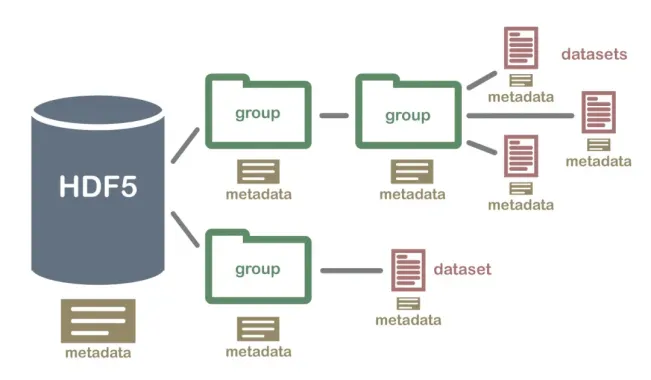
图1
二、利用pandas操纵HDF5文件
1. 写出文件
pandas中的HDFStore()用于生成管理HDF5文件IO操作的对象,其主要参数如下:
下面我们创建一个HDF5 IO对象store:
- import pandas as pd
- store = pd.HDFStore('demo.h5')
- '''查看store类型'''
- print(store)

图2
可以看到store对象属于pandas的io类,通过上面的语句我们已经成功的初始化名为demo.h5的的文件,本地也相应的会出现对应文件。
接下来我们创建pandas中不同的两种对象,并将它们共同保存到store中,首先创建Series对象:
- import numpy as np
- #创建一个series对象
- s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
- s
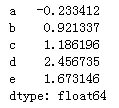
图3
接着我们创建一个DataFrame对象:
- #创建一个dataframe对象
- df = pd.DataFrame(np.random.randn(8, 3),
- columns=['A', 'B', 'C'])
- df
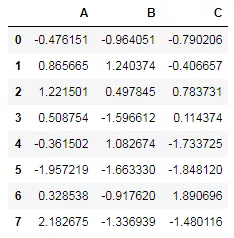
图4
第一种方式利用键值对将不同的数据存入store对象中:
- store['s'], store['df'] = s, df
第二种方式利用store对象的put()方法,其主要参数如下:
使用put()方法将数据存入store对象中:
- store.put(key='s', value=s);store.put(key='df', value=df)
既然是键值对的格式,那么可以查看store的items属性(注意这里store对象只有items和keys属性,没有values属性):
- store.items

图5
调用store对象中的数据直接用对应的键名来索引即可:
- store['df']
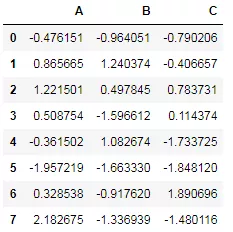
图6
删除store对象中指定数据的方法有两种,一是使用remove()方法,传入要删除数据对应的键:
- store.remove('s')
二是使用Python中的关键词del来删除指定数据:
- del store['s']
这时若想将当前的store对象持久化到本地,只需要利用close()方法关闭store对象即可,而除了通过定义一个确切的store对象的方式之外,还可以从pandas中的数据结构直接导出到本地h5文件中:
- #创建新的数据框
- df_ = pd.DataFrame(np.random.randn(5,5))
- #导出到已存在的h5文件中,这里需要指定key
- df_.to_hdf(path_or_buf='demo.h5',key='df_')
- #创建于本地demo.h5进行IO连接的store对象
- store = pd.HDFStore('demo.h5')
- #查看指定h5对象中的所有键
- print(store.keys())

图7
2. 读入文件
在pandas中读入HDF5文件的方式主要有两种,一是通过上一节中类似的方式创建与本地h5文件连接的IO对象,接着使用键索引或者store对象的get()方法传入要提取数据的key来读入指定数据:
- store = pd.HDFStore('demo.h5')
- '''方式1'''
- df1 = store['df']
- '''方式2'''
- df2 = store.get('df')
- df1 == df2

图8
可以看出这两种方式都能顺利读取键对应的数据。
第二种读入h5格式文件中数据的方法是pandas中的read_hdf(),其主要参数如下:
需要注意的是利用read_hdf()读取h5文件时对应文件不可以同时存在其他未关闭的IO对象,否则会报错,如下例:
- print(store.is_open)
- df = pd.read_hdf('demo.h5',key='df')

图9
把IO对象关闭后再次提取:
- store.close()
- print(store.is_open)
- df = pd.read_hdf('demo.h5',key='df')
- df
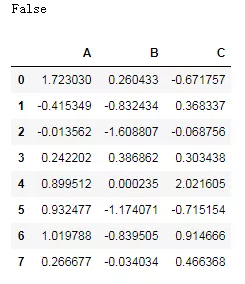
图10
3. 性能测试
接下来我们来测试一下对于存储同样数据的csv格式文件、h5格式的文件,在读取速度上的差异情况:
这里我们首先创建一个非常大的数据框,由一亿行x5列浮点类型的标准正态分布随机数组成,接着分别用pandas中写出HDF5和csv格式文件的方式持久化存储:
- import pandas as pd
- import numpy as np
- import time
- store = pd.HDFStore('store.h5')
- #生成一个1亿行,5列的标准正态分布随机数表
- df = pd.DataFrame(np.random.rand(100000000,5))
- start1 = time.clock()
- store['df'] = df
- store.close()
- print(f'HDF5存储用时{time.clock()-start1}秒')
- start2 = time.clock()
- df.to_csv('df.csv',index=False)
- print(f'csv存储用时{time.clock()-start2}秒')
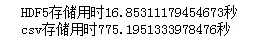
图11
在写出同样大小的数据框上,HDF5比常规的csv快了将近50倍,而且两者存储后的文件大小也存在很大差异:

图12
csv比HDF5多占用将近一倍的空间,这还是在我们没有开启HDF5压缩的情况下,接下来我们关闭所有IO连接,运行下面的代码来比较对上述两个文件中数据还原到数据框上两者用时差异:
- import pandas as pd
- import time
- start1 = time.clock()
- store = pd.HDFStore('store.h5',mode='r')
- df1 = store.get('df')
- print(f'HDF5读取用时{time.clock()-start1}秒')
- start2 = time.clock()
- df2 = pd.read_csv('df.csv')
- print(f'csv读取用时{time.clock()-start2}秒')

图13
HDF5用时仅为csv的1/13,因此在涉及到数据存储特别是规模较大的数据时,HDF5是你不错的选择。

在大流行中,由于数据中心的现场人员缩减,远程监控已变得越来越重要。 COVID-19...
技术进步在许多方面影响着商业领域的发展。新技术、新兴技术以及经过测试的技术...
本文转载自微信公众号「三太子敖丙」,作者三太子敖丙。转载本文请联系三太子敖...
早早早!气候逐渐寒冷,你加衣服了吗?快来看看新出炉的TOP云(zuntop.com)快讯...
前言 这个问题是我之前翻看面经的时候见到的。那位小姐姐把内存泄漏当成了内存溢...
医疗作为基本的民生行业,近几年得到了高速增长,作为技术型行业,其信息化程度...
在过去的20年中,Progressive雇用了70至90名夏季IT实习生,这些实习生从5月至8月...
为什么这么设计(Whys THE Design)是一系列关于计算机领域中程序设计决策的文章,...
双重RAID究竟能否有效解决三副本的缺陷?让我们从二者之间的对比开始。在前面我们...
斑马技术首席护理信息官 Rikki Jennings 斑马技术澳大利亚和新西兰市场医疗保健...



