


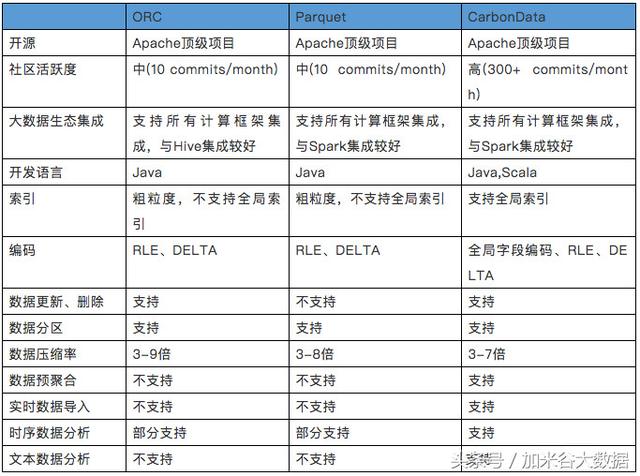
CarbonData在数据查询的性能表现比Parquet好很多,在写一次读多次的场景下非常适合使用;社区比较活跃,响应也很及时。目前官网发布版本1.3.0与***的spark稳定版Spark2.2.1集成,增加了支持标准的Hive分区,支持流数据准实时入库等新特性,相信会有越来越多的项目会使用到。
一、评测环境
1)网络拓扑图

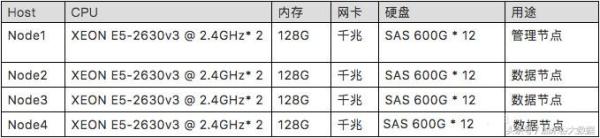
2)配置参数
Ø 服务器配置
二、性能对比
目前主流hadoop的文件存储格式有行存储的CSV格式,列式存储的ORC和Parquet等。本章给出的是Parquet+Spark和CarbonData+Spark在过滤查询场景和聚合计算场景的性能测试结果。
1)测试数据
创建沈阳社保的数据仓库,导入、集成1年的测试数据,如下表:
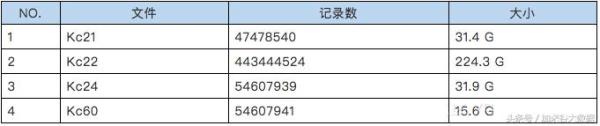
生成CarbonData格式文件,如下表:

2)过滤查询场景测试
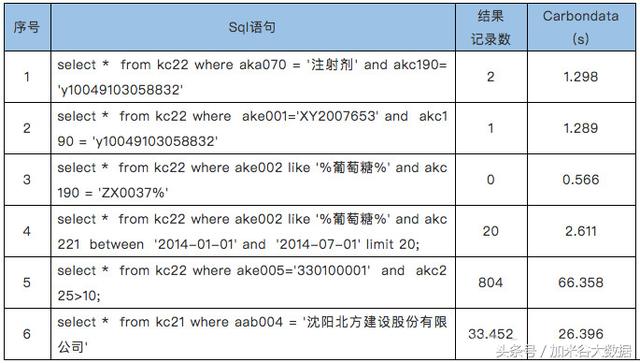

Parquet和CarbonData在过滤查询场景下的性能对比
3)聚合计算场景测试
Parquet和CarbonData在聚合计算场景下的性能对比
4)总结分析
在过滤查询中,CarbonData的查询效率比parquet效率好,主要体现在列数据的索引查询,极大地提高了精确查询的性能。在聚合查询中,CarbonData通过使用全局字典编码来加快计算速度,这使得处理、查询引擎可以直接在编码好的数据上进行处理而不需要转换数据,数据只有在返回结果给用户的时候才转换成用户可读的形式,通过索引有效过滤文件数据块减少磁盘的IO,提高查询性能。
三、小结
CarbonData在数据查询的性能表现比Parquet好很多,在写一次读多次的场景下非常适合使用;社区比较活跃,响应也很及时。目前官网发布版本1.3.0与***的spark稳定版Spark2.2.1集成,增加了支持标准的Hive分区,支持流数据准实时入库等新特性,相信会有越来越多的项目会使用到。

一、不同气象区的选择 1、我国五大气象区域的气象特点 我国面积有960万平方公里...
视频服务器如何选择带宽 https://www.zuntop.com/?news/news/3122.html 一直是视...
医保电子凭证 即日起,医保电子凭证已面向全国开通,覆盖全国13.5亿参保人。用户...
美国服务器顾名思义就是位于美国机房的独立服务器,近年来随着外贸企业的广泛应...
对于负责多个系统上的数据备份的工作人员,强烈建议他们使用强大的策略。此提示...
使用 美国服务器 ,我们可能会遇到不稳定的服务器,这个时候我们需要迁移服务器...
许多走出国门的企业为了保障自家的网络数据安全都会选择购买日本高防服务器来抵...
施耐德电气公司安全电源部门的科学中心高级研究分析师Patrick Donovan对如何为数...
德鲁克说过:动荡时代最大的危险不是动荡本身,而是仍然用过去的逻辑做事。 当下...
自动化越来越被视为数字化转型的一种灵丹妙药。但是,只有当它使组织领导者能够...

