

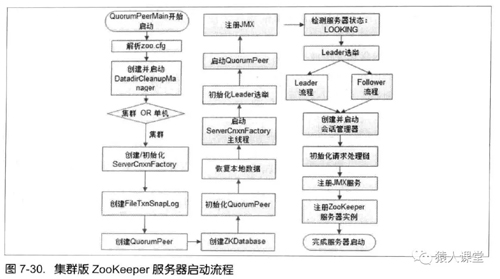
在zk服务器集群启动过程中,经QuorumPeerMain中,不光会创建ZooKeeperServer对象,同时会生成QuorumPeer对象,代表了ZooKeeper集群中的一台机器。在整个机器运行期间,负责维护该机器的运行状态,同时会根据情况发起Leader选举。下图是 《从PAXOS到ZOOKEEPER分布式一致性原理与实践》的服务器启动流程。
QuorumPeer是一个独立的线程,维护着zk机器的状态。
- @Overridepublic synchronized void start() {
- loadDataBase();
- cnxnFactory.start();
- startLeaderElection(); super.start();
- }
本次主要介绍的是选举相关的内容,至于其他操作可以看其他博客。之后的行文都是从startLeaderElection中衍生出来的。

基本概念:
SID:服务器ID,用来标示ZooKeeper集群中的机器,每台机器不能重复,和myid的值一直
ZXID:事务IDVote: 选票,具体的数据结构后面有
Quorum:过半机器数
选举轮次:logicalclock,zk服务器Leader选举的轮次
服务器类型:
在zk中,引入了Leader、Follwer和Observer三种角色。zk集群中的所有机器通过一个Leader选举过程来选定一台被称为Leader的机器,Leader服务器为客户端提供读和写服务。Follower和Observer都能够提供读服务,***的区别在于,Observer机器不参与Leader选举过程,也不参与写操作的过半写成功策略。因此,Observer存在的意义是:在不影响写性能的情况下提升集群的读性能。
服务器状态:
+ LOOKING:Leader选举阶段+ FOLLOWING:Follower服务器和Leader保持同步状态+ LEADING:Leader服务器作为主进程领导状态。+ OBSERVING:观察者状态,表明当前服务器是Observer,不参与投票
选举的目的就是选择出合适的Leader机器,由Leader机器决定事务性的Proposal处理过程,实现类两阶段提交协议(具体是ZAB协议)
QuorumPeer维护集群机器状态
QuorumPeer的职责就是不断地检测当前的zk机器的状态,执行对应的逻辑,简单来说,就是根据服务所处的不同状态执行不同的逻辑。删除了一部分逻辑后,代码如下:
- @Overridepublic void run() {
- setName("QuorumPeer" + "[myid=" + getId() + "]" +
- cnxnFactory.getLocalAddress());
- try {
- while (running) {
- switch (getPeerState()) {
- case LOOKING:
- LOG.info("LOOKING");
- try {
- setBCVote(null); setCurrentVote(makeLEStrategy().lookForLeader());
- }
- catch (Exception e) {
- LOG.warn("Unexpected exception", e); setPeerState(ServerState.LOOKING);
- }
- break;
- case OBSERVING:
- try {
- LOG.info("OBSERVING"); setObserver(makeObserver(logFactory)); observer.observeLeader();
- } catch (Exception e) { LOG.warn("Unexpected exception",e );
- } finally {
- observer.shutdown();
- setObserver(null);
- setPeerState(ServerState.LOOKING);
- }
- break;
- case FOLLOWING:
- try {
- LOG.info("FOLLOWING"); setFollower(makeFollower(logFactory)); follower.followLeader();
- } catch (Exception e) {
- LOG.warn("Unexpected exception",e);
- } finally {
- follower.shutdown();
- setFollower(null);
- setPeerState(ServerState.LOOKING);
- }
- break;
- case LEADING:
- LOG.info("LEADING");
- try {
- setLeader(makeLeader(logFactory));
- leader.lead();
- setLeader(null);
- } catch (Exception e) { LOG.warn("Unexpected exception",e);
- } finally {
- if (leader != null) {
- leader.shutdown("Forcing shutdown"); setLeader(null);
- }
- setPeerState(ServerState.LOOKING);
- }
- break;
- }
- }
- } finally {
- LOG.warn("QuorumPeer main thread exited");
- }
- }
当机器处于LOOKING状态时,QuorumPeer会进行选举,但是具体的逻辑并不是由QuorumPeer来负责的,整体的投票过程独立出来了,从逻辑执行的角度看,整个过程设计到两个主要的环节:
而QuorumPeer中默认使用的选举算法是FastLeaderElection,之后的分析也是基于FastLeaderElection而言的。
选举过程中的整体架构
在集群启动的过程中,QuorumPeer会根据配置实现不同的选举策略this.electionAlg = createElectionAlgorithm(electionType);
- protected Election createElectionAlgorithm(int electionAlgorithm){
- Election le=null; switch (electionAlgorithm) { case 3:
- QuorumCnxManager qcm = new QuorumCnxManager(this);
- QuorumCnxManager.Listener listener = qcm.listener; if(listener != null){
- listener.start();
- le = new FastLeaderElection(this, qcm);
- } else {
- LOG.error("Null listener when initializing cnx manager");
- } break; default: assert false;
- } return le;
- }
如果ClientCnxn是zk客户端中处理IO请求的管理器,QuorumCnxManager是zk集群间负责选举过程中网络IO的管理器,在每台服务器启动的时候,都会启动一个QuorumCnxManager,用来维持各台服务器之间的网络通信。
对于每一台zk机器,都需要建立一个TCP的端口监听,在QuorumCnxManager中交给Listener来处理,使用的是Socket的阻塞式IO(默认监听的端口是3888,是在config文件里面设置的)。在两两相互连接的过程中,为了避免两台机器之间重复地创建TCP连接,zk制定了连接的规则:只允许SID打的服务器主动和其他服务器建立连接。实现的方式也比较简单,在receiveConnection中,服务器会对比与自己建立连接的服务器的SID,判断是否接受请求,如果自己的SID更大,那么会断开连接,然后自己主动去和远程服务器建立连接。这段逻辑是由Listener来做的,且Listener独立线程,receivedConnection,建立连接后的示意图:

QuorumCnxManager是连接的管家,具体的TCP连接交给了Listener,但是对于选票的管理,内部还维护了一系列的队列:
queueSendMap:消息发送队列,用于保存待发送的消息。new ConcurrentHashMap
senderWorderMap:发送器集合。每个SendWorder消息发送器,都对应一台远程zk服务器,负责消息的发放。
lastMessageSent:最近发送过的消息,按照SID分组
基本的通信流程如下:

以上内容主要是建立各台zk服务器之间的连接通信过程,具体的选举策略zk抽象成了,主要分析的是FastLeaderElection方式(选举算法的核心部分):
- public interface Election { public Vote lookForLeader() throws InterruptedException; public void shutdown();
- }
FastLeaderElection选举算法
上面说过QuorumPeer检测到当前服务器的状态是LOOKING的时候,就会进行新一轮的选举,通过setCurrentVote(makeLEStrategy().lookForLeader());也就是FastLeaderElection的lookForLeader来进行初始选择,实现的方式也很简单,主要的逻辑在FastLeaderElection.lookForLeader中实现:
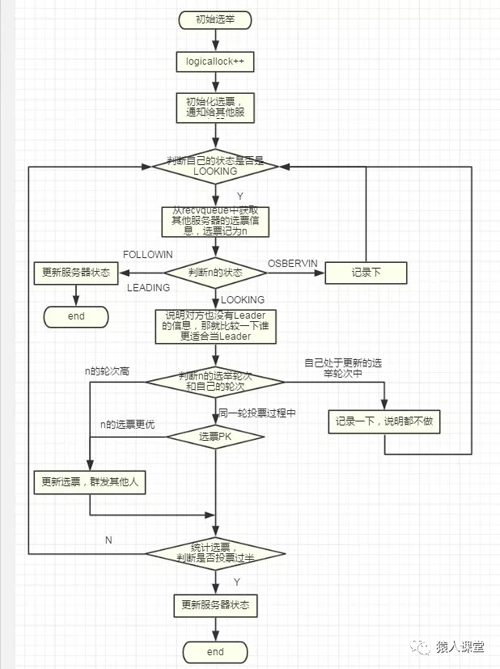
基本流程先说明一下:
LOOKING: 都处于无Leader态,比较一下选票的优劣,看是否更新自己的选票,如果更新了就同时通知给其他服务器
FOLLOWING、LEADING:说明集群中已经有Leader存在,更新一下自己的状态,结束本轮投票
OBSERVING:这票没什么卵用,直接舍弃(OBSERVER是不参与投票的)
根据上面的流程,可以大概说明一下FasterLeaderElection确定选票更优的策略:
总结:
以上就是zk的默认选票流程,按照ZAB协议的两种状态分析:
Leader服务器挂了,那么经历的和初始化流程类似的过程,选择Leader
Follower服务器挂了,那么自己在执行选举的过程中,会收到其他服务器给的Leader选票信息,也可以确定Leader所属

前言 日常开发中,秒杀下单、抢红包等等业务场景,都需要用到分布式锁。而Redis...
工信部印发了《工业互联网专项工作组2020年工作计划》。计划提出了提升基础设施...
1.世上最痛苦的事,不是永恒的孤寂,而是明明看见温暖与生机,我却无能为力。世...
作为一名资深(fu xiu)的程序猿来说,一直不想向IDEA低头可能是我对MyEclipse最大...
云计算技术髙速转型至今,被视为将要更改网站开发、全渠道工作代管的局势。将云...
图片来自 Pexels 这么多年过去了,这句话或深或浅地影响了我的技术选择,以至于...
2018年10月16日,曙光对外发布了全球首款闭式循环一体液冷八路服务器I980-G30。...
在托管方面,许多企业只熟悉共享主机和云服务器。虽然这些解决方案适用于小到中...
SAN(存储区域网络)和NAS(网络附加存储)都是存储系统的基本结构,虽然它们看起来...
2018年年底,微软云宣布其云连接服务产品ExpressRoute在中国东部 2 及中国北部 2...

