

一台服务器,不管是物理机还是虚拟机,必不可少的就是内存,内存的性能又是如何来衡量呢。

1. 内存与缓存
现在比较新的CPU一般都有三级缓存,L1 Cache(32KB-256KB),L2 Cache(128KB-2MB),L3 Cache(1M-32M)。缓存逐渐变大,CPU在取数据的时候,优先从缓存去取数据,取不到才去内存取数据。
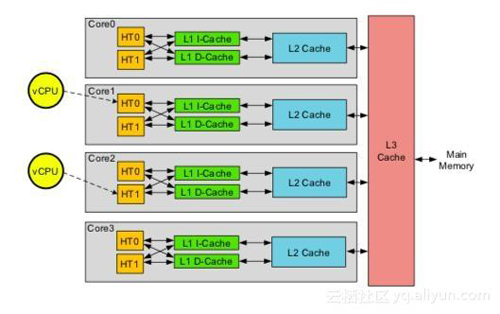
2. 内存与时延
显然,越靠近CPU,取数据的速度越块,通过LMBench进行了读数延迟的测试。

从上图可以看出:
Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz 这款CPU的L1D Cache,L1I Cache为32KB,而L2 Cache为1M,L3为32M;
在对应的Cache中,时延是稳定的;
不同缓存的时延呈现指数级增长;
所以我们在写业务代码的时候,如果想要更快地提高效率,那么使得计算更加贴近CPU则可以获取更好的性能。但是从上图也可以看出,内存的时延都是纳秒为单位,而实际业务中都是毫秒为单位,优化的重点应该是那些以毫秒为单位的运算,而内存时延优化这块则是长尾部分。
3. 内存带宽
内存时延与缓存其实可谓是紧密相关,不理解透彻了,则可能测的是缓存时延。同样测试内存带宽,如果不是正确的测试,则测的是缓存带宽了。
为了了解内存带宽,有必要去了解下内存与CPU的架构,早期的CPU与内存的架构还需要经过北桥总线,现在CPU与内存直接已经不需要北桥,直接通过CPU的内存控制器(IMC)进行内存读取操作:
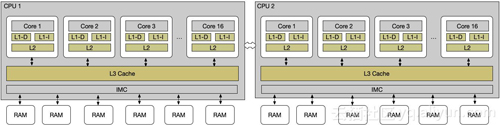
那对应的内存带宽是怎样的呢?测试内存带宽有很多很多工具,linux下一般通过stream进行测试。简单介绍下stream的算法:
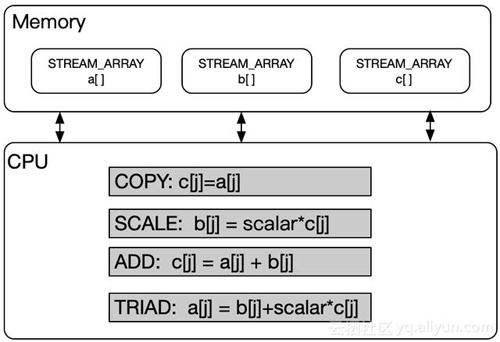
stream算法的原理从上图可以看出非常简单:某个内存块之间的数据读取出来,经过简单的运算放入另一个内存块。那所谓的内存带宽:内存带宽=搬运的内存大小/耗时。通过整机合理的测试,可以测出来内存控制器的带宽。下图是某云产品的内存带宽数据:
- Function Best Rate MB/s Avg time Min time Max time
- Copy: 128728.5 0.134157 0.133458 0.136076
- Scale: 128656.4 0.134349 0.133533 0.137638
- Add: 144763.0 0.178851 0.178014 0.181158
- Triad: 144779.8 0.178717 0.177993 0.180214
内存带宽的重要性自然不言而喻,这意味着操作内存的***数据吞吐量。但是正确合理的测试非常重要,有几个注意事项需要关注:
内存数组大小的设置,必须要远大于L3 Cache的大小,否则就是测试缓存的吞吐性能;
CPU数目很有关系,一般来说,一两个核的计算能力,是远远到不了内存带宽的,整机的CPU全部运行起来,才可以有效地测试内存带宽。当然跑单核的stream测试也有意义,可以测试内存的延时。
4. 其他
内存与NUMA的关系:开启NUMA,可以有效地提供内存的吞吐性能,降低内存时延。
stream算法的编译方法选择:通过icc编译,可以有效地提供内存带宽性能分。原因是Intel优化了CPU的指令,通过指令向量化和指令Prefetch操作,加速了数据的读写操作以及指令操作。当然其他C代码都可以通过icc编译的方法,提供指令的效率。

Tomcat的默认配置,性能并不是最优的,我们可以通过优化tomcat以此来提高网站的...
【51CTO.com原创稿件】在数字经济的推动下,云计算、大数据、物联网、AI、5G等诸...
随着经济压力的加大,人们对于就业的观念也在改变,响应大众创业、万众创新号召...
为什么从数据战略开始是成功的数字资产管理(DAM)的关键。 数字资产是一个时髦的...
2019年5月16日,第三届世界智能大会在天津梅江会展中心拉开帷幕。本届大会以智能...
【51CTO.com原创稿件】CIO不喜欢弯弯绕绕,在CIO IT经理精英汇微信群中讨论数据...
怎么才能选好一款虚拟主机,今天TOP云(zuntop.com)科技小编就来总结下具体方法...
通过分析出错了的项目,可以收集到大量的信息和具体的见解。以下是IT领导者可以...
回首2020年,疫情这把双刃剑,一方面对应整个社会造成了冲击,但是另一方面,其...
【51CTO.com原创稿件】当前,人工智能的飞速发展推动了企业创新和产业进步,越来...

