

0x00 前言
随便聊一下用户画像的存储。
现在的用户画像,动不动就是几千几万个标签,标签一多就出现了一些需要克服的难题,比如下面两个:
0x01 数据模型设计
从个人角度来讲,在大数据领域接触比较多的的存储引擎有这几个:Hive(Hdfs)、Hbase、ES。这也会是我们在选择存储系统中几个主要的备选方案。
优缺点就不再分析了。我们切入正题:数据模型该怎么设计?

一、横表
以Hive为例,我们最常用的就是横表,也就是一个 key,跟上它的所有标签。比如下面是一个简单的横表。
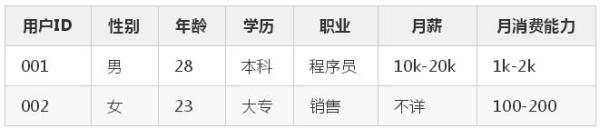
那么用横表有什么问题吗?有的,其实也就是前言里面提到的:
嗯,上述的问题,主要是当标签数量开始快速增多的时候会遇到的问题。标签量少的时候其实是不用担心这些的。
那么这些问题该怎么解决呢?这就是下面要聊得竖表。
二、竖表
竖表长下面这个样子:
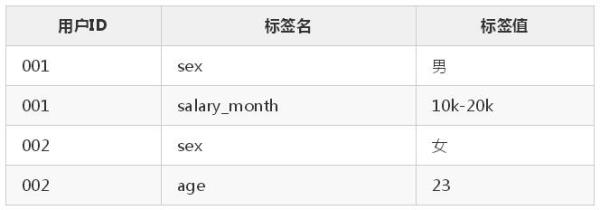
这里就不再列举全部内容了,大概介绍一下,竖表其实就是将标签都拆开,一个用户有多少标签,那么在这里面就会有几条数据。
竖表能比较好地解决上面宽表的问题。但是它也会带来了新的问题,比如说多标签组合的查询需求:“我们想看年龄在23-30之间,月薪在10-20k之间,喜欢听古典音乐的女性”,这种多标签查询条件组合情况在竖表中就不太容易支持。
三、横表+竖表
如前面所分析,竖表和横表各有所长和所短,那么能不能两者结合呢?
这其实也要考虑横表和竖表的特性,整体来讲就是竖表对计算层支持的好,横表对查询层支持的好。那么设计的化就可以这样:
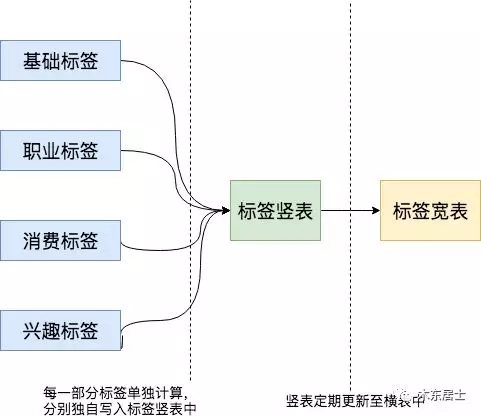
0x02 如何存储?
关于存储,我们以前文说的第三种方案为例。
标签的计算我们可以使用Hive、Spark这些计算引擎,这个没什么问题,然后就是这些标签的单独存储可以以Hive为主来存储。
那么在导入标签竖表的时候可以考虑两种存储引擎:Hive(Hdfs)和Hbase,其实笔者更倾向于Hbase,因为如果存在Hbase里的话会更方便查询。顺便再打上一个时间标签,用起来就更方便了。
***,标签宽表的话可以考虑ES。另外需要注意的就是,从竖表往宽表到数据的时候需要做一层数据的加工,而且考虑到数据稀疏的情况的话,需要在宽表存储这里做一些优化。

固态硬盘非常奇怪,因为它们在编写数据的方式上很奇怪,甚至在删除信息的方式上...
伟大的领导者们知道,如何让合作伙伴也取得成果和让自己取得成果一样重要。在这...
服务器相对其他类型的主机稳定性更高,但其复杂的构造也导致不稳定的影响较多,...
坚定履行在中国的长期发展承诺 中国北京 2019年10月25日 戴尔科技集团董事长兼首...
Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器,...
本文转载自微信公众号「全栈码农画像」,作者小码甲。转载本文请联系全栈码农画...
本文转载自微信公众号「SH的全栈笔记」,作者SH 。转载本文请联系SH的全栈笔记公...
价格,永远都是用户选择服务器时最为关心的问题。那么有关服务器租用价格的影响...
国外的云服务器抗攻击吗 ?有些提供国外服务器租用的IDC厂商宣称自己的云服务器...
云储存是在云计算(cloud computing)概念上延伸和发展出来的一个新的概念,是一种...

