

现在的负载均衡技术,可以说是满大街都是,但是我们基本都停留在了使用的阶段上,并没有真正深入去了解其核心。如果真的出现了问题,可能就很难知道是什么原因导致了,只能去google,百度了。 因此,了解一些核心的东西,还是不错的。
负载均衡大概流程就是,随时收集各服务器信息或者各服务器主动上报信息,由配置主心进行保存,计算出权重,然后根据相应算法进行服务机器选择。(当然了,这不是本文的重点,我也说得不一定对)
我要展示的是,一个根据权重进行机器选择的一个巧妙算法,如下:
- int chooseOneRoute ( LB_SvrInfo * & pSvr )
- {
- double dblTotalWeight = 0.0;
- int i = 0;
- time_t curTime = time(NULL);
- //权重的计算方法是Late方法
- if ( curTime - calWeightTime >= CAL_WEIGHT_TIME_INTERVAL )
- {
- calculateWeight();
- }
- //先把各服务器权重加起来
- for ( i = 0; i < MAX_SERVER_NUM; i++ )
- {
- if ( !oServerInfo[i].isOkForRoute() ) continue;
- dblTotalWeight += oServerInfo[i].getWeight();
- }
- dblTotalWeight *= rand() / ( RAND_MAX + 1.0 );
- //做减法
- for ( i = 0; i < MAX_SERVER_NUM; i++ )
- {
- if ( !oServerInfo[i].isOkForRoute() ) continue;
- dblTotalWeight -= oServerInfo[i].getWeight();
- //找到对应服务器
- if ( dblTotalWeight < 0 ) break;
- }
- pSvr = &( oServerInfo[i] );
- return 0;
- }
分步解释就是:
先计算得到各机器的权重值,保存起来;

按顺序将各机器权重相加,相加之后就相当于各机器在总权重上占了各相应的一段比例;
取随机数,得到一个0~1的随机值,并乘以总权重,作为选中机器的标志;
再按顺序减去各机器的权重,当减到选择机器的权重范围时,就得到了机器号,从而选定该机器。
算法示意图如下:
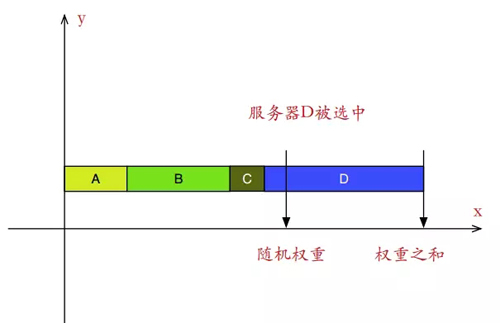
服务器权重越高,在线段上占的长度越长,被随机数选中的概率也越大。
刚开始的时候,我以为是哪个数学家搞出来的公式得到的呢,结果原理却出奇的简单,所以好的东西不一定是复杂的,或者说看起来牛逼的东西,不一定就很复杂,但是肯定是大多数人意想不到的。

湿纸巾,干垃圾还是湿垃圾?最近如何正确地倒垃圾让不少城市居民犯了愁。而从7月1...
近期,IDC公布了其对2021年及未来全球IT行业的预测:在新冠疫情席卷全球的大环境...
最近,我在YouTube上看了一个非常出色的开发人员的视频。 它的标题是无服务器毫...
【51CTO.com快译】美国的一项调查显示:将近三分之二的企业正在计划或已经将企业...
容器云在使用分布式存储时,HDFS、CEPH、GFS、GPFS、Swift等分布式存储哪种更好?...
很多朋友不理解 云主机是什么 ,具体有什么作用以及有什么优势等问题,那么在这...
【51CTO.com原创稿件】2月25日消息,致力于驱动在华企业释放数据潜能并加速数字...
Redis具有很多值得推荐的功能,包括速度,可伸缩性和可用性。但是,有一个问题是...
以5G、数据中心等为代表的新型基础设施建设近期受到广泛关注。值得注意的是,数...
01 人工智能从沉寂期翻身靠的是博取众长 1956年的达特茅斯会议上,人工智能概念...

