

在本文中,我们将讨论机器学习中回归和分类的各种指标。我们总是想到建模一个好的机器学习算法所涉及的步骤。第一步是评估模型优劣的指标。当我们拟合模型并做出预测时,我们总是尝试了解误差和准确性。本文将尝试提供并解释回归和分类中的各种错误度量方法。
有一些标准可以评估模型的预测质量,如下所示:
基本定义
估计器:它是一个函数或方程式,用于预测实际数据点上的更准确的建模点。
要知道的技巧
评估方法中有两点需要注意,如下所示:
回归指标
评估回归性能的指标如下:
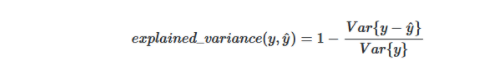
python中的示例:
- #从sklearn导入差异分数
- from sklearn.metrics import explained_variance_score
- true_values = [5, 2.5, 3, 6]
- predicted_values = [4.5, 2.9, 3, 7]
- explained_variance_score(true_values, predicted_values)
- #output:
- 0.8525190839694656
2.最大误差:此度量标准将计算真实值和预测值之间的最差值。
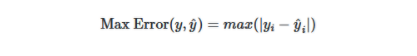
python中的示例
- from sklearn.metrics import max_error
- true_values = [5, 2.5, 3, 6]
- predicted_values = [4.5, 2.9, 3, 8]
- max_error(true_values, predicted_values)
- #output:
- 2
3.平均绝对误差:此度量标准计算真实值和预测值之差的平均误差。该度量对应于l1-范数损失。
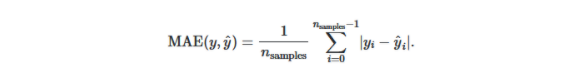
python中的示例
- from sklearn.metrics import mean_absolute_error
- true_values = [5, 2.5, 3, 6]
- predicted_values = [4.5, 2.9, 3, 7]
- mean_absolute_error(true_values, predicted_values)
- #output:
- 0.475
3.均方误差:此度量标准计算二次误差或损失。

python中的示例
- from sklearn.metrics import mean_squared_error
- true_values = [5, 2.5, 3, 6]
- predicted_values = [4.5, 2.9, 3, 7]
- mean_squared_error(true_values, predicted_values)
- #output:
- 0.3525
4. R平方得分:此度量标准从均值或估计量(如拟合的回归线)计算数据的分布。通常称为“确定系数”。
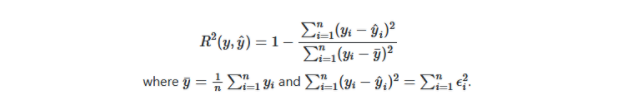
python中的示例
- from sklearn.metrics import r2_score
- true_values = [5, 2.5, 3, 6]
- predicted_values = [4.5, 2.9, 3, 7]
- r2_score(true_values, predicted_values)
- #output:
- 0.8277862595419847
分类指标
评估分类效果的指标如下:
公式如下:
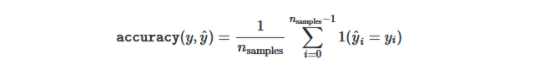
python中的示例
- from sklearn.metrics import accuracy_score
- true_values = [5, 2, 3, 6]
- predicted_values = [4, 3, 3, 6]
- accuracy_score(true_values, predicted_values)
2.分类报告:此度量标准计算的报告包含分类问题的精度,召回率和F1得分。
Python范例
- from sklearn.metrics import classification_report
- true_values = [3, 4, 3, 6]
- predicted_values = [4, 3, 3, 6]
- target_names = ['Apple', 'Orange', 'Kiwi']
- print(classification_report(true_values, predicted_values, target_names=target_names))
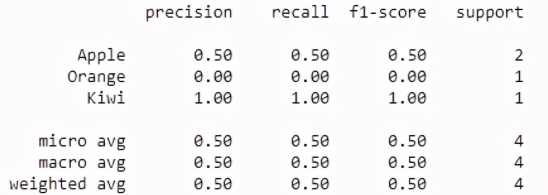
3.铰链损耗:此损耗计算数据点和模型预测点之间的平均距离。SVM算法中也使用它来获得最大边际。

python中的示例
- from sklearn import svm
- from sklearn.metrics import hinge_loss
- from sklearn.svm import LinearSVC
- #data set in x and y values
- x_values = [[3], [2]]
- y_values = [-1, 1]
- #using linear SVC model
- svm_linear = svm.LinearSVC(random_state=0)
- #fitting the model
- svm_linear.fit(x_values, y_values)
- LinearSVC(random_state=0)
- #making decision prediction
- pred_decision = svm_linear.decision_function([[-2], [3], [0.5]])
- hinge_loss([-1, 1, 1], pred_decision)
- #output:
- 1.333372678152829
结论:
这些都是从回归和分类中评估模型性能的一些指标。分类中有基于回归,二元类和多类指标的各种指标。

近年来,因高空抛物、坠物造成的伤害事件屡上报端。水瓶、西瓜皮、易拉罐,甚至...
1.总有一天,我们会过上我一翻身就可以偷亲你的日子。 2.即使一贫如洗,我会是...
5G网络建设加快,超前布局6G 截止目前,我国累计建成的5G基站数量超过71.8万座,...
逛个动物园要指纹打卡,连回家进小区也要刷脸验明正身会议期间,记者在浙江代表...
1.终有那么一个人,可以随时改变着你的心情。 2.有的东西你再喜欢也不会属於你...
5G切片是新商业模式的关键推动者,也是增强5G潜力的关键概念。通信服务提供商可...
整个欧洲向智能建筑迈进的步伐正在加快。随着各行各业的组织在客户和员工体验方...
人脸解锁扫脸支付随着人脸识别技术的不断发展,如今借助一个小小的摄像头就能让...
3月15日消息 一年一度的央视财经 3.15 晚会正在进行中,从前言来看主要曝光问题...
iOS 11~iOS 14.3的越狱工具发布了un0ver6.0.0版本 支持iOS11-iOS 14.3系统设备进...

