

今天写一篇知识图谱方面的文章,算作是个人对知识图谱的一个初步学习和认识。对于知识图谱最近几年一直有人跟我谈到这个词,或者是自己在从事知识图谱技术工作,或者在大数据平台构建完成后需要构建知识图谱等。
实际在在10多年前,在企业知识管理和知识库构建中,类似Autonomy知识管理软件,当时就谈到了文本内容的语义识别和语义网构建,包括类似香农理论和贝叶斯算法的使用等,也有基于知识图谱的知识和学习路线规划等。后来Autonomy被HP收购了,反而是销声匿迹。
但是最近几年,随着大数据和AI人工智能的发展,知识图谱成为一个新的热点,并在类似风控和反欺诈,智能推荐引擎,智能知识问答等诸多的领域发挥作用。实际上也可以看到大数据和AI算法的发展都进一步推动知识图谱的应用和落地。
知识图谱要构建不能离开大数据,海量自然数据的知识采集和抽象才能够构建一个完整的知识语义网络,但是只有网络还不行,基于语义网络你的知识推理逻辑和算法还得不断提供技术支撑。
因此数据+算法两个方面的发展才是推动知识图谱细分领域发展的关键。
知识图谱概述
对于知识图谱,从基本概念到构建流程,方法工具,网上都有详细的文章可以参考,在这里仅仅对知识图谱的基础概念做一个阐述。
知识图谱(Knowledge Graph)的概念由谷歌2012年正式提出,旨在实现更智能的搜索引擎,并且于2013年以后开始在学术界和业界普及,并在智能问答、情报分析、反欺诈等应用中发挥重要作用。
知识图谱本质上是一种叫做语义网络(semantic network)的知识库,即具有有向图结构的一个知识库,其中图的结点代表实体(entity)或者概念(concept),而图的边代表实体/概念之间的各种语义关系,比如说两个实体之间的相似关系。
当在理解知识图谱的时候,实体和概念必须要区分清楚,对于概念当前本身又拆分为了概念和属性两个独立的词。
如果从IT和软件开发来对比话,实体就类似于领域建模里面的实体对象,而概念类似于值对象,实体对象可以独立存在,具有独立生命周期,而概念或值对象则依托于实体,没有实体单独谈概念对象或值没有意义。
我们来举例说明下:
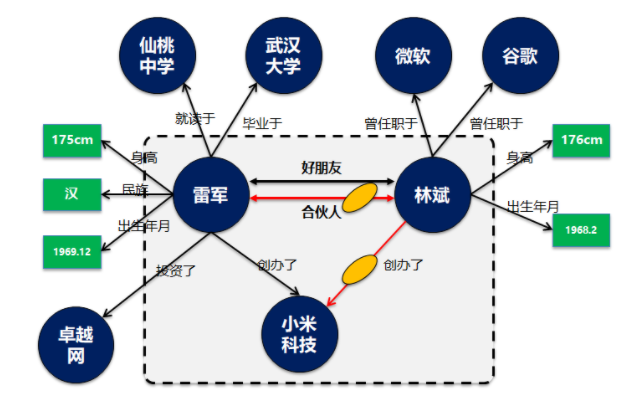
雷军认识林斌,是在2008年。当时林斌想推动Google和UCWEB之间的合作。雷军惊讶的发现,林斌有发自内心对产品的热爱,林斌在Google所做的工作和产品都非常投入,“下功夫”。那个时候,雷军开始经常去找林斌聊天,两个大男人经常在一起挑灯夜战,聊到凌晨一、两点钟。聊着聊着,两人从合作伙伴聊成了好朋友。
从上面这段,我们至少可以得知。
雷军和林斌是好朋友。
这个是典型的实体和实体间关系描述,可以用类似RDF三元组模型进行抽象和建模,存储到类似图数据库中。里面的核心元数据就是实体对象和实体关系。
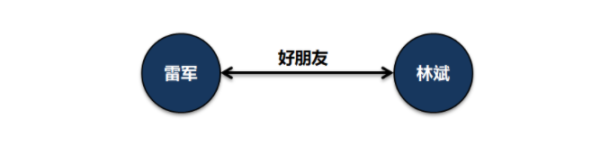
可以看到雷军和林斌两个是独立实体,具备独立的生命周期,虽然两者之间有关系,但是都可以独立存在,而不受对方影响。
而对于概念和概念属性呢?
则类似于进一步对雷军的个人属性描述,比如身高,性别,年龄,民族等。概念和属性最大的一个特点就是概念只是一个属性列表或者值集合。这个值可以是连续的,如身高数值。也可以是不连续的,如56个民族。但是不管是哪种情况最终概念里面的都是一个最终的属性值。如同实体不存在了,这个概念和属性值本身没有业务意义。
当把这个理解清楚后,我们再来看。
雷军毕业于湖北仙桃中学,那么仙桃中学究竟是概念还是实体?实际上仙桃中学应该作为实体独立研究,因为对于仙桃中学的描述,不是通过一系列连续或不连续的值来定义的。同时仙桃中学可以独立存在,雷军是否存在过并不影响到仙桃中学这个学校。
那么仙桃中学就应该作为独立的实体。
基于这个思路,整个关系图可以变化为如下图。
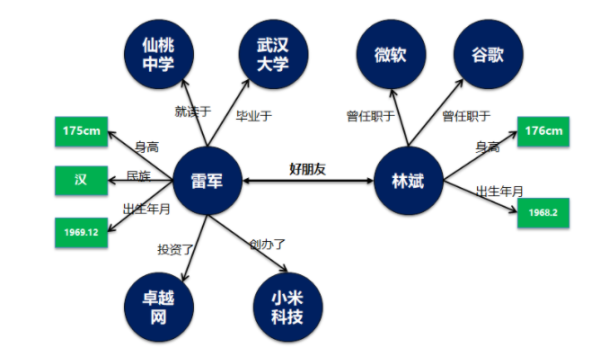
在这里我特意讲概念和属性值用了绿色方框进行描述。
简单来说概念是一个特殊类型的实体,这类实体不会进一步展开,也不会直接和其它实体之间建立关系映射。
知识图谱的构建过程
对于知识图谱的构建过程,网上有很多详细的文章可以参考,在这类不再详细描述。仅仅谈下重点内容。
在前面的简单举例已经可以看到,一个知识图谱的构建核心还是实体对象的识别,实体关系的建立。也就是需要从一个非结构化的文本材料,乃至语音材料里面识别和抽象出对应的实体,同时建立实体之间的关系。
人和物皆是关键的实体
在识别实体的时候可以看到,人和物本身都是重点要识别的实体对象。人本身既从属于一个团队,地点或组织,同时也设计或创造事物。
因此再扩展的话,可以理解为物品,场所,人物,企业组织团队,区域地点是重要可以识别的关键实体。这些实体本身又是一种可以向上聚合,向下展开的层次化结构。
比如一个商场本身属于一个区域,同时商场展开本身又包括多个门店。
抽象概念还是实例概念
当分析实体的时候还得注意实体一般是实例化和特指的,而不是一个抽象的概念。比如当你谈到悲惨世界的时候,悲惨世界既可以指雨果的书籍,也可以是电影的某个版本,还可以是10周年的音乐剧。
那我们对实体的研究最好特指到具体的实例层级,比如悲惨世界2012年电影版本。
当理解清楚实体后,再来看关系的识别。
人或物隶属于一个组织或区域
人创造发明或消费使用某个物品
人和人之间的关系,如家人,同学,同事,合伙人等
实体本身体现的层次关系展开和聚合
也就是大部分实体的关系都体现在上面列举的各个方面展开。
知识图谱的构建
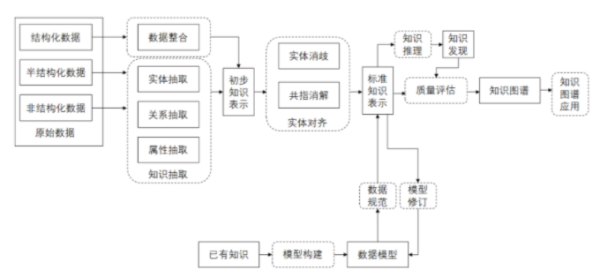
知识图谱的构建过程实际上相当复杂,但是核心主要包括了知识的抽取,知识存储,实体对齐,知识建模和知识推理等几个关键步骤。
对于知识的抽象,不论是结构化数据还是文本等非结构化数据,最终都需要转化为三元组数据结构,方便构建知识图谱模型。在知识抽取完成后,就涉及到知识的存储,当前主流仍然是采用类似Neo4j等图数据库来完成。在关系型数据库中所有的数据库模式都需要提前定义,后续改动代价高昂。而图模型中,只需要重新增加模式定义, 再局部调整数据,便可完成在原有的数据源上增加标签或添加属性。
最近我在查看和学习知识图谱的一些技术资料,发现一个大问题,即将知识体系和知识图谱两个概念混淆,将知识体系误认为知识图谱,同时采用思维导图来构建知识图谱,这是一个相当错误的做法。特别是思维导图本身就是单节点为中心展开的,完全无法表达多实体之间的关系信息。
类似网上搜索到的这个图,就是一个完全错误的做法。
知识推理过程
知识图谱在构建完成后,更加重要的是进行知识推理,而知识推理本身是基于构建的推理模型进行的,也就是是知识图谱体现的人工智能本身是基于算法和推理模型进行的,而非前面文章谈到的基于统计学思维的人工智能。
那知识推理究竟是推理什么?
最常见的就是基于实体网络已经的实体关系来推理实体间的其它关系。比如一个实体三角,当两个关系已知的时候往往可以推理去未知的关系边。
在实体关系里面,如果已知:
那么则可以推理出雷军和林斌两个实体的关系,从好朋友增加了合伙人关系。
其次常见的就是异常风险检测。
即通过知识抽取采集形成完整的知识图谱后,你会发现在整个语义网络里面实体之间的关系存在异常。在金融等反欺诈领域,经常就会遇到类似的知识图谱推理逻辑去发现相关的问题,比如常说的多点共享信息,如下图:
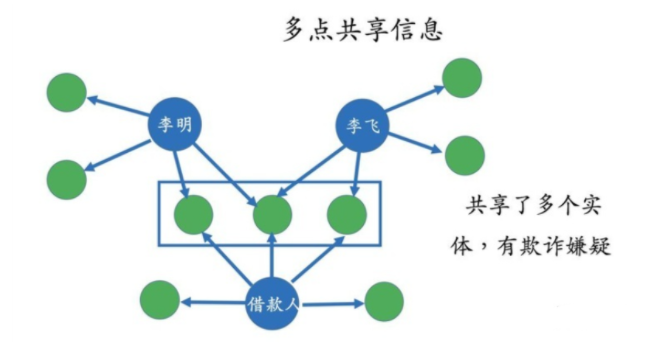
即李明,李飞和借款人三个实体共享多个实体信息,比如居住地址,银行账号,毕业学校等完全相同,那么就存在金融欺诈的可能性。
还有串行逻辑推理,最常见的例子类似股权穿透。
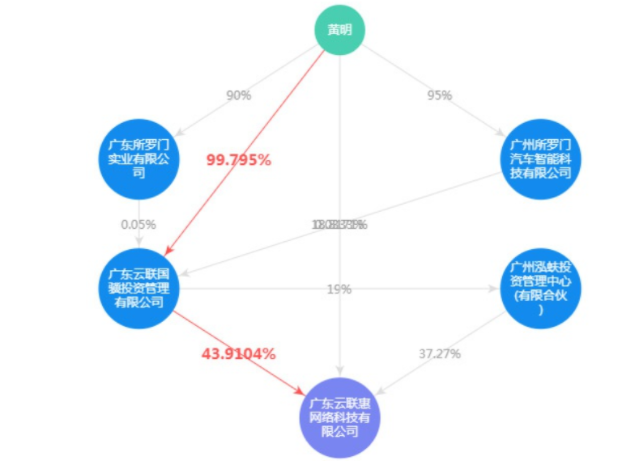
比如张三占A公司股权50%, 而A公司占B公司股权30%,那么股权穿透后张三实际占比A公司股权15%。当然张三可能还通过C公司来占有了B公司股权。通过这种企业和人构成的语义网络就很容易分析计算出具体的公司实控人等信息。
就当前来看,知识图谱的推理本身已经不是简单基于语义网络的语义模型和规则约束进行推理,而是和深度学习进行结合。即将语义模型导入到深度学习模型中,强化深度学习的推理和预测能力。
我们举个简单的例子,比如推荐系统和推荐引擎,实际核心仍然是基于采集的用户大量行为数据作为基础,但是同时如果导入了用户本身的朋友关系语义模型,那么整个推荐模型可能会更加准确。

1.我不是个瞎子,却找不到去你心里的道路。 2.你的心,我没有访问权。 3.习惯...
本文转载自网络,原文链接:https://www.toutiao.com/a6940687009992147492/...
3月16日消息,近日,市场研究和咨询公司Emergenresearch发布的报告显示,2020年...
机器人,工业之魂。 然而很少有人知道,日本,这个与我们一衣带水的国家,竟把持...
在科技日新月异的现代社会,一个具备现代化科技水平的IDC数据中心早已成为互联网...
过年啦!过年啦!小编在这里给各位网友拜个早年,祝各位网友新春大吉、身体健康、...
AI,也就是人工智能,近来似乎是每个人嘴边的话题。虽然我意识到这个技术发展的...
套接字是网络间通信的端点,套接字编程使这些端点能够传输数据,从而支持网络和...
许多城市已经陆续开放新冠病毒疫苗免费预约接种啦,想要接种疫苗的人群首先要遇...
苹果在去年秋季发布了 iOS 14 移动操作系统,为自家 iPhone / iPad 引入了新的沙...


