

本文转载自公众号“读芯术”(ID:AI_Discovery)。
本文将介绍强化学习算法的分类法,从多种不同角度学习几种分类法。话不多说,大家深呼吸,一起来学习RL算法的分类吧!

无模型(Model-Free)VS基于模型(Model-Based)
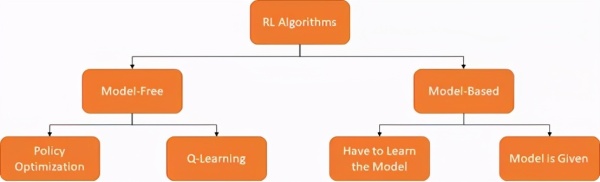
无模型VS模型分类法 [图源:作者,OpenAISpinning Up再创作]
RL算法的一种分类方法是询问代理是否能访问环境模型。换言之,询问环境会否响应代理的行为。基于这个观点有两个RL算法的分支:无模型和基于模型。
两种算法都各有优缺点,如下表所示:

基于价值VS 基于政策
RL算法的另一种分类方法是考虑算法优化了价值函数还是策略。在深入了解之前,我们先了解策略和价值功能。
(1) 策略
策略π是从状态s到动作a的映射,其中π(a | s)是在状态s时采取动作a的概率。策略可以是确定的,也可以是随机的。
假设我们在玩剪刀石头布这个非常简单的游戏,两个人通过同时执行三个动作(石头/剪刀/布)中的一个来比输赢。规则很简单:
把策略看作是迭代的剪刀石头布
(2) 价值函数
价值函数是根据对未来回报(返回值)的预测来衡量状态良好程度的函数。返回值(Gt)基本等于“折扣”回报的总和(自t时起)。

γ ∈ [0,1]是折扣因数。折扣因数旨在抵扣未来的回报,有以下几个原因:
了解了返回值的概念后,接下来定义价值函数的数学形式吧!
价值函数的数学形式有二:

状态-动作价值函数(Q值)是t时状态动作组合下的期望返回值:

Q值和价值函数之间的区别是动作优势函数(通常称为A值):

现在知道了什么是价值函数和动作-状态价值函数。接下来学习有关RL算法另一个分支的更多信息,该分支主要关注算法优化的组件。

价值算法与策略算法[图源:作者,David Silver RL课程再创作]
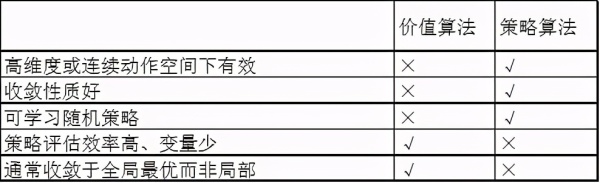
下表列出了价值和策略算法的优缺点。
策略和非策略算法
还有一种RL算法分类方法是基于策略来源分类。

可以说策略算法是“边做边学”。也就是说该算法试着从π采样的经验中了解策略π。而非策略算法是通过“监视”的方式来工作。换句话说,该算法试图从μ采样的经验中了解策略π。例如,机器人通过观察人类的行为来学习如何操作。


网络基础设施故障排除是一个多层次的过程--从模糊的 有问题 到具体问题的根本原...
全球各地的经济预测都显示出严峻的形势。冠状病毒第一次流行时使各国陷入停顿。6...
2019年,人脸识别进校园的案例密集出现,有一些学校引进了可以分析学生情绪的人...
同样的事情,苹果又玩了一次,这真不是故意的吗? 今天有不少开发者在社交网络上...
进入2021年以来,自动驾驶领域发展持续推进,即将过去的1月份,自动驾驶相关动态...
连续失去英国、比利时等重要市场后,华为5G进军欧洲的征途终于传来一点好消息。 ...
人脸识别是指使用人脸特征信息的身份分析进行身份认证的生物识别技术。作为一种...
据外媒,美国电信运营商Verizon近期引起了休斯敦部分居民的不满,据了解,该公司...
昨日,苹果召开发布会正式发布了第四代iPad Air与第八代iPad,然而这却让iPad产...
构建零信任架构通常要求对网络资源给予足够的访问权限,这样用户就可以完成他们...

