

基准项目地址:https://github.com/google-research/long-range-arena
论文地址:https://arxiv.org/pdf/2011.04006.pdf
Transformer 在多个模态(语言、图像、蛋白质序列)中获得了 SOTA 结果,但它存在一个缺点:自注意力机制的平方级复杂度限制了其在长序列领域中的应用。目前,研究人员提出大量高效 Transformer 模型(「xformer」),试图解决该问题。其中很多展示出了媲美原版 Transformer 的性能,同时还能有效降低自注意力机制的内存复杂度。
谷歌和DeepMind的研究人员对比了这些论文的评估和实验设置,得到了以下几点发现:
首先,高效 Transformer 缺少统一的基准测试,使用的任务类型也多种多样:每个模型在不同的任务和数据集上进行评估。
其次,评估所用基准通常是随意选择的,未充分考虑该任务是否适用于长程建模评估。
第三,很多论文将归纳偏置的效果和预训练的优点混为一谈,这会模糊模型的真正价值:预训练本身是计算密集型的,将归纳偏置和预训练分离开来可降低 xformer 研究的门槛。
于是,谷歌和DeepMind的研究人员提出了一个新基准Long-Range Arena (LRA),用来对长语境场景下的序列模型进行基准测试。该基准包括合成任务和现实任务,研究人员在此基准上对比了十个近期提出的高效 Transformer 模型,包括 Sparse Transformers、 Reformer 、Linformer、Longformer、Sinkhorn Transformer、 Performer 、Synthesizer、Linear Transformer 和 BigBird 模型。
该基准主要关注模型在长语境场景下的能力,不过研究人员对 xformer 架构在不同数据类型和条件下的能力也很感兴趣。因此,该基准选择了具备特定先验结构的数据集和任务。例如,这些架构可以建模层级结构长序列或包含某种空间结构形式的长序列吗?这些任务的序列长度从 1K 到 16K token 不等,还包括大量数据类型和模态,如文本、自然图像、合成图像,以及需要类似度、结构和视觉 - 空间推理的数学表达式。该基准主要面向高效 Transformer,但也可作为长程序列建模的基准。
除了对比模型质量以外,该研究还进行了大量效率和内存使用分析。研究者认为,并行性能基准测试对于社区是有益且珍贵的,能够帮助大家深入了解这些方法的实际效率。总之,该研究提出了一个统一框架,既能对高效 Transformer 模型进行简单的并行对比分析,还能对长程序列模型进行基准测试。该框架使用 JAX/FLAX1 编写。
高效 Transformer 评估新基准:Long-Range Arena (LRA)
基准需求
在创建 LRA基准之前,研究者先列举了一些需求:
1. 通用性:适用于所有高效 Transformer 模型。例如,并非所有 xformer 模型都能执行自回归解码,因此该基准中的任务仅需要编码。
2. 简洁性:任务设置应简单,移除所有令模型对比复杂化的因素,这可以鼓励简单模型而不是笨重的 pipeline 方法。
3. 挑战性:任务应该对目前模型有一定难度,以确保未来该方向的研究有足够的进步空间。
4. 长输入:输入序列长度应该足够长,因为评估不同模型如何捕获长程依赖是 LRA基准的核心关注点。
5. 探索不同方面的能力:任务集合应当评估模型的不同能力,如建模关系和层级 / 空间结构、泛化能力等。
6. 非资源密集、方便使用:基准应该是轻量级的,方便不具备工业级计算资源的研究者使用。
任务
LRA基准包含多项任务,旨在评估高效 Transformer 模型的不同能力。具体而言,这些任务包括:Long ListOps、比特级文本分类、比特级文档检索、基于像素序列的图像分类、Pathfinder(长程空间依赖性)、Pathfinder-X(极端长度下的长程空间依赖性)。
LRA 任务所需的注意力 范围
LRA基准的主要目标之一是评估高效 Transformer 模型捕获长程依赖的能力。为了对注意力机制在编码输入时需要考虑的空间范围进行量化估计,该研究提出了「所需注意力范围」(required attention span)。给出一个注意力模型和输入 token 序列,注意力模块的所需注意力范围是 query token 和 attended token 间的平均距离。
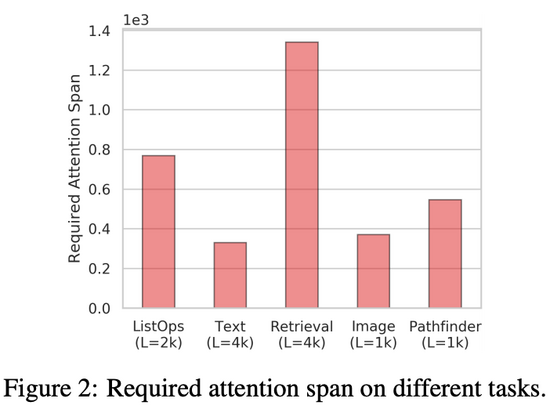
图 2 总结了 LRA基准中每项任务的所需注意力范围,从图中可以看出每项任务的所需注意力范围都很高。这表明,Transformer 模型不仅仅涉及局部信息,在很多任务和数据集中,注意力机制通常需要结合邻近位置的信息。
实验
量化结果
实验结果表明,LRA 中的所有任务都具备一定的挑战性,不同 xformer 模型的性能存在一定程度的差异。具体结果参见下表 1:

效率基准
表 2 展示了 xformer 模型的效率基准测试结果:
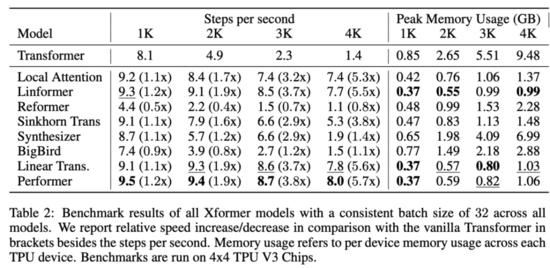
从中可以看出,低秩模型和基于核的模型通常速度最快。整体最快的模型是 Performer,在 4k 序列长度上的速度是 Transformer 的 5.7 倍,Linformer 和 Linear Transformer 紧随其后。最慢的模型是 Reformer,在 4k 序列长度上的速度是 Transformer 的 80%,在 1k 序列长度上的速度是 Transformer 的一半。
此外,研究者还评估了这些模型的内存消耗情况。结果显示,内存占用最少的模型是 Linformer,在 4k 序列长度上只使用了 0.99GB per TPU,而原版 Transformer 使用了 9.48GB per TPU,内存占用减少了约 90%。
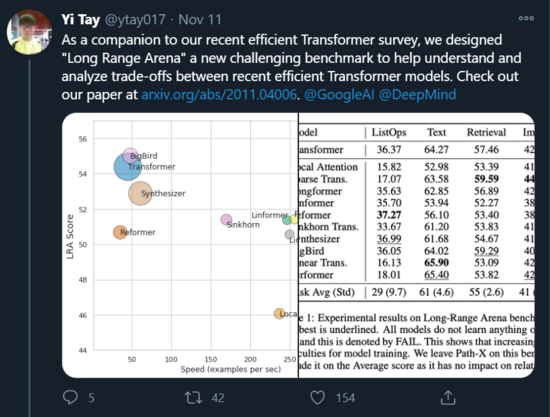
整体结果:不存在万能模型
根据研究人员的分析,在 LRA 所有任务中整体性能最好(LRA 分数最高)的模型是 BigBird。但是,BigBird 在每项任务中的性能均不是最好,它只是在所有任务上都能取得不错的性能。Performer 和 Linear Transformer 在一些任务中表现抢眼,但其平均分被 ListOps 任务拖累。
下图 3 展示了模型性能、速度和内存占用之间的权衡情况。BigBird 性能最好,但速度几乎与原版 Transformer 相同。而 Local Attention 模型速度很快,但性能较低。在这些模型中,基于核的模型(如 Performer、Linformer 和 Linear Transformer)能够在速度和性能之间获得更好的折中效果,同时内存占用也较为合理。


在一年一度的超级碗决赛之前,Amazon又发布了Alexa新形态的重磅广告。在广告中,...
根据发表在《 IET智能城市杂志》上的论文 COVID-19大流行:智慧城市应对新疫情的...
2 月 8 日消息, 高德地图近日发布 V10.76 新版本,上线真 AR 步行导航 ,借助智...
4月7日消息,据国外媒体报道,苹果公司正在考虑收购VR(虚拟现实)直播服务公司Nex...
截止至上周,今年二月初首次推出的 iOS/iPadOS 13.4 已经发布了第五个测试版本,...
随着5G 工业互联网应用场景加速拓展,政策支持力度持续加大,短板弱项逐步补强,...
苹果已做好了发布新款iPhone SE的准备,将于近期发布,而iPhone 12系列则是不同...
智能边缘正在将智能设备和物联网从数据收集点转变为真正的智能平台,这些平台可...
近期,《世界互联网发展报告2020》在世界互联网大会上发布,报告指出,当前世界...
全球销量最大的手机是谁家的?那必然是韩国三星的手机啊,三星的手机已经连续八年...

