

在这篇综述性文章中,作者详尽地介绍了多智能强化学习的理论基础,并阐述了解决各类多智能问题的经典算法。此外,作者还以 AlphaGo、AlphaStar为例,概述了多智能体强化学习的实际应用。
近年来,随着强化学习(reinforcement learning)在多个应用领域取得了令人瞩目的成果,并且考虑到在现实场景中通常会同时存在多个决策个体(智能体),部分研究者逐渐将眼光从单智能体领域延伸到多智能体。
本文将首先简要地介绍多智能体强化学习(multi-agent reinforcement learning, MARL)的相关理论基础,包括问题的定义、问题的建模,以及涉及到的核心思想和概念等。然后,根据具体应用中智能体之间的关系,将多智能体问题分为完全合作式、完全竞争式、混合关系式三种类型,并简要阐述解决各类多智能体问题的经典算法。最后,本文列举深度强化学习在多智能体研究工作中提出的一些方法(multi-agent deep reinforcement learning)。
1. 强化学习和多智能体强化学习
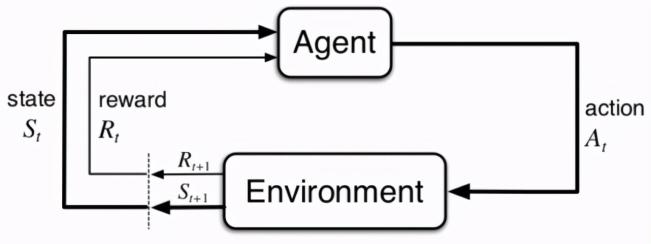
我们知道,强化学习的核心思想是“试错”(trial-and-error):智能体通过与环境的交互,根据获得的反馈信息迭代地优化。在 RL 领域,待解决的问题通常被描述为马尔科夫决策过程。

3月11日晚间消息,有媒体发现,腾讯QQ在微信上的小程序因违规被暂停服务。未使用...
人工智能(AI)已经踏入了诺贝尔奖领域。最近诞生了一项让人产生这种感觉的研究...
其实这篇iPhone 12的预测文案,我在一个月之前就写完了。那时刚做完一场直播,跟...
全球新冠肺炎大流行已经加速了医疗保健科技的使用。预计在2021年,5G和AI的结合...
1.你,就是我拒绝别人,一直单身的理由。 2.不敢说会陪你一辈子,但只要我在一...
在国内用户的想象中,5G的主要应用就是用5G手机来快速上网。而在国外,5G还有另...
二维码如今已经应用在生活的方方面面了,那么二维码的原理是什么呢?它为什么可以...
本月,新闻事件分析挖掘和搜索系统 NewsMiner 数据显示,人工智能领域共计发生 1...
2020年全年的营收增长情况虽然尚未公布,但是总体保持3%左右的正向增长已经是板...
2020年蔓延全球的新冠疫情彻底改变了企业的运营方式,也颠覆了团队协作与员工之...

