

在计算机视觉领域中,卷积神经网络(CNN)一直占据主流地位。不过,不断有研究者尝试将 NLP 领域的 Transformer 进行跨界研究,有的还实现了相当不错的结果。近日,一篇匿名的 ICLR 2021 投稿论文将标准 Transformer 直接应用于图像,提出了一个新的 Vision Transformer 模型,并在多个图像识别基准上实现了接近甚至优于当前 SOTA 方法的性能。
10 月 2 日,深度学习领域顶级会议 ICLR 2021 论文投稿结束,一篇将 Transformer 应用于图像识别的论文引起了广泛关注。
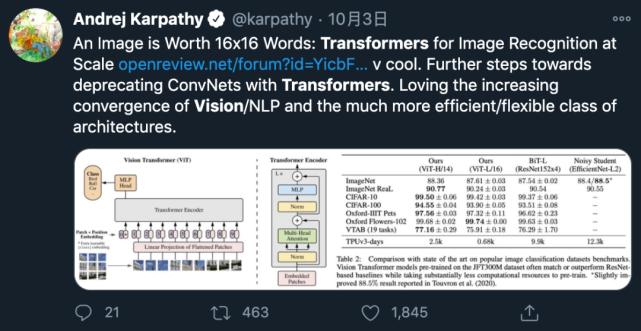
特斯拉 AI 负责人 Andrej Karpathy 转发了该论文,并表示「乐见计算机视觉和 NLP 领域日益融合」。

人工智能(AI)技术如今正在广泛应用。人工智能治理之所以重要,是因为人工智能可...
尽管智能城市的概念已经存在了几十年,但它最新的一次迭代是优先考虑技术,比如...
苹果为 iOS/iPadOS/watchOS/macOS 提供了各种自带应用,既覆盖了备忘录、提醒事...
随着移动设备的飞速发展, 无线网络联盟也宣布了 20 年来的最重大的一次升级,它...
2021年人工智能将如何改变药物研发、在家办公和边缘计算? 什么是近现代史中的黄...
APP界面布局设计是APP设计中非常重要的一环,合理的运用APP界面布局会让APP的界...
自去年6月,工信部正式向四家基础电信运营商发放5G牌照以来,无论是行业、资本市...
5G频段之争,你需要知道这些。 进入2020年,手机厂商们对于5G手机的商用推动突然...
10月底,苹果发布了iOS 13.2正式版,主要变化包括开启相机的Deep Fusion功能、允...
1 概述 全文分成四部分:通过「行业背景」看行业本质;通过「行业玩家」看行业生...

