


前言
作为冷数据启动和丰富数据的重要工具,爬虫在业务发展中承担着重要的作用,我们业务在发展过程中积累了不少爬虫使用的经验,在此分享给大家,希望能对之后的业务发展提供一些技术选型方向上的思路,以更好地促进业务发展
我们将会从以下几点来分享我们的经验
爬虫的应用场景
在生产上,爬虫主要应用在以下几种场景
爬虫的技术选型
接下来我们就由浅入深地为大家介绍爬虫常用的几种技术方案
简单的爬虫说起爬虫,大家可能会觉得技术比较高深,会立刻联想到使用像 Scrapy 这样的爬虫框架,这类框架确实很强大,那么是不是一写爬虫就要用框架呢?非也!要视情况而定,如果我们要爬取的接口返回的只是很简单,固定的结构化数据(如JSON),用 Scrapy 这类框架的话有时无异于杀鸡用牛刀,不太经济!
举个简单的例子,业务中有这么一个需求:需要抓取育学园中准妈妈从「孕4周以下」~「孕36个月以上」每个阶段的数据

对于这种请求,bash 中的 curl 足堪大任!
首先我们用 charles 等抓包工具抓取此页面接口数据,如下

通过观察,我们发现请求的数据中只有 month 的值(代表孕几周)不一样,所以我们可以按以下思路来爬取所有的数据:
1、 找出所有「孕4周以下」~「孕36个月以上」对应的 month 的值,构建一个 month 数组 2、 构建一个以 month 值为变量的 curl 请求,在 charles 中 curl 请求我们可以通过如下方式来获取
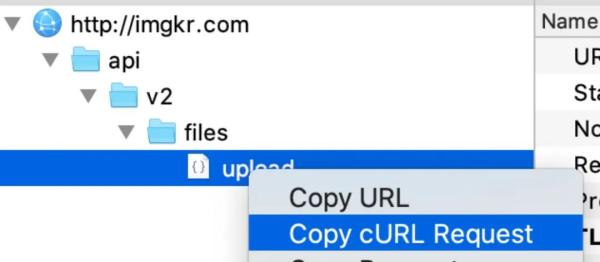
3、 依次遍历步骤 1 中的 month,每遍历一次,就用步骤 2 中的 curl 和 month 变量构建一个请求并执行,将每次的请求结果保存到一个文件中(对应每个孕期的 month 数据),这样之后就可以对此文件中的数据进行解析分析。
示例代码如下,为了方便演示,中间 curl 代码作了不少简化,大家明白原理就好
- #!/bin/bash
- ## 获取所有孕周对应的 month,这里为方便演示,只取了两个值
- month=(21 24)
- ## 遍历所有 month,组装成 curl 请求
- for month in ${month[@]};
- do
- curl -H 'Host: yxyapi2.drcuiyutao.com'
- -H 'clientversion: 7.14.1'
- ...
- -H 'birthday: 2018-08-07 00:00:00'
- --data "body=month%22%3A$month" ## month作为变量构建 curl 请求
- --compressed 'http://yxyapi2.drcuiyutao.com/yxy-api-gateway/api/json/tools/getBabyChange' > $var.log ## 将 curl 请求结果输出到文件中以便后续分析
- done
前期我们业务用 PHP 的居多,不少爬虫请求都是在 PHP 中处理的,在 PHP 中我们也可以通过调用 libcurl 来模拟 bash 中的 curl 请求,比如业务中有一个需要抓取每个城市的天气状况的需求,就可以用 PHP 调用 curl,一行代码搞定!

看了两个例子,是否觉得爬虫不过如此,没错,业务中很多这种简单的爬虫实现可以应付绝大多数场景的需求!
脑洞大开的爬虫解决思路
按以上介绍的爬虫思路可以解决日常多数的爬虫需求,但有时候我们需要一些脑洞大开的思路,简单列举两个
1、 去年运营同学给了一个天猫精选的有关奶粉的 url 的链接
- https://m.tmall.com/mblist/de_9n40_AVYPod5SU93irPS-Q.html,他们希望能提取此文章的信息,同时找到天猫精选中所有提到奶粉关键字的文章并提取其内容, 这就需要用到一些搜索引擎的高级技巧了, 我们注意到,天猫精选的 url 是以以下形式构成的
- https://m.tmall.com/mblist/de_ + 每篇文章独一无二的签名
利用搜索引擎技巧我们可以轻松搞定运营的这个需求
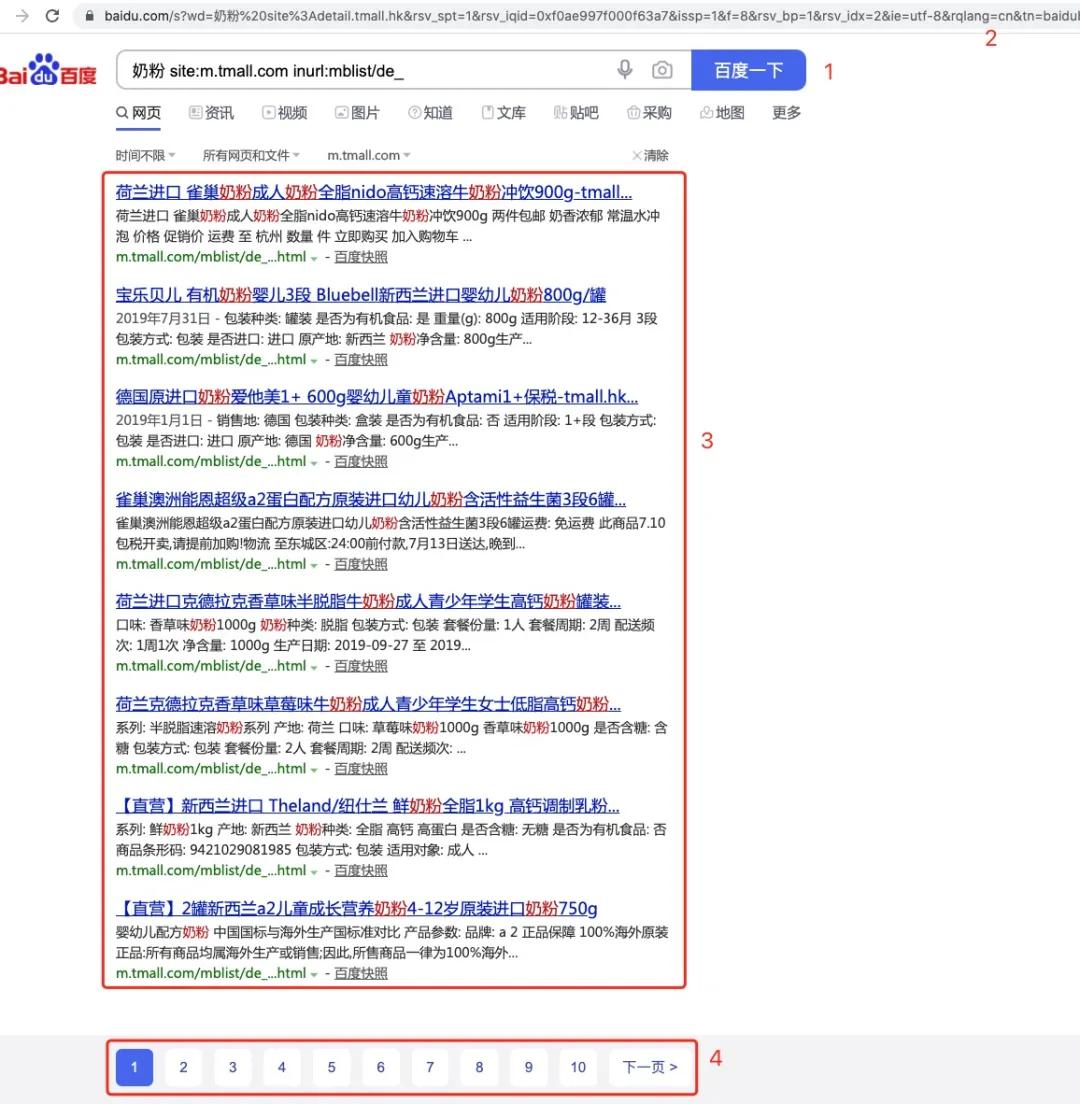
对照图片,步骤如下:
通过这种方式我们也巧妙地实现了运营的需求,这种爬虫获取的数据是个 html 文件,不是 JSON 这些结构化数据,我们需要从 html 中提取出相应的 url 信息(存在 标签里),可以用正则,也可以用 xpath 来提取。
比如 html 中有如下 div 元素
- <div id="test1">大家好!</div>

在出行越来越轻便化的当下,人们的出行只需要带手机即可。这归功于移动支付的便...
本文转载自公众号读芯术(ID:AI_Discovery) 人工智能在市场营销领域取得的成功,...
同样的覆盖,同样的带宽,同样的手机,同样的5G KPI运营商如何摆脱同质化竞争?依...
【责任编辑: 贺鑫 TEL:(010)68476606】 本文转载自网络,原文链接:...
本文转载自公众号读芯术(ID:AI_Discovery) 人工智能的应用越来越广泛,在我们日...
在电影中我们总能看到起死回生的桥段,在现实生活中也有冷冻人项目,目的是未来...
2月14日消息,腾讯QQ发布公告宣布紧急扩容,QQ群文件储存量升级至10G。 腾讯表示...
回顾过去的十余年,人工智能的进步可谓耀眼。尤其是从2015年阿法狗横空出世之后...
春节前夕,工业和信息化部(简称:工信部)官网发布了《关于提升5G服务质量的通知...
从2016年起,人工智能越来越频繁地进入到新闻里。其实,作为理工女,我从小的梦...

