

早在2018年底,FAIR的研究人员就发布了一篇名为《Rethinking ImageNet Pre-training》的论文 ,这篇论文随后发表在ICCV2019。该论文提出了一些关于预训练的非常有趣的结论。

近期,谷歌大脑的研究团队对这个概念进行了扩展,在新论文《Rethinking Pre-training and Self-training》中,不仅讨论了预训练,还研究了自训练,比较了在同一组任务当中自训练与监督预训练、自监督预训练之间的差异。

作者通过实验得出了以下结论:
以下是机器学习研究工程师Aakash Nain对《Rethinking Pre-training and Self-training》这篇论文的解读,文章发表在Medium上,AI科技评论对文章进行了编译。
一、序言
在进一步探讨论文细节之前,我们先了解一些术语。预训练是运用在不同领域(例如计算机视觉、自然语言处理、语音处理)的一种非常普遍的做法。在计算机视觉任务中,我们通常使用在某个数据集上经过预训练并可直接运用到另一个数据集的模型。例如,利用ImageNet预训练就是一种可广泛运用到目标分割和目标检测任务的初始化方法。为实现此目的,我们常使用迁移学习和微调这两种技术。另一方面,自训练也尝试在训练期间结合模型对未标记数据的预测结果,以获得其他可用的信息来改善模型性能。例如,使用ImageNet来改进COCO目标检测模型。首先在COCO数据集上训练模型,然后将该模型用于生成ImageNet的伪标签(我们将丢弃原始的ImageNet标签),最后将带有伪标签的ImageNet数据集和有标签的COCO数据集结合来训练一个新的模型。自监督学习是另一种常用的预训练方法。自监督学习的目的不仅仅是学习高级特征。相反,我们希望模型学习的更好,有更好的鲁棒性以适用于各种不同的任务和数据集。
二、研究动机
作者希望能解决以下问题:
三、设置
1、数据集和模型
2、数据增强
在所有实验中都使用了四种不同强度的增强策略来进行检测和分割。这四种策略按强度从低到高依次为:1)Augment-S1:这是标准“ 翻转和裁剪”增强操作,包括水平翻转和缩放裁剪。2)Augment-S2: 这包括论文《AutoAugment: Learning Augmentation Strategies from Data》中使用的AutoAugment,以及翻转和裁剪。3)Augment-S3:它包括大规模缩放、AutoAugment、翻转和裁剪。缩放范围比Augment-S1:更大。4)Augment-S4: 结合论文《RandAugment: Practical automated data augmentation with a reduced search space》中提出的RandAugment,翻转和裁剪,以及大规模缩放操作。此处的缩放等级与Augment-S2/S3相同。

3、预训练
为了研究预训练的有效性,作者使用了ImageNet预训练的检查点。使用EfficientNet-B7作为架构用于评估,对此模型,设置了两个不同的检查点,如下所示:1)ImageNet:通过AutoAugment在检查点上训练EfficientNet-B7,在ImageNet上达到84.5%了的top-1准确率。2)ImageNet ++:采用论文《Self-training with Noisy Student improves ImageNet classification》中提出的Noisy Student方法在检查点上训练EfficientNet-B7,其中利用了额外3亿张未标记的图像,并达到了86.9%的top-1准确率。采用随机初始化训练的结果标记为Rand Init。
4、自训练
自训练是基于Noisy Student方法实现的,有三个步骤:
四、实验
1、增强和标记数据集大小对预训练的影响
作者使用ImageNet进行监督预训练,并改变带标签的COCO数据集大小以研究预训练对结果的影响。实验过程中,不仅会改变标记数据的大小,而且还使用不同增强强度的数据集,使用以EfficientNet-B7为主干网络的RetinaNe模型来进行训练。作者观察到以下几点:
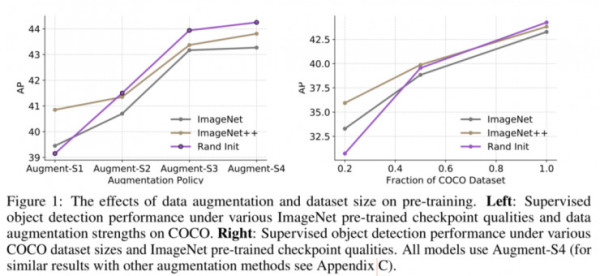
我的看法:在ImageNet上训练的大多数模型都没有使用很高强度的增强方法。高强度增强数据后,模型可能无法正确收敛。实际上,模型有时可能会对增强过拟合,当然这还需要进行适当的细节研究。
2、增强和标记数据集大小对自训练的影响
作者使用相同的模型(使用带有EfficientNet-B7主干的RetinaNet检测器)和相同的任务(COCO数据集目标检测)来研究自训练的影响。作者使用ImageNet数据集进行自训练(这种情况下将丢弃ImageNet的原始标签)。作者观察到以下几点:

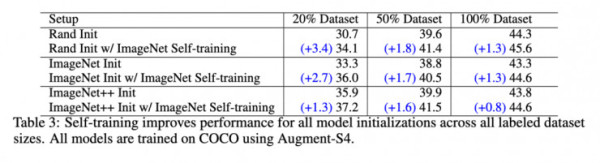
但,使用ImageNet ++ 预训练时,与使用随机初始化和ImageNet预训练相比,增益相对更小。这有什么具体原因吗?是的,ImageNet ++初始化是从检查点获得的,在该检查点使用了另外3亿张未标记的图像。
3、自监督预训练 vs 自训练
有监督的 ImageNet预训练会损害最大规模数据集和高强度数据增强下的训练效果。但是自监督的预训练呢?自监督学习(不带标签的预训练)的主要目标是构建一种通用的表征,这种表征可以迁移到更多类型的任务和数据集中。为研究自监督学习的效果,作者使用了完整的COCO数据集和最高强度的增强。目的是将随机初始化与使用了SOTA自监督算法预训练的模型进行比较。在实验中使用SimCLR的检查点,然后在ImageNet上对其进行微调。由于SimCLR仅使用ResNet-50,因此RetinaNet检测器的主干网络用ResNet-50替换。结果如下:
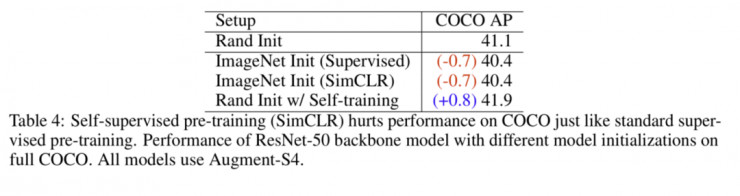
在这种情况下,我们观察到自监督下的预训练会损害训练效果,但自训练仍可以提高性能。
五、学到了什么?
1、预训练和通用的特征表征
我们看到,预训练(监督以及自监督)并不总可以给结果带来更好的效果。实际上,与自训练相比,预训练总是表现不佳。这是为什么?为什么ImageNet预训练的模型对COCO数据集的目标检测效果反而不好?为什么通过自监督预训练学习表征无法提高性能?预训练并不能理解当下的任务,并可能无法适应。分类问题比目标检测问题容易得多。在分类任务上预训练的网络是否可以获得目标检测任务所需要的所有信息?用我喜欢的表达方式来说:即使这些任务只是彼此的子集,不同的任务也需要不同级别的粒度。
2、联合训练
正如作者所言,自训练范式的优势之一是它可以联合监督和自训练目标进行训练,从而解决它们之间不匹配的问题。为了解决任务间由于差异导致的不匹配问题呢,我们也可以考虑联合训练的方法,例如联合训练ImageNet和COCO这两个数据集?作者在实验中使用了与自训练相同的参数设置,发现ImageNet的预训练可获得+ 2.6AP的增益,但使用随机初始化和联合训练可获得+ 2.9AP的更大增益。而且,预训练、联合训练和自训练都是加性的。使用相同的ImageNet数据集,ImageNet的预训练获得+ 2.6AP的增益,预训练+联合训练再获得+ 0.7AP的增益,而预训练+联合训练+自训练则获得+ 3.3AP的增益。

3、任务调整的重要性
正如我们在上文所见,任务调整对于提高性能非常重要。论文《Objects365: A Large-scale, High-quality Dataset for Object Detection》指出了类似的发现,在Open Images数据集上进行预训练会损害COCO的性能,尽管两者都带有边框标记。这意味着,我们不仅希望任务是相同的,而且标记最好也是相同的,以使预训练对结果真正带来益处。同时,作者指出了另外两个有趣的现象:

4、自训练的可扩展性、通用性和灵活性
从作者进行的所有实验中,我们可以得出以下结论:
在可扩展性方面,当我们拥有更多带标签的数据和更好的模型时,自训练被证明表现良好。
5、自训练的局限性
尽管自训练可以带来好处,但它也有一些局限性:
六、总结
《Rethinking Pre-training and Self-training》这篇论文提出了很多有关预训练、联合训练、任务调整和普遍表征的基本问题。解决这些问题比建立具有数十亿参数的模型更为重要,可以帮助我们获得更好的直觉,以了解深度神经网络做出的决策。

如今,随着电商发展的不断加快,物流送货压力持续增大,无人机正成为行业巨头们...
在过去的几年中,大量的软件开发技术已经发生了巨大的变化。DevOps成为一种规范...
当今安全和技术领域的 较大 趋势之一是围绕解决方案,这些解决方案利用了为世界...
本文转载自公众号读芯术(ID:AI_Discovery) 交友APP或许很多人都用过。约会AI的...
1月29日消息 微信 8.0 正在灰度内测专属红包功能,可在微信群中指定任意一人领取...
春节将至,原本欢乐祥和的气氛,却被各地散发的零星疫情给搞没了。特别是那些准...
机场安检就是防止旅客携带危险物品,例如:易爆、易燃、腐蚀物品和弹药枪支,以...
当谷歌打造的阿尔法狗击败了围棋特级大师,当辛辛那提大学的Psibernetix击败了战...
你可能已经听说过人工智能(通常用现在众所周知的缩写AI来描述)正在如何改变一个...
众所周知,我国运营商在布局5G方面的力度是非常积极的,尤其是去年在疫情得到有...

