一文掌握Spring Boot集成Druid数据源 | 技术创作特训营第一期
原创一文掌握Spring Boot集成Druid数据源 | 技术创作特训营第一期
原创
1. 前言?
????????Druid 身为阿里巴巴开源的一款数据库连接池,其结合了C3P0、DBCP 等 DB 池的优点,同时还加入了日志监控、URL监控、SQL监控等功能,如此便捷的开源工具,我们怎会不心动不去尝试玩一下?
? ? ? ? 所以,这期我们就围绕它进行重点讲解,那么,这将又会是干货满满的一期,全程无尿点不废话只抓重点教,具有非常好的学习效果,拿好小板凳准备就坐!希望学习的过程中大家认真听好好学,学习的途中有任何不清楚或疑问的地方皆可评论区留言或私信,bug菌将第一时间给予解惑,那么废话不多说,直接开整!Fighting!!?
2. 环境说明?
本地的开发环境: 开发工具:IDEA 2021.3 JDK版本: JDK 1.8 Spring Boot版本:2.3.1?RELEASE Maven版本:3.8.2
3. 正文?
3.1?Druid概述
???????Druid 是阿里巴巴开源的一款数据库连接池,结合了C3P0、DBCP 等 DB 池的优点,同时还加入了日志监控。
????????Druid 在 GitHub 上已经收获了 25.4k 的 star,可以说非常的知名,从简介上也能看得出,Druid 就是为了监控而生的。官方开源文档
3.2?Druid 组成?
Druid 包含了三个重要的组成部分:
DruidDriver,能够提供基于 Filter-Chain 模式的插件体系;
DruidDataSource,高效可管理的数据库连接池;
SQLParser,支持所有 JDBC 兼容的数据库,包括 Oracle、MySQL 等。
????????Spring Boot2.0 以上默认使用的是 Hikari 连接池,我们从之前的日志信息里就可以看得到。

3.3?Druid?项目整合?
那如果我们想使用 Druid 的话,该怎么整合呢?
3.3.1)?pom添加Druid依赖
????????在 pom.xml 文件中添加 Druid 的依赖,官方已经提供了 starter,我们直接使用即可。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.23</version>
</dependency>3.3.2)?yml 添加 Druid 配置
在 application.yml 文件中添加 Druid 配置。
????????Druid Spring Boot Starter 已经将 Druid 数据源中的所有模块都进行默认配置,我们也可以通过?Spring Boot 配置文件(application.properties/yml)来修改 Druid 各个模块的配置,否则将使用默认配置。
在 Spring Boot 配置文件中配置以下内容:
- JDBC 通用配置
- Druid 数据源连接池配置
- Druid 监控配置
- Druid?内置 Filter 配置
????????这些配置内容既可以在 application.properties 中进行配置,也可以在 application.yml 中尽心配置,当配置内容较多时,我们通常推荐使用 application.yml(示例中使用的是 application.yml)。
3.3.3)?JDBC 通用配置
????????我们可以在 Spring Boot 的配置文件中对 JDBC 进行通用配置,例如,数据库用户名、数据库密码、数据库 URL 以及 数据库驱动等等,示例代码如下:
################################################## JDBC 通用配置 ##########################################
spring:
datasource:
druid:
url: jdbc:mysql://localhost:3306/springboot_db?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8
username: root
password: 123456 #数据库名、用户名和密码改为自己的
driver-class-name: com.mysql.cj.jdbc.Driver3.3.4)?Druid 数据源连接池配置
????????我们还可以在 Spring Boot 的配置文件中对 Druid 数据源连接池进行配置,示例代码如下:
################################################## Druid连接池的配置 ##########################################
spring:
datasource:
druid:
initial-size: 5 #初始化连接大小
min-idle: 5 #最小连接池数量
max-active: 20 #最大连接池数量
max-wait: 60000 #获取连接时最大等待时间,单位毫秒
time-between-eviction-runs-millis: 60000 #配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
min-evictable-idle-time-millis: 300000 #配置一个连接在池中最小生存的时间,单位是毫秒
validation-query: SELECT 1 FROM DUAL #测试连接
test-while-idle: true #申请连接的时候检测,建议配置为true,不影响性能,并且保证安全性
test-on-borrow: false #获取连接时执行检测,建议关闭,影响性能
test-on-return: false #归还连接时执行检测,建议关闭,影响性能
pool-prepared-statements: false #是否开启PSCache,PSCache对支持游标的数据库性能提升巨大,oracle建议开启,mysql下建议关闭
max-pool-prepared-statement-per-connection-size: 20 #开启poolPreparedStatements后生效
filters: stat,wall #配置扩展插件,常用的插件有=>stat:监控统计 wall:防御sql注入
connection-properties: 'druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000' #通过connectProperties属性来打开mergeSql功能;慢SQL记录3.3.5)?Druid 监控配置
????????我们还可以在 Spring Boot 的配置文件中对 Druid 内置监控页面、Web-JDBC 关联监控和 Spring 监控等功能进行配置,示例代码如下:
###################################################### Druid 监控配置信息 ##########################################
spring:
datasource:
druid:
# StatViewServlet配置,说明请参考Druid Wiki,配置_StatViewServlet配置
stat-view-servlet:
enabled: true #是否开启内置监控页面,默认值为 false
url-pattern: '/druid/*' #StatViewServlet 的映射路径,即内置监控页面的访问地址
reset-enable: true #是否启用重置按钮
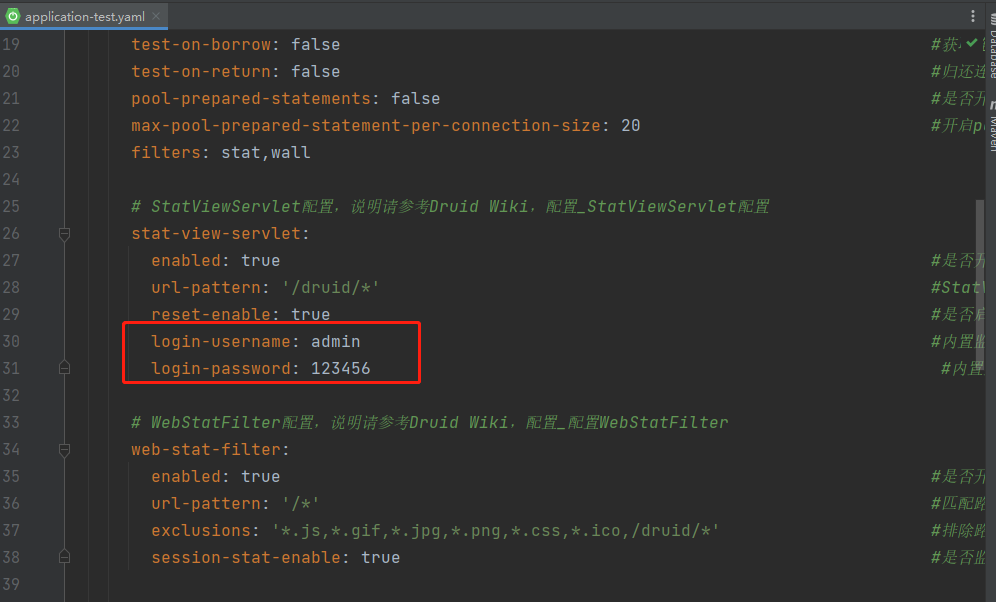
login-username: admin #内置监控页面的登录页用户名 username
login-password: admin #内置监控页面的登录页密码 password
# WebStatFilter配置,说明请参考Druid Wiki,配置_配置WebStatFilter
web-stat-filter:
enabled: true #是否开启内置监控中的 Web-jdbc 关联监控的数据
url-pattern: '/*' #匹配路径
exclusions: '*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*' #排除路径
session-stat-enable: true #是否监控session
# Spring监控配置,说明请参考Druid Github Wiki,配置_Druid和Spring关联监控配置
aop-patterns: net.biancheng.www.* #Spring监控AOP切入点,如x.y.z.abc.*,配置多个英文逗号分隔3.3.6)?Druid 内置 Filter 配置
Druid Spring Boot Starter 对以下 Druid 内置 Filter,都提供了默认配置:
- StatFilter
- WallFilter
- ConfigFilter
- EncodingConvertFilter
- Slf4jLogFilter
- Log4jFilter
- Log4j2Filter
- CommonsLogFilter
具体配置如下,仅供参考:
# ####################################################### Druid 监控配置信息 ##########################################
spring:
datasource:
druid:
# 对配置已开启的 filters 即 stat(sql 监控) wall(防火墙)
filter:
#配置StatFilter (SQL监控配置)
stat:
enabled: true #开启 SQL 监控
slow-sql-millis: 1000 #慢查询
log-slow-sql: true #记录慢查询 SQL
#配置WallFilter (防火墙配置)
wall:
enabled: true #开启防火墙
config:
update-allow: true #允许更新操作
drop-table-allow: false #禁止删表操作
insert-allow: true #允许插入操作
delete-allow: true #删除数据操作
????????在配置 Druid 内置 Filter 时,需要先将对应 Filter 的 enabled 设置为 true,否则内置 Filter 的配置不会生效。
????????以上所有内容都只是示例配置,Druid Spring Boot Starter 并不是只支持以上属性,它支持 DruidDataSource 内所有具有 setter 方法的属性。3.3.7)?Yaml配置汇总(现成参考)
spring:
datasource:
druid:
url: jdbc:mysql://localhost:3306/springboot_db?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8
username: root
password: 123456 #数据库名、用户名和密码改为自己的
driver-class-name: com.mysql.cj.jdbc.Driver
#数据源连接池配置
initial-size: 5 #初始化连接大小
min-idle: 5 #最小连接池数量
max-active: 20 #最大连接池数量
max-wait: 60000 #获取连接时最大等待时间,单位毫秒
time-between-eviction-runs-millis: 60000 #配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
min-evictable-idle-time-millis: 300000 #配置一个连接在池中最小生存的时间,单位是毫秒
validation-query: SELECT 1 FROM DUAL #测试连接
test-while-idle: true #申请连接的时候检测,建议配置为true,不影响性能,并且保证安全性
test-on-borrow: false #获取连接时执行检测,建议关闭,影响性能
test-on-return: false #归还连接时执行检测,建议关闭,影响性能
pool-prepared-statements: false #是否开启PSCache,PSCache对支持游标的数据库性能提升巨大,oracle建议开启,mysql下建议关闭
max-pool-prepared-statement-per-connection-size: 20 #开启poolPreparedStatements后生效
filters: stat,wall
# StatViewServlet配置,说明请参考Druid Wiki,配置_StatViewServlet配置
stat-view-servlet:
enabled: true #是否开启内置监控页面,默认值为 false
url-pattern: '/druid/*' #StatViewServlet 的映射路径,即内置监控页面的访问地址
reset-enable: true #是否启用重置按钮
login-username: admin #内置监控页面的登录页用户名 username
login-password: 123456 #内置监控页面的登录页密码 password
# WebStatFilter配置,说明请参考Druid Wiki,配置_配置WebStatFilter
web-stat-filter:
enabled: true #是否开启内置监控中的 Web-jdbc 关联监控的数据
url-pattern: '/*' #匹配路径
exclusions: '*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*' #排除路径
session-stat-enable: true #是否监控session
# Spring监控配置,说明请参考Druid Github Wiki,配置_Druid和Spring关联监控配置
aop-patterns: net.biancheng.www.* #Spring监控AOP切入点,如x.y.z.abc.*,配置多个英文逗号分隔
# 对配置已开启的 filters 即 stat(sql 监控) wall(防火墙)
filter:
#配置StatFilter (SQL监控配置)
stat:
enabled: true #开启 SQL 监控
slow-sql-millis: 1000 #慢查询
log-slow-sql: true #记录慢查询 SQL
#配置WallFilter (防火墙配置)
wall:
enabled: true #开启防火墙
config:
update-allow: true #允许更新操作
drop-table-allow: false #禁止删表操作
insert-allow: true #允许插入操作
delete-allow: true #删除数据操作????????至此,我们就完成了使用?Druid Spring Boot Starter 整合 Druid 的全部过程,至于验证步骤请参考如下。
3.4?Druid测试
3.4.1)?配置Druid的监控配置
主要是在application.properties中添加Druid的监控配置。上边我们已经配置过了,具体如下:
3.4.2)?定义Controller请求
? ? ? ? 定义接口请求,我们创建一个Controller来通过接口去调用数据访问操作:
UserController.java
package com.example.connectmysqldemo.controller;
import com.example.connectmysqldemo.entity.UserEntity;
import com.example.connectmysqldemo.service.UserService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import io.swagger.annotations.ApiParam;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
* 用户管理分发器
*/
@RestController
@RequestMapping("/user")
@Api(tags = "用户管理模块", description = "用户管理模块")
public class UserController {
@Autowired
private UserService userService;
/**
* 不查询db所有用户信息
*/
@GetMapping("/get-users")
@ApiOperation(value = "不查询db所有用户信息", notes = "不查询db所有用户信息")
public List<UserEntity> getUserList1() {
return userService.getUsers();
}
/**
* 根据性别查询所有用户
*
* @param sex 性别
*/
@GetMapping("/get-users-by-sex")
@ApiOperation(value = "根据性别查询所有用户", notes = "根据性别查询所有用户")
public List<UserEntity> getUsersBySex(@RequestParam(name = "sex") String sex) {
return userService.getUsersBySex(sex);
}
/**
* 根据用户id查询用户信息
*
* @param userId
* @return
*/
@GetMapping("/getUser-by-id")
@ApiOperation(value = "根据用户id查询用户信息", notes = "根据用户id查询用户信息")
public UserEntity getUserById(@RequestParam(name = "userId") @ApiParam("请输入用户id") String userId) {
return userService.getById(userId);
}
}UserService.java
package com.example.connectmysqldemo.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.example.connectmysqldemo.entity.UserEntity;
import java.util.List;
/**
* 用户管理业务层接口
*/
public interface UserService extends IService<UserEntity> {
/**
* 不分页查询所有用户信息
*/
List<UserEntity> getUsers();
List<UserEntity> getUsers2();
/**
* 根据性别查询所有用户
*
* @param sex 性别
*/
List<UserEntity> getUsersBySex(String sex);
UserEntity getUserById(String id);
}UserServiceImpl.java
package com.example.connectmysqldemo.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.connectmysqldemo.dao.UserMapper;
import com.example.connectmysqldemo.entity.UserEntity;
import com.example.connectmysqldemo.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* 用户管理业务层
*/
@Service
@Slf4j
public class UserServiceImpl extends ServiceImpl<UserMapper, UserEntity> implements UserService {
@Autowired
private UserMapper userMapper;
/**
* 查询db1的用户数据
*/
@Override
public List<UserEntity> getUsers() {
return this.list();
}
/**
* 查询db2的用户数据
*/
@Override
public List<UserEntity> getUsers2() {
return this.list();
}
/**
* 根据性别查询所有用户
*
* @param sex 性别
*/
@Override
public List<UserEntity> getUsersBySex(String sex) {
//条件构造器
QueryWrapper<UserEntity> wrapper = new QueryWrapper<>();
//eq 代表“ = ”;例如 eq("sex", "男") ---> sex = '男';等同于拼接在sql语句后边的where条件。
wrapper.eq("sex", sex);
//将条件带入返回
List<UserEntity> list = this.list(wrapper);
//返回数据
// wrapper.ge("age","11"); =>age>=11
return list;
}
@Override
public UserEntity getUserById(String id) {
LambdaQueryWrapper<UserEntity> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(UserEntity::getId, id);
wrapper.ge(UserEntity::getAge, 11);
return this.getOne(wrapper);
}
public boolean updateByUserId() {
return true;
}
/**
* 根据用户id修改用户信息
*/
public List<UserEntity> getUsersByIdAndDate(Integer userId, Integer age) {
//lambda条件构造器
LambdaQueryWrapper<UserEntity> queryWrapper = new LambdaQueryWrapper<>();
//传入条件
queryWrapper.eq(UserEntity::getId, userId);
queryWrapper.eq(UserEntity::getAge, age);
//调用修改方法
return this.list(queryWrapper);
}
}UserMapper.java
/**
* 用户管理持久层
*/
@Component
public interface UserMapper extends BaseMapper<UserEntity> {
}启动器添加Mapper扫描
ConnectMysqlDemoApplication.java
package com.example.connectmysqldemo;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Configuration;
@SpringBootApplication
@Configuration
@EnableCaching
@MapperScan({"com.example.connectmysqldemo.dao"})// 扫描mybatis的映射器
public class ConnectMysqlDemoApplication {
public static void main(String[] args) {
SpringApplication.run(ConnectMysqlDemoApplication.class, args);
}
}? ? ? ? 以上知识点,我会在后期一点一点给大家讲解,目前先不增加学习负担,这里就先这么用着,你们可以先拷贝拿去用。
????????完成上面所有配置之后,启动应用,访问Druid的监控页面?http://localhost:8080/druid/,可以看到如下登录页面:?
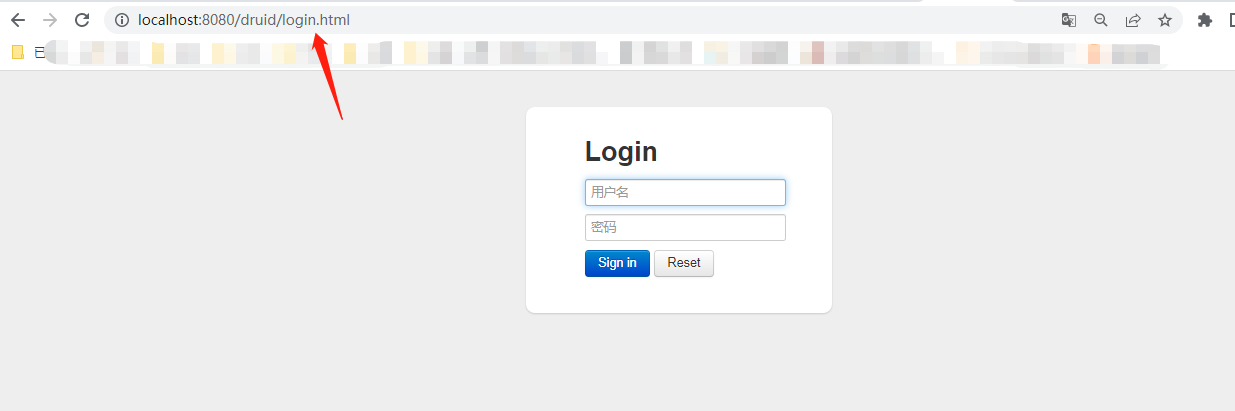
? ? ? ? 以上登录账号密码也就是3.4.1点提到的,你们看自己设置的啥。
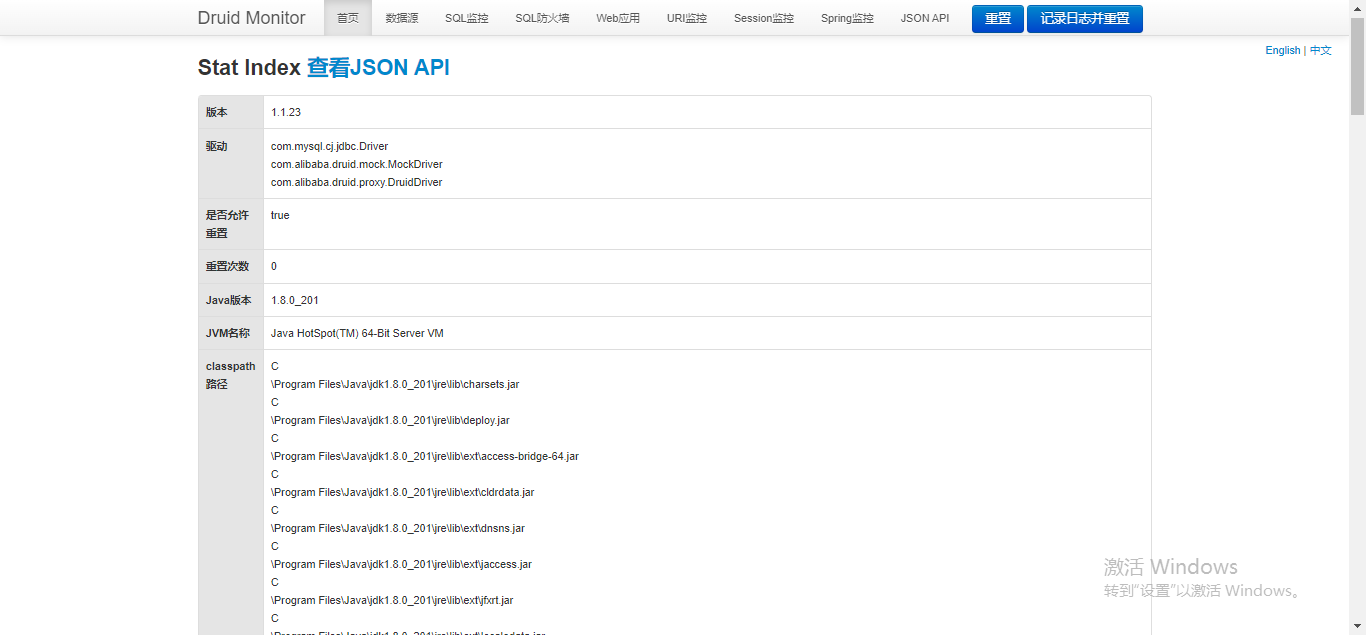
login-username: admin
login-password: 123456 ????????输入点击登录就能看到如下监控页面:
????????进入到这边时候,就可以看到对于应用端而言的各种监控数据了。这里讲解几个最为常用的监控页面:
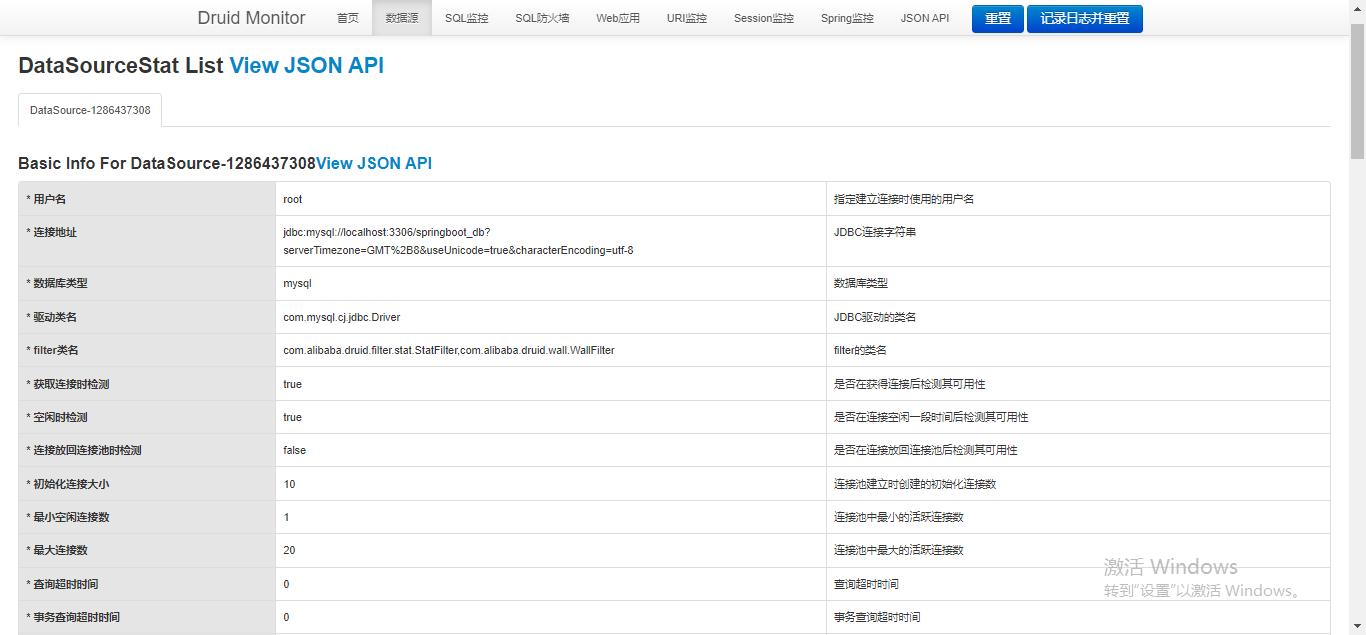
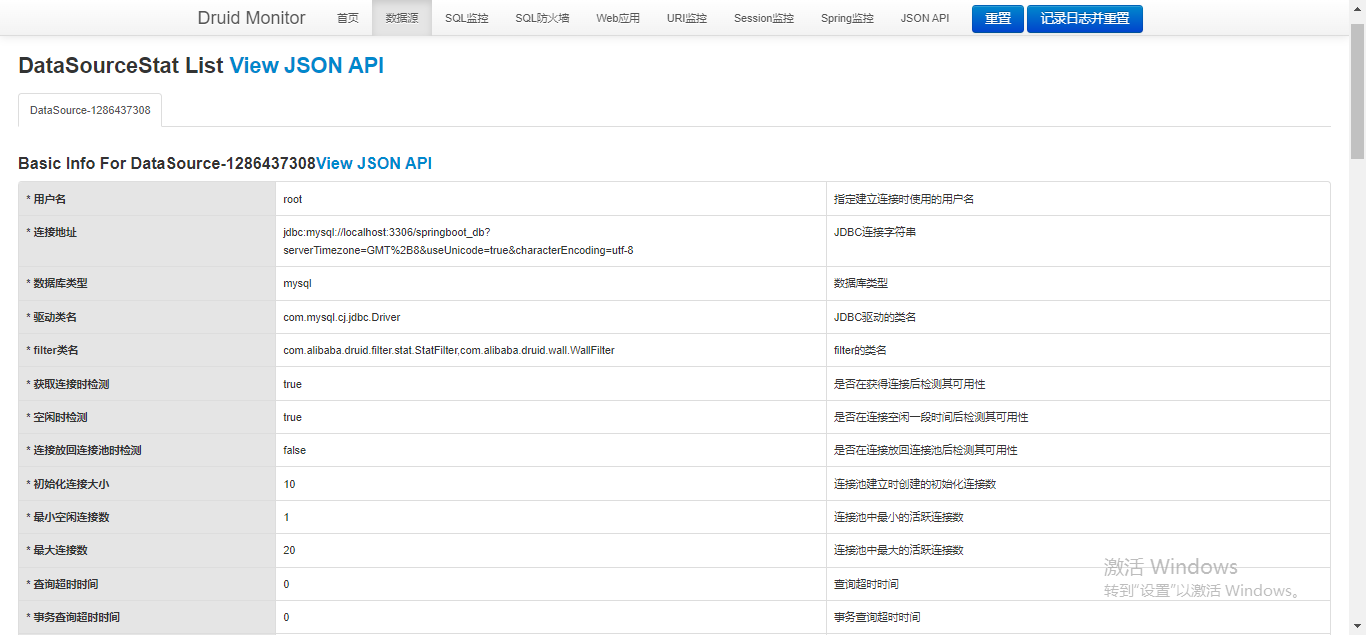
3.4.3)?数据源
????????这里可以看到之前我们配置的数据库连接池信息以及当前使用情况的各种指标。
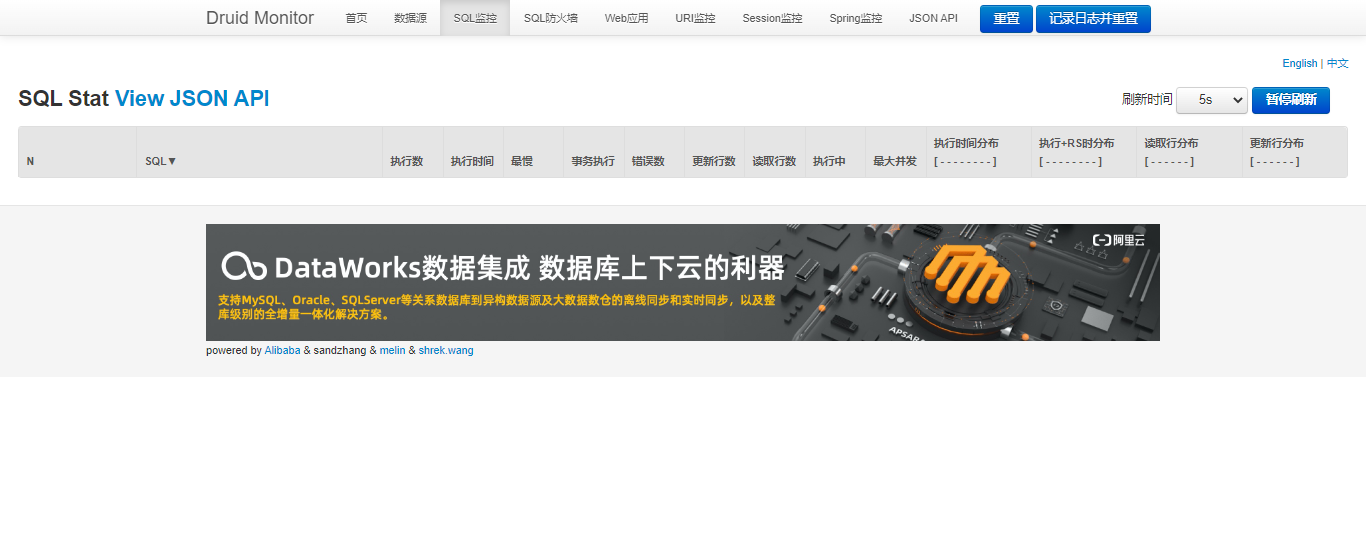
3.4.4)?Druid 监控功能-SQL监控
????????SQL监控:该数据源中执行的SQL语句极其统计数据。在这个页面上,我们可以很方便的看到当前这个Spring Boot都执行过哪些SQL,这些SQL的执行频率和执行效率也都可以清晰的看到。如果你这里没看到什么数据?别忘了我们之前创建了一个Controller,用这些接口可以触发UserService对数据库的操作。所以,这里我们可以通过调用接口的方式去触发一些操作,这样SQL监控页面就会产生一些数据:
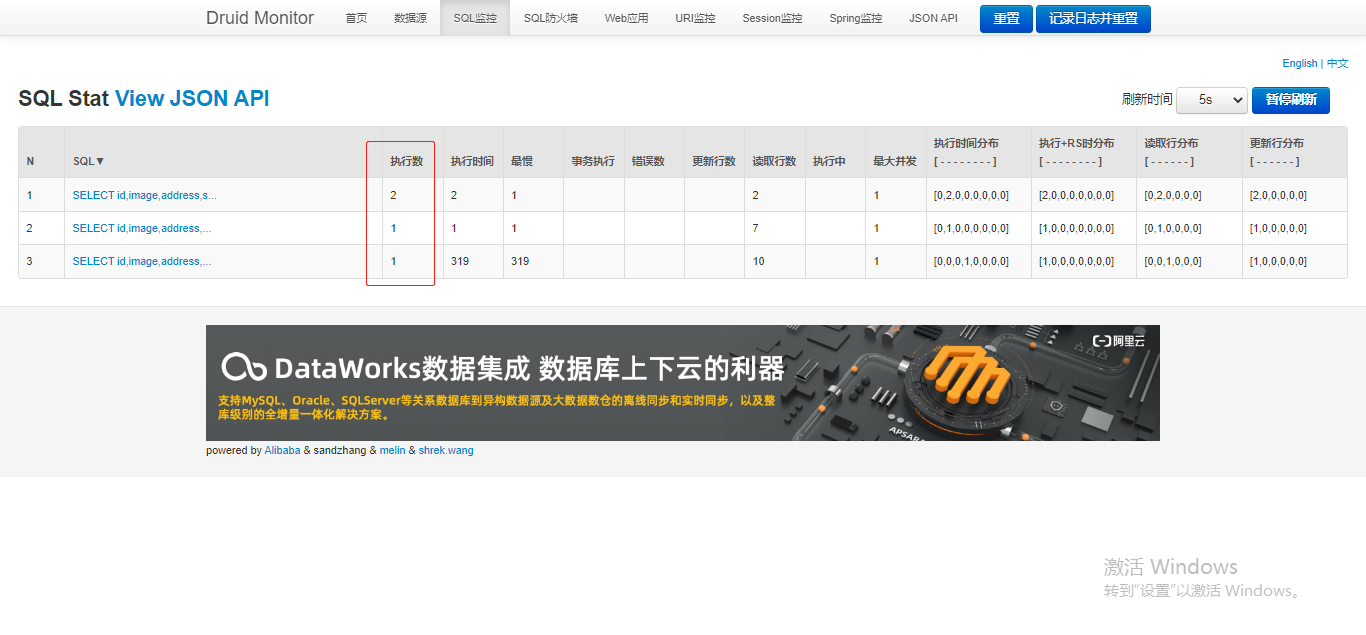
分别调用几次请求后我们再查看,可以完全统计调用接口次数,执行时间,读取行数等信息。
3.4.5?Durid 监控功能-SQL 防火墙
????????SQL防火墙:该页面记录了与SQL监控不同维度的监控数据,更多用于对表访问维度、SQL防御维度的统计。
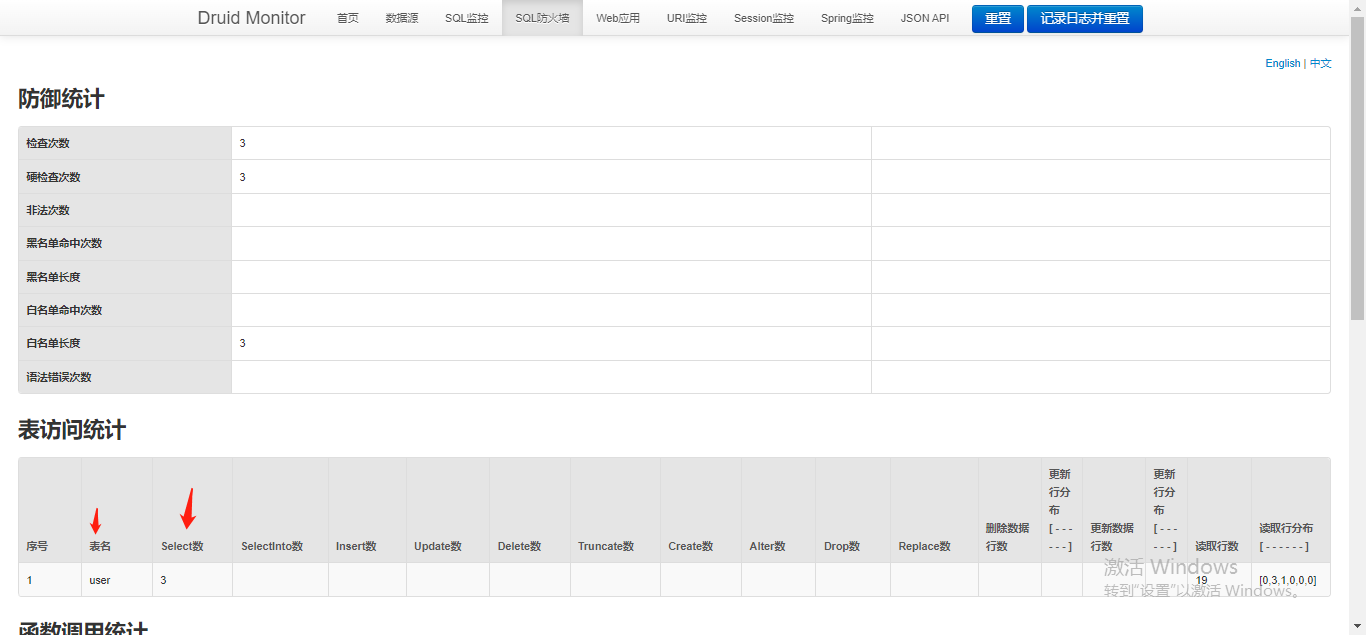
????????该功能数据记录的统计需要在spring.datasource.druid.filters中增加wall属性才会进行记录统计,比如这样:
filters: stat,wall????????注意:这里的所有监控信息是对这个应用实例的数据源而言的,而并不是数据库全局层面的,可以视为应用层的监控,不可能作为中间件层的监控。
3.4.6?Durid 监控功能-Web 关联监控
????????Druid 还内置提供了一个名为 WebStatFilter 的过滤器,它可以用来监控与采集 web-jdbc 关联监控的数据。
3.4.6.1)重启 Spring Boot项目,浏览器访问http://localhost:8080/druid
3.4.6.2)浏览器访问 AdminEx 系统的任意页面,然后再访问 Druid 的内置监控页面,切换到 Web 应用模块,可以看到 Druid 的 Web 监控已经开启,如下图:
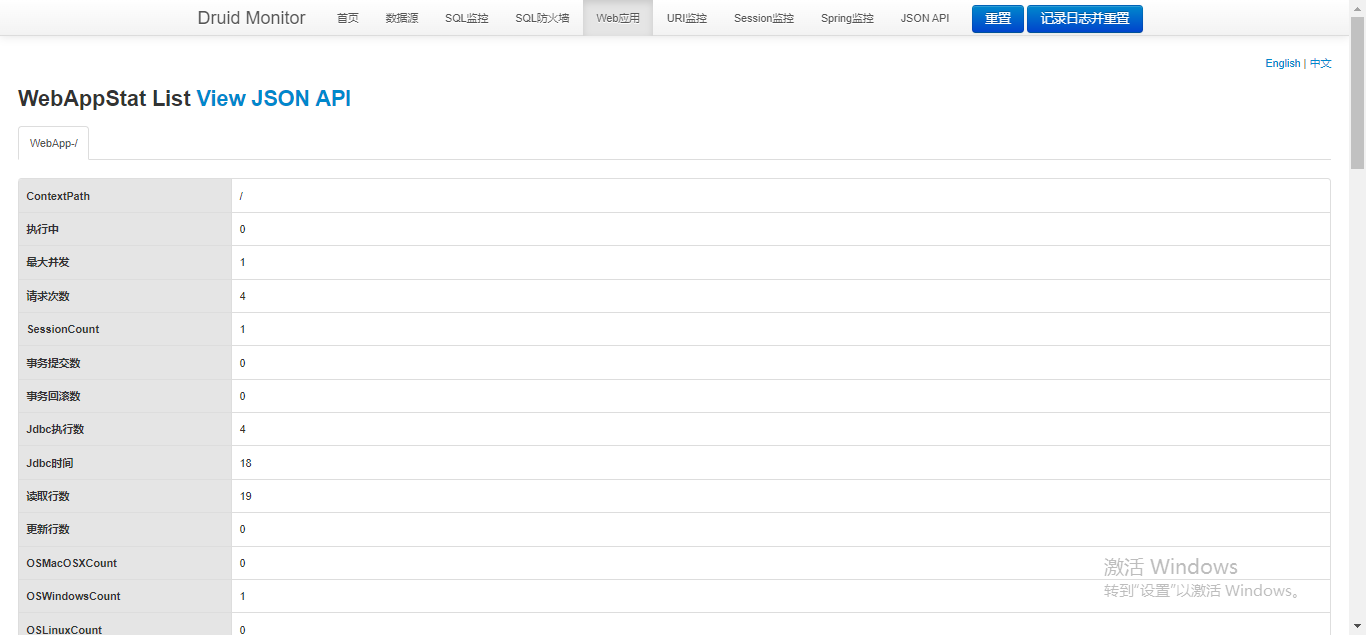
????????与此同时,URI 监控和 Session 监控也都被开启,如下图。
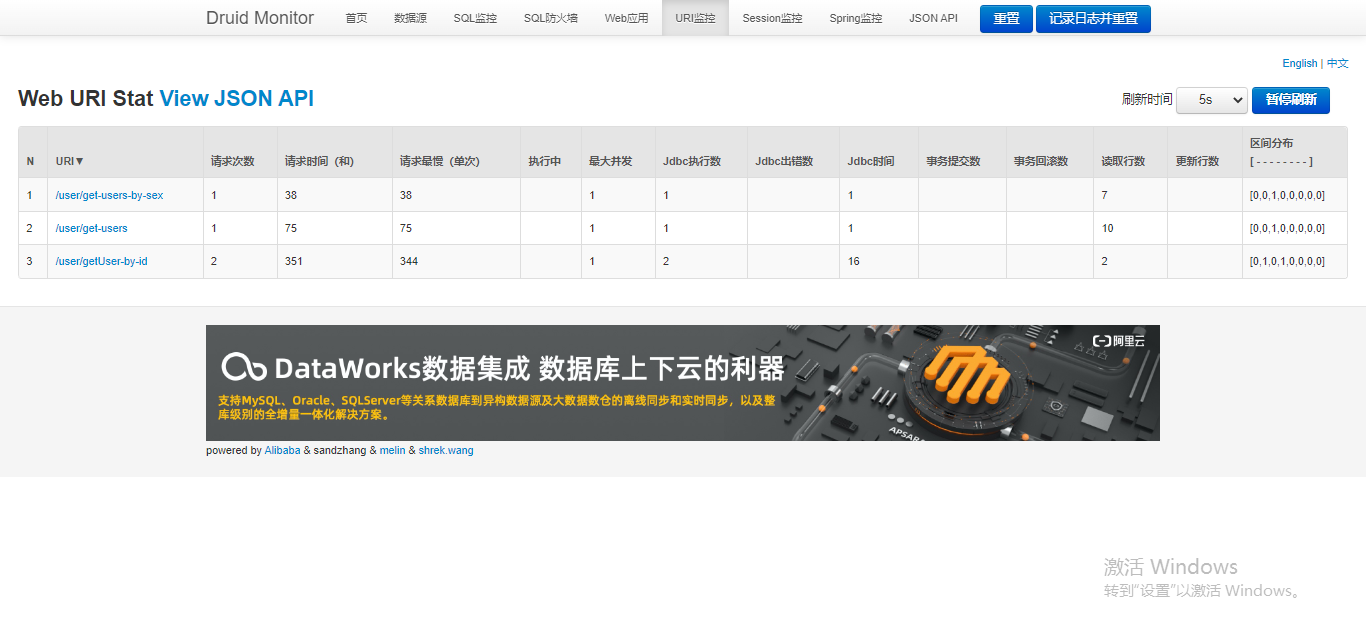
3.4.7?Durid 监控功能-URI 监控
? ? ? ? 可以看到URI 监控开启正常,如下图。
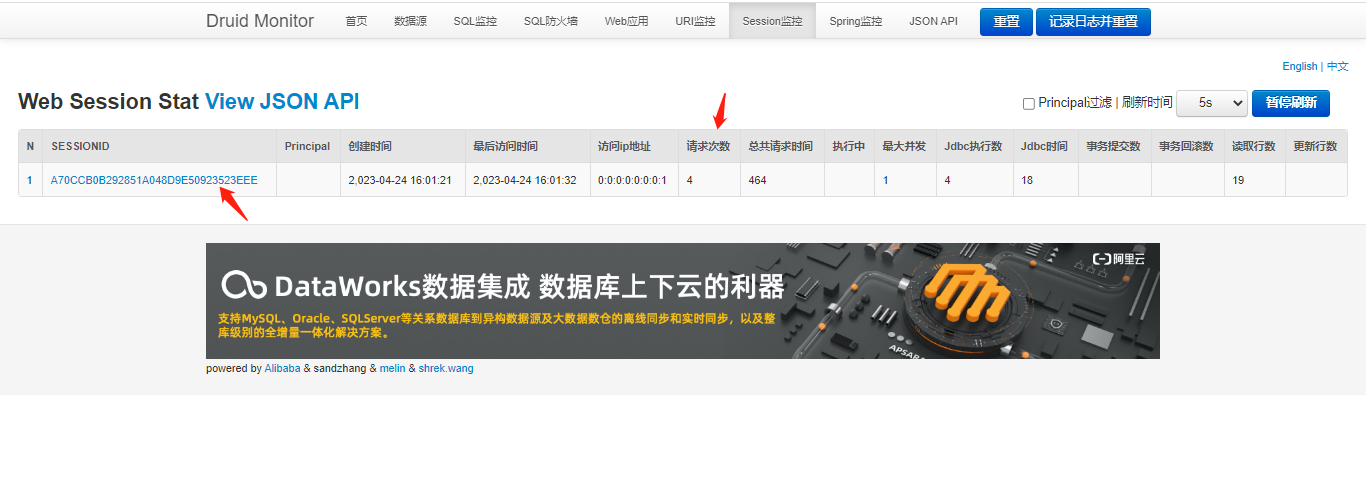
3.4.8?Durid 监控功能-Session 监控
? ? ? ? 可以看到Session监控开启正常,如下图。
3.5?总结
????????无论是自定义整合还是通过 Druid Spring Boot Starter 整合,都能实现 Spring Boot 整合 Druid 数据源的目的,它们都各有利弊。
????????根据官方文档,自定义整合 Druid 数据源能够更加清晰地了解 Druid 的各种功能及其实现方式,但整合过程繁琐。
????????通过?Druid Spring Boot Starter 整合 Druid 数据源,则更加方便快捷,大大简化了整合过程,但无法清晰地了解 Druid 的功能内部的实现方式和原理。
????????这里,我们更加推荐使用?Druid Spring Boot Starter 进行整合,毕竟这种整合方式大大简化了整个整合的过程。
-End-
原创作者|bug菌
【选题思路】
????????Druid作为阿里的一款开源且全功能性数据库连接池,拥有丰富的功能和可自定义配置选项,是一个高效的并发连接管理工具,可大幅提升应用程序的数据库访问效率,而且它支持对于许多不同类型的数据库,例如 MySQL、Oracle、PostgreSQL 和 SQL Server 等,可以说Druid是目前最好的数据库连接池,它不仅支持监控统计、防御SQL注入等功能,切实体验度极好,是中大厂的不二之选。本文重在介绍Druid的功能及如何集成使用,代码实践演示可视化界面的功能模型,引领更多的初学者能够了解并掌握。
【创作提纲】
- 科普Druid数据库连接池的概念及Druid的组成,让初学在对它有个基本的认识。
- 通过Spring Boot项目代码实践,讲解如何整合Druid数据库连接池及基本配置项。
- 重点介绍Druid的连接配置、比如连接池配置、监控配置、Filter 配置等。
- 通过书写测试类的方法演示Druid的功能点,比如SQL监控、Web关联监控、URI 监控、URI 监控等。
- 对比多种集成Druid数据库连接池的方式及优缺点,得出最有集成结论。
- 全篇以理论+实践的讲述模式,演绎Druid连接池的认识与使用,帮助更多的初学者能够快速掌握。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。