Nat. Mach. Intell. | 评估基于shapely值的特征归因算法
Nat. Mach. Intell. | 评估基于shapely值的特征归因算法

编译 | 曾全晨 审稿 | 王建民
今天为大家介绍的是来自Su-In Lee研究团队的一篇关于shapely value特征归因的论文。基于Shapley值的特征归因在解释机器学习模型方面非常流行。然而,从理论和计算的角度来看,它们的估计是复杂的。作者将这种复杂性分解为两个主要因素:去除特征信息的方法和可行的估计策略。这两个因素提供了一个自然的视角使得我们可以更好地理解和比较24种不同的算法。

机器学习模型越来越普遍,它们在许多应用中已经达到或超过了人类的表现。它们成功的一个关键组成部分是灵活性或表达能力,这得益于更复杂的模型和不断改进的硬件。不幸的是,它们的灵活性也使得模型不透明,难以为人类理解。再加上机器学习倾向于依赖捷径(即未经意的学习策略,无法推广到未见过的数据),对模型可解释性的需求越来越大。有许多可能的方法可以解释机器学习模型,但其中一种非常流行的方法是“局部特征归因”。一个著名的例子是LIME(局部可解释的模型无关解释),它适配一个简单的模型来捕捉单个样本周围的模型行为;当使用线性模型时,系数被用作每个特征的归因分数。除了LIME之外,还有一个流行的方法类别是加法特征归因方法,这些方法的归因之和等于特定值,例如模型的预测结果。
为了统一加法特征归因方法的类别,Lundberg和Lee引入了SHAP作为独特的解。它的唯一性取决于基于被解释模型定义一个合作博弈或集合函数。Lundberg和Lee最初将该博弈定义为在给定一组观察特征的条件下,模型输出的期望;然而,考虑到实际计算条件期望的困难,作者建议使用边际期望,忽略观察特征与未观察特征之间的依赖关系。这种复杂性导致了不同的Shapley值方法,它们在如何去除特征以及对这两种方法与因果干预或信息论之间的后续解释上存在差异。在整个工作中,作者将基于Shapley值的所有特征归因称为Shapley值解释。在定义合作博弈的同时,解释Shapley值面临的另一个挑战是计算复杂度与特征数量呈指数关系。因此,原始的SHAP论文讨论了几种逼近Shapley值的策略,包括加权线性回归(KernelSHAP)、特征组合抽样(IME)以及几种模型特定的逼近方法。自原始工作以来,研究人员已经开发出其他更高效估算Shapley值解释的方法,包括模型无关方法以及模型特定方法。在这两种类别中,模型无关方法更加灵活但是具有随机性,而模型特定方法更快但有潜在偏差。为了更好地理解模型无关方法,作者提出了一种基于Shapley值不同数学定义的逼近算法分类,并对它们的收敛性进行了实证比较(然后,为了更好地理解模型特定方法,作者强调了每种方法的关键假设。这两个挑战,即正确移除特征和准确逼近Shapley值,是导致该领域涌现出大量论文和算法的复杂性源泉。不幸的是,算法的丰富性和该主题固有的复杂性使得文献难以理解。
特征归因
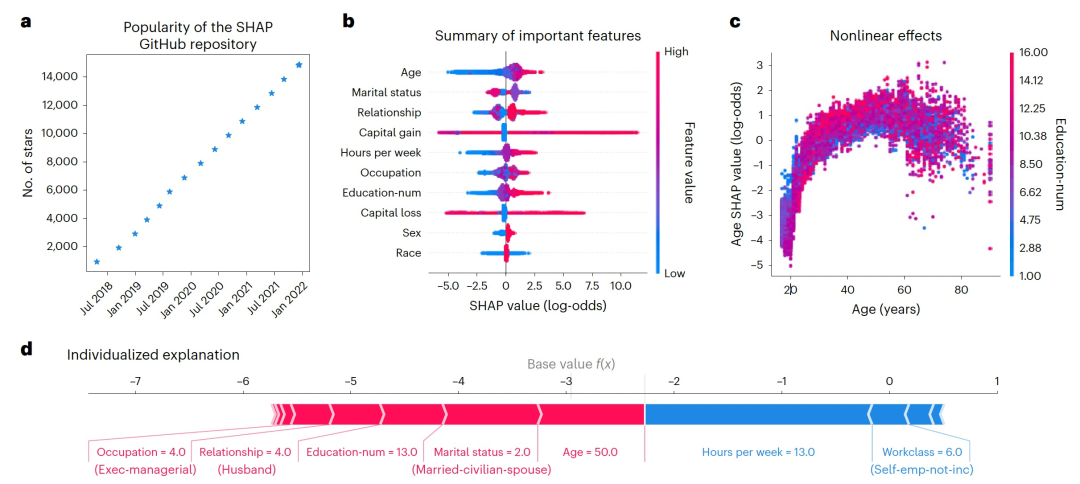
图 1
给定一个模型f和输入特征,特征归因通过分配表示每个特征重要性的标量值来解释预测结果。为了直观地描述特征归因,可以考虑线性模型的情况。线性模型的形式为通常被认为是可解释的,因为每个特征通过一个参数与预测值线性相关。在这种情况下,一种常见的全局特征归因是描述模型对特征i的整体依赖的相应系数。对于线性模型,每个系数描述了对应特征的变化对模型输出的影响。
或者,可能更倾向于提供个性化的解释,而不是整体描述模型,而是针对特定样本给出预测的解释。这种类型的解释被称为局部特征归因,而被解释的样本被称为解释对象。对于线性模型,一个合理的局部特征归因是当前对象特征i与其系数的乘积,因为这恰好是特征i对模型预测的贡献。然而,请注意,这种归因隐含地将当前特征与其空值时相比较。相反,我们可能希望考虑基于特征的概率分布的替代值,或者考虑特征与其他特征的统计关系。线性模型提供了一个简单的情况,我们可以通过模型参数了解每个特征的作用,但这种方法在更复杂的模型中无法自然延伸。对于当今最广泛使用的模型类型,包括树集成和深度学习模型,大量的操作使得我们无法通过检查模型参数来理解每个特征的作用。这些灵活的非线性模型可以捕捉到数据中更多的模式,但它们要求我们开发更复杂和可推广的特征重要性概念。因此,许多研究人员开始转向Shapley值解释,以识别重要特征(如图1b中的汇总图)、揭示非线性效应(如图1c中的依赖图)和提供个性化解释(如图1d图)。
Shapley values
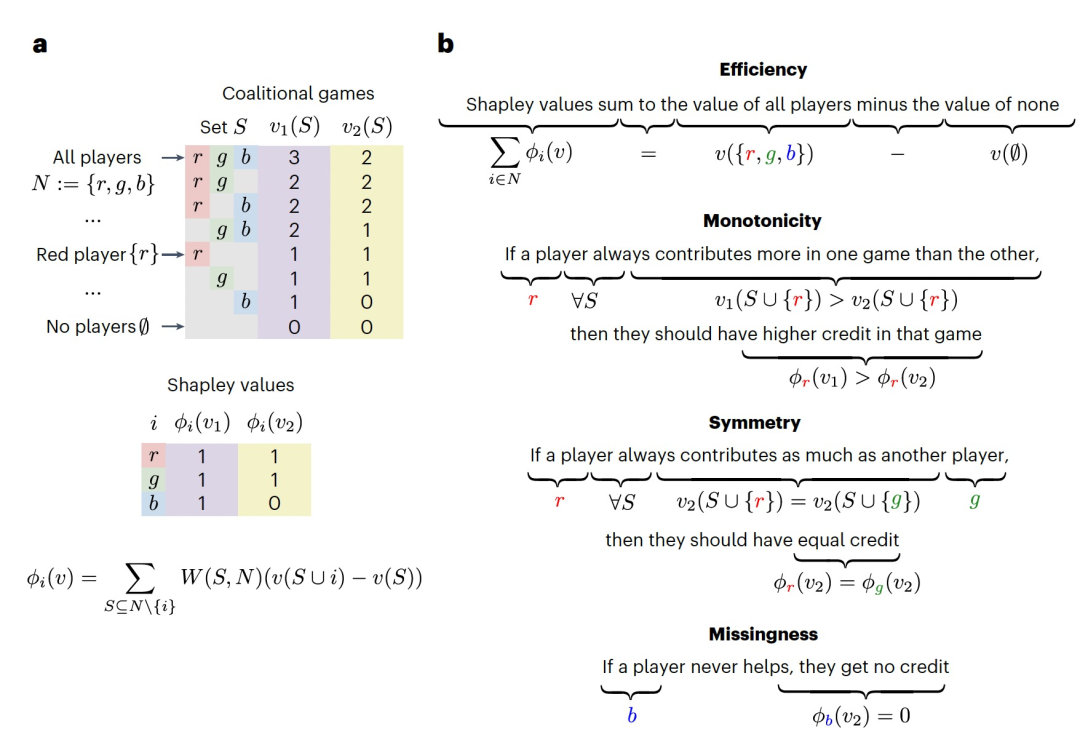
图 2
Shapley值是博弈论中的一种工具,旨在在合作博弈中分配贡献给各个参与者。参与者由集合D = {1, ..., d}表示,而"合作博弈"是一个将玩家子集映射到标量值的函数。一个博弈由一个集合函数v(S):?(D) → ?表示,其中?(D)是D的幂集,表示所有可能的玩家子集。图2a展示了两个参与人员的合作博弈。为了使这些概念更具体化,考虑一个公司,该公司的利润v(S)由选择工作的员工集合S ? D决定。一个自然的问题是如何对员工根据他们对总利润的贡献进行报酬。假设我们知道所有员工子集的利润,Shapley值通过计算当i与组S一起工作与i不与组S一起工作时利润增加的加权平均值来给个体i分配贡献(这个数量被称为i的'边际贡献')。通过对i不属于的所有可能的子集S穷举,即S ? D \ {i},对这种差异进行平均,我们得到Shapley值的定义:
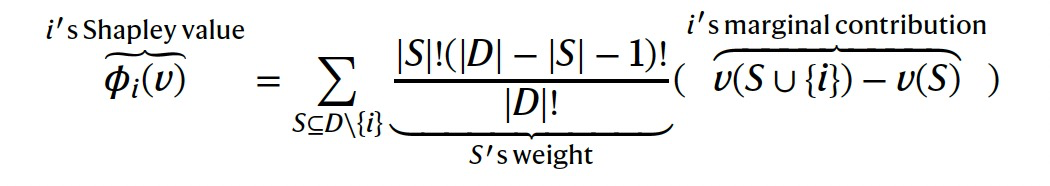
Shapley值为在合作博弈中分配贡献提供了一种引人注目的方法,并且已被广泛应用于计算生物学和金融等领域。图2b展示了Shapley值满足的几个关键属性,但还有其他非显示的属性将其与其他贡献分配方案区分开来。
Shapley values具体怎么算
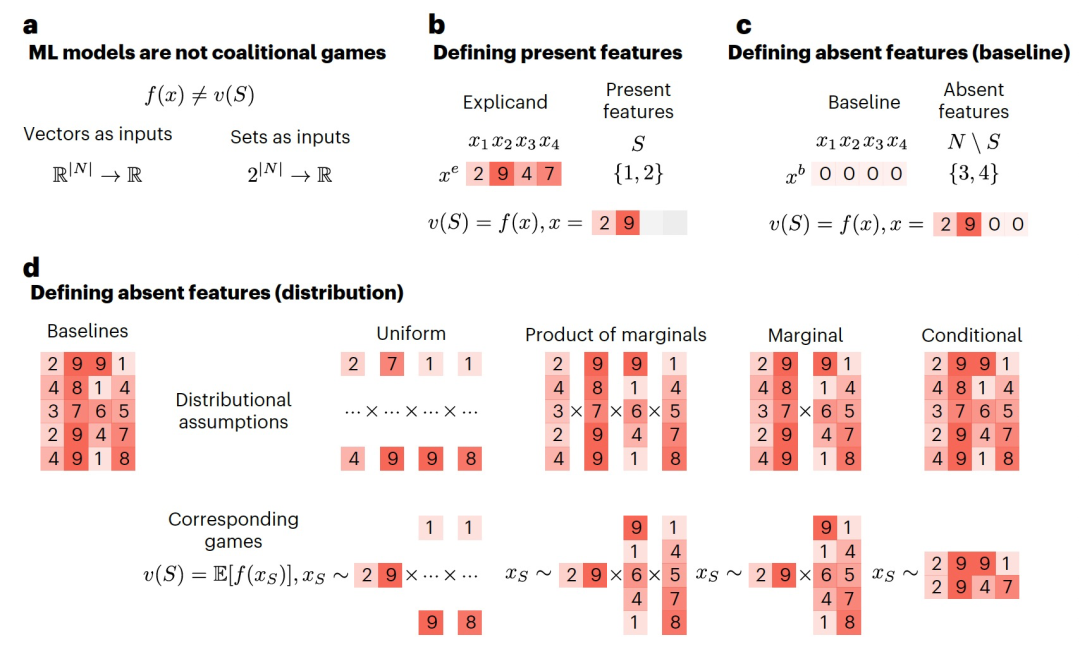
图 3
Shapley值在合作博弈中分配贡献的解决方案很有吸引力,但我们的目标是在机器学习模型f(x) ∈ ?中分配特征x_1,…,x_d的贡献。如图3a所示,机器学习模型默认情况下不是合作博弈,因此要使用Shapley值,我们首先必须基于模型f(x)定义一个合作博弈v(S)。合作博弈可以选择代表各种模型行为,包括模型对单个样本或整个数据集的损失。作者专注于最常见的选择,即解释单个样本x^e的预测结果f(x^e)。在解释机器学习模型时,将每个特征视为合作博弈中的一个参与者是很自然的。然而,我们必须定义每个特征的存在或缺失的含义。考虑到我们关注的是单个解释对象x^e的第i个特征,特征i的存在意味着模型使用观察到的值x^e进行评估(图3b)。至于不存在的特征,接下来将讨论如何移除它们以正确评估现有特征的影响力。一种简单的方法是使用基准样本x^b来替换特征的值,以移除该特征。也就是说,如果特征i不存在,我们可以将其值设置为基准样本中对应特征的值。因此,这种情况下合作博弈的定义如图3c。在文章的剩余部分中,将用简化的表示方式为:
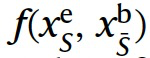
。
这个合作博弈的Shapley值被称为“基准Shapley值”。这种方法简单易实现,但基准的选择并不直观,可能有一定的任意性。许多不同的基准值被考虑过,包括全零基准、特征均值基准、来自均匀分布的基准等。不幸的是,基准的选择会极大地影响特征归因的结果,而选择基准的标准可能不明确。可能的解决方法之一是寻找一个中立或无信息的基准,但对于给定的数据集,这样的基准值可能并不存在。因此,通常会使用基准值的分布,而不是依赖于单个值。
与将移除的特征设置为固定的基准值不同,另一个选择是对模型的预测结果进行随机采样替代值的平均。一种方法是从移除特征的条件分布中进行采样。也就是说,给定一个样本x^e和其特征子集S ? D,我们可以考虑存在的特征集合,并对不存在的特征进行采样替代值(图3d, conditional部分)。在这种情况下,合作博弈通常被定义为在该分布上预测结果
的期望值,或者表示为:
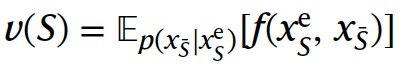
。
对于这种合作博弈,Shapley值有几种不同的名称:观测Shapley值、条件期望Shapley值和条件Shapley值,作者将使用条件Shapley值来称呼它们。这种方法可能面临两个潜在的挑战,一是估计条件期望的困难,二是由于相关特征之间的影响,结果的解释可能会分散贡献。另一种方法是在采样替代值时使用边际分布。也就是说,我们可以忽略观察到的特征的值,并根据(图3d, marginal部分)方式进行采样。与之前的情况类似,合作博弈被定义为在这个分布上预测结果的期望值。这种方法等价于对来自数据分布p(x)的基准Shapley值进行平均。它还可以解释为模型的因果解释,其中模型的输入与现实世界中的特征是不同的;这相当于假设一个平坦的因果图。在实践中,条件和边际方法是最常见的特征移除方法。基于随机采样的另外两种方法是:(1)均匀方法,其中不存在的特征是从覆盖特征范围的均匀分布中抽取的(图3d, uniform部分);(2)边际乘积方法,其中不存在的特征是从各自的边际分布中抽取的(假设所有不存在特征之间独立)(图3d, product of marginals部分)。这些方法都假设特征之间独立,边际Shapley值假设观察到的特征和未观察到的特征之间独立,因此更常用。
鉴于有多种形式化合作博弈的方式,或者处理不存在特征的方法,一个自然的问题是“哪种Shapley值解释更好?”这个问题在Shapley值的文献中经常被讨论,一些论文支持边际Shapley值,其他论文提倡条件Shapley值,还有一些论文主张使用因果解释。在讨论它们的差异之前,这些方法的一个共同点是,每个版本总是满足其对应合作博弈的Shapley值公理,尽管对公理的解释可能不同;这一点已经在早期的研究中讨论过,但重要的是要避免混淆相对于合作博弈和模型而定义的公理。条件Shapley值倾向于在相关特征之间分散贡献度,这可以揭示隐藏的依赖关系,而边际Shapley值则更接近模型的函数形式。这种差异源于分布假设,因为在某个特征上进行条件处理会隐含所有相关特征的信息,从而导致一组特征共享贡献度。例如,如果在缺失身体质量指数(BMI)时引入体重特征,则条件Shapley值只会考虑给定已知体重值的BMI值(即“在流形上”的值);因此,如果模型依赖于BMI而不依赖体重,我们仍然会观察到引入体重会影响模型输出的条件期望。相比之下,虽然边际Shapley值以较不真实的方式扰动数据,但它们能够区分相关特征,并确定模型是否在功能上依赖于BMI或体重,这对于模型调试很有用。这些方法之间的差异意味着在用户旨在了解模型的功能形式时,边际Shapley值可能更合适;而在用户旨在理解数据或世界中的潜在机制时,条件Shapley值可能更适合。
评估Shapley值算法的策略

表 1
在本节中,作者描述了算法方法来解决生成Shapley值解释的两个主要挑战:移除特征以估计合作博弈,并在面临指数级复杂性时可靠地计算Shapley值。表1提供了具体实现中使用的方法的摘要。作者之前介绍了三种主要的特征移除方法,并讨论了它们之间的权衡。在本节中,作者重新强调它们的定义,并讨论如何计算相应的合作博弈,这是计算基准Shapley值、边际Shapley值和条件Shapley值所必需的。
基准Shapley值:要计算这个合作博弈的值,我们可以简单地创建一个混合样本并返回模型的预测结果。与其他方法不同,这个合作博弈是可以精确计算的。唯一的参数是基准的选择,这个选择可能是一个相对随意的决定。
边际Shapley值:计算边际期望的一种自然方法是使用训练或测试数据获得经验估计值。在机器学习中,通常假设数据是从数据分布p(x)中独立抽取的,因此我们可以将一组观测样本E指定为经验分布,并使用它们的值来替代缺失特征。很明显,经验边际期望是基于许多不同基准的基准Shapley值的合作博弈的平均值。出于这个原因,一些算法通过首先估计具有不同基准的基准Shapley值,然后对结果进行平均来估计边际Shapley值。需要注意的是,基于经验估计的边际Shapley值在基准是从基准分布中独立同分布(例如,从数据集中随机选择的子集)的情况下是无偏的。因此,这种经验估计被认为是一种可靠的近似真实边际期望的方法。
条件Shapley值:计算条件Shapley值更加困难,因为所需的条件分布无法直接从训练数据中获得。如图3d(条件)所示,我们可以通过对匹配解释变量的现有特征的样本进行模型预测的平均来经验估计条件期望,这在数据集大小趋于无穷时可靠地估计条件期望。然而,在实践中,这种经验估计方法效果不佳:在存在连续特征或大量特征的情况下,匹配的行数可能过低,导致估计结果不准确且不可靠。例如,如果我们以5.879英尺的身高作为条件,我们的数据中可能只有非常少的人具有这个确切的身高,因此经验条件期望将基于非常少的样本预测值进行平均,或者可能只基于解释变量本身的单个预测值。一种自然的解决方案是基于相似的特征值来近似条件期望,而不是精确匹配。例如,我们可以使用身高在5.879±0.025英尺范围内的人,而不是仅仅筛选身高为5.879英尺的人。作者将这类方法称为经验条件分布逼近,因为它们实质上是通过某种相似性概念将经验分布进行粗略表示。这些方法需要在观察特征中定义一个足够接近的匹配条件,这并不明显,而且可能是一个解释方法中不希望出现的先决条件。此外,对许多特征进行条件处理仍然可能导致不准确的估计,因为在高维空间中很难找到相似的样本。目前存在着各种各样的方法来模拟条件分布或直接估计条件期望。这些方法通常会存在偏差或不精确,因为我们所需的博弈是基于真实的潜在条件期望。此外,由于条件期望通常是未知的(除了在非常简单的情况下),因此很难量化近似质量。目前这些方法中,经验方法产生的估计结果较差,参数方法需要强大的假设。训练期间的缺失数据并非是模型无关的,而为每个特征集拟合单独的模型并不能完全解释原始模型。相反,作者认为基于生成模型或替代模型的方法更具有前景。这些方法更加灵活,但都需要拟合额外的深度模型。未来的工作可能包括确定替代模型和生成模型的稳健体系结构和超参数,分析非最优替代模型和生成模型对条件Shapley值估计结果的影响,并评估对具有已知条件分布的数据的条件Shapley值估计结果的近似质量。
在一般情况下,计算Shapley值是一个NP难问题。直观地说,基于穷举计算在特征数量上具有指数复杂度,因为它需要评估包含所有特征子集的模型。鉴于Shapley值的悠久历史,自然而然地有大量关于它们计算的研究。在博弈论文献中,出现了两种估计策略:(1)基于近似的策略,可以为任何博弈提供无偏的Shapley值估计;(2)基于假设的策略,在特定类型的博弈中可以在多项式时间内产生精确结果。
这两种策略在Shapley值解释的文献中也占据主导地位。然而,由于一些方法结合了假设和近似,作者将这些方法分为模型无关和模型特定两类。模型无关方法对模型类别没有任何假设,通常是基于随机抽样的估计器。相反,模型特定方法依赖于对模型结构的假设,以提高计算速度,但有时会以准确性为代价。
模型无关方法:有几种模型无关的方法可以使用随机抽样估计Shapley值解释。这些方法通常是无偏的,但是非确定性的,其期望结果是正确的。有趣的是,每种模型无关的方法都可以与不同的数学形式的Shapley值联系起来,而这些形式有很多种。模型无关的策略具有吸引力,因为它们适用于任何博弈,从而适用于任何模型和特征移除方法。缺点是它们本质上是随机的,可能具有不合理的方差。为此,已经开发了一些技术来预测和检测收敛性。然而,模型无关的解释仍然可能具有高计算成本。
基于模型的方法:针对特定的模型类型,已经开发了专门的算法,适用于几种流行的模型类型:线性模型、树模型和深度模型。这些方法相对于模型无关的方法来说,灵活性较低,因为它们假设了特定的模型类型和通常是特定的特征移除方法,但它们的计算速度通常要快得多。对于深度模型,有几种特定的方法:DeepLIFT、DeepSHAP、Deep Approximate Shapley Propagation(DASP)和Shapley Explanation Networks(ShapNets)。DeepLIFT通过一组规则在深度网络中传播归因,可以被视为对单个基线的Shapley值的逐层近似。由于这些近似,DeepLIFT会产生对基线Shapley值的偏差估计。DeepSHAP将DeepLIFT扩展为产生对边际Shapley值的偏差估计。DASP利用不确定性传播和对Shapley值的表征,对每个博弈大小的预期边际贡献进行平均,以估计基线Shapley值。DASP是确定性的,需要O(d^2)次模型评估,其中d是特征的数量,但它也可以以较少的评估次数以随机方式使用。ShapNets是特定的深度架构,Shapley值更容易估计:它们需要具有特定连接约束的层,以实现对基线Shapley值的快速估计。就其假设而言,ShapNets是最具限制性的,因为它们无法解释其他深度模型,而DASP也是具有限制性的,因为它要求在深度模型的每一层中进行一阶和二阶中心矩匹配,这只适用于某些层。DeepLIFT和DeepSHAP更灵活,因为它们的规则通常适用于许多层,但由于DeepLIFT的灵活性,与DASP或ShapNets相比其对基线Shapley值的估计偏差较高。总的来说,这些针对特定模型的方法通常比模型无关的方法快得多,但其高偏差可能会根据特定的模型和数据集而产生问题。
结论
在综述中,作者描述了许多生成Shapley值的算法。作者深入探讨了它们复杂性的两个主要因素:特征移除方法和可行的估计策略。就不同的Shapley值解释而言,估计基线Shapley值的算法通常是无偏的,但选择一个单一的基线来代表缺失信息往往是任意的。同样,估计边际Shapley值的算法通常也是无偏的。相反,估计条件Shapley值的算法更容易出错,因为条件期望基本上更难估计;因此,除了线性模型的特殊情况外,目前很难近似计算条件Shapley值。然而,根据预期的使用情况,使用一个不完美的近似值可能比切换到基线或边际Shapley值更可取。
参考资料
Chen, H., Covert, I.C., Lundberg, S.M. et al. Algorithms to estimate Shapley value feature attributions. Nat Mach Intell (2023).
https://doi.org/10.1038/s42256-023-00657-x