Bittorrent 协议浅析(一)元数据文件
原创
0. 序
时代在变,很多事物慢慢消失在了数据的海洋中,但不会忘记的,时那个以相互交流、分享信息为目的存在的互联网环境,在 BS、 CS 模式盛行的今天,偶尔也要想起 Peer to Peer 存在的意义和必要性,在其存在感越来越低的今天,暂且不论对错,不问优劣,只从技术角度对其进行回味。
本文通过分析解读 Bittorrent 协议来让更好的理解它,并为进一步尝试提供理论基础,本文暂不讨论 DHT,PEX等未经 BDFL 确认成为正式版本的内容,这部分内容可能会在其他文章中进行讨论。
1. 概述
BitTorrent 是一种用于分发文件的协议,和 FTP,HTTP相比其特点为当同一文件的多个下载同时工作时,下载器会互相上传,故可以在文件源负载增加不多的情况下,支持大量的下载请求。
2. 组成
在官方文档中是这么描述一个 BitTorrent 文件分发的组成的
An ordinary web server A static 'metainfo' file A BitTorrent tracker An 'original' downloader The end user web browsers The end user downloaders
网站服务器,metainfo 文件(种子文件),Tracker,“原始”下载者(最初的做种者),用户浏览器和用户下载器。
网站服务器和用户浏览器是用来分发、传输 mateinfo 的,这个过程也可以通过其他方式进行(比如发到群聊里?)。
Tracker 用于交换用户信息。
下载和分发通常用的是同一个程序,可以都看作是下载器(downloader)。
3. 编码
对 字符串,整数,列表,字典 在规范中有编码的定义,整数,列表,字典需要进行类型开始和结束标记,具体的:
字符串
字符串由一个表示长度的十进制数字,紧接着一个冒号和字符串本身组成。
例:
4:spam对应于字符串 'spam',其中 "4" 表示字符串的长度;5:cloud对应 'cloud';7:tencent对应 'cloud';3:com对应 'com';
整数
整数由一个小写字母 "i" 开头,小写字母 "e" 结尾拼接而成,数字使用十进制。
例:
i3e对应数 3;i-3e对应于整数 -3;i0e它对应于数字 0;
注:除了 i0e 对应的数字 0 外,其他数字不能以 0 开头,i-0e 也是不允许的。
助记:int 数字 end
列表
列表由一个小写字母 "l" 开始,以字母 "e" 结束。
例:
l4:spam4:eggse对应 'spam', 'eggs'
助记:list 项目:项目:... end
字典
字典和列表很像,由一个小写字母 "d" 开始,最后以字母 "e" 结束。
例:
d3:cow3:moo4:spam4:eggse对应字典 {'cow': 'moo', 'spam': 'eggs'}
键的类型必须为字符串,并根据字符串规则进行排序
助记:dictionary 键:值:键:值:... end
元数据文件(种子文件)
在 BitTorrent 中,元数据(Mateinfo)文件就是我们熟悉的种子文件(.torrent 文件),为了阅读和理解的方便,后续所提种子、种子文件都是指元数据文件。
种子结构
首先,整个种子文件是一个字典,其结构大致为:
{
"announce": "TackerAddressString",
"info": {
"name": "NameString",
"piece length": 262144,
"pieces": "hashString...",
"length": 3276800
}
}或这样
{
"announce": "TackerAddressString",
"info": {
"name": "NameString",
"piece length": 262144,
"pieces": "hashString...",
"files": [
{
"length": 4096,
"path": ["Folder", "FileName1"]
},
{
"length": 8192,
"path": ["Folder", "FileName2"]
},
{
"length": 16384,
"path": ["Folder", "Subfolder", "FileName3"]
}
]
}
}详细的:
- 宣告地址(announce):Tracker服务器的URL,字符串
- 信息(info):字典
- 名称(name):建议的保存文件(或目录)的名称的UTF-8编码字符串,字符串
- 分片长度(piece length):每个文件分片的字节数,整数
- 分片哈希(pieces):文件分片的 SHA-1 哈希值的拼接,每一个分片都有长度为 20 的 SHA-1 的哈希,故该部分为长度为 20 倍数字符串
- 长度(length) 或 文件列表(files):这部分内容用来区分是单文件还是多文件的情况,所以长度和文件列表必须且只能存在一个,字符串或字典:
- 长度(length)文件的字节数,整数
- 文件列表(files)顾名思义,列表,列表包含逗哥字典,字典格式:
- 长度(length)文件的字节数,整数
- 路径(path)标明文件路径的字符串列表,对应子目录,文件名的 UTF-8编码的列表
例子
解码
根据规范,可以完成简单的解析程序,这里使用 Python 作例子,其他语言略,实现如下:
def decode_bencode(data):
# 解码字符串
def decode_string(data):
colon_idx = data.index(b':')
length_str = data[:colon_idx].decode('utf-8')
length = int(length_str)
start_idx = colon_idx + 1
end_idx = start_idx + length
string = data[start_idx:end_idx]
return string, data[end_idx:]
# 解码整数
def decode_integer(data):
end_idx = data.index(b'e')
integer_str = data[1:end_idx].decode('utf-8')
return int(integer_str), data[end_idx + 1:]
# 解码列表
def decode_list(data):
decoded_list = []
data = data[1:]
while not data.startswith(b'e'):
item, data = decode_bencode(data)
decoded_list.append(item)
return decoded_list, data[1:]
# 解码字典
def decode_dict(data):
decoded_dict = {}
data = data[1:]
while not data.startswith(b'e'):
key, data = decode_string(data)
value, data = decode_bencode(data)
decoded_dict[key] = value
return decoded_dict, data[1:]
# 根据数据类型调用对应的解码函数
if data.startswith(b'd'):
return decode_dict(data)
elif data.startswith(b'l'):
return decode_list(data)
elif data.startswith(b'i'):
return decode_integer(data)
else:
return decode_string(data)实例
首先来看一个通过qBittorrent制种的种子和解码后的信息
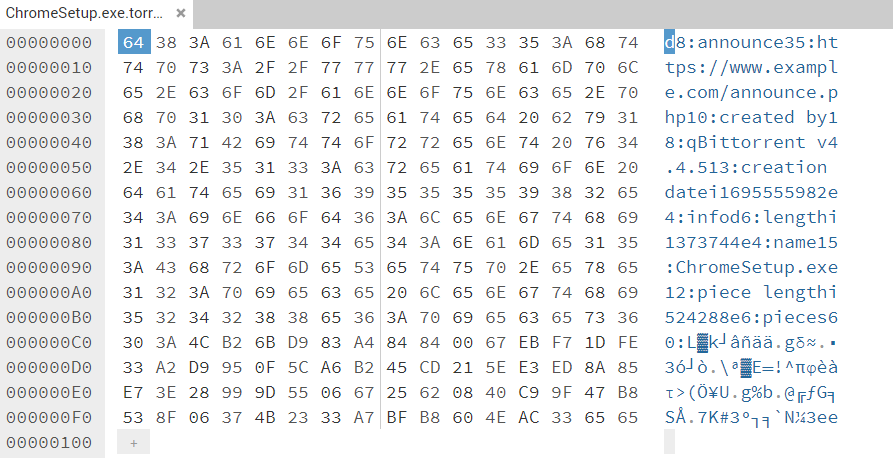
{
"announce": "https: //www.example.com/announce.php",
"createdby": "qBittorrentv4.4.5",
"creationdate": 1695555982,
"info": {
"length": 1373744,
"name": "ChromeSetup.exe",
"piece length": 524288,
"pieces": b"L\xb2k\xd9\x83\xa4\x84\x84\x00g\xeb\xf7\x1d\xfe3\xa2\xd9\x95\x0f\\\xa6\xb2E\xcd!^\xe3\xed\x8a\x85\xe7>(\x99\x9dU\x06g%b\x08@\xc9\x9fG\xb8S\x8f\x067K#3\xa7\xbf\xb8`N\xac3"
}
}根据前述内容,可知道,这组元数据如下:
- Trakcer地址:https: //www.example.com/announce.php
- 分片长度:524288
- 文件大小:1373744
- 建议名称:ChromeSetup.exe
- 分片哈希值:(略)
哈希值校验
使用如下程序计算文件哈希值
import hashlib
def calculate_sha1(data):
h = hashlib.sha1()
h.update(data)
return h.hexdigest()
def slice_and_hash_file(f, s):
h = []
with open(f, 'rb') as file:
while True:
data = file.read(s)
if not data:
break
h.append(calculate_sha1(data))
return h
file_path = 'ChromeSetup.exe'
slice_size = 524288 # 例如,这里将文件切成每个切片1024字节
slice_hashes = slice_and_hash_file(file_path, slice_size)
for i, sha1_hash in enumerate(slice_hashes):
print(sha1_hash)使用程序对目标文件哈希值进行计算,得到计算结果:
4cb26bd983a484840067ebf71dfe33a2d9950f5c
a6b245cd215ee3ed8a85e73e28999d5506672562
0840c99f47b8538f06374b2333a7bfb8604eac33与元数据一致
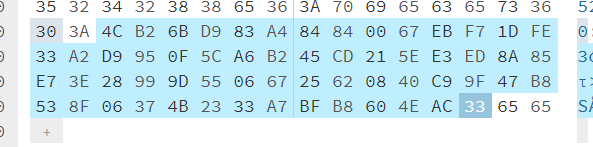
此外,还注意到,qBittorrent在制种的过程中,加入了 createdby 和 creationdate 的键值对,这些内容主要由其他 BEP 提出并被对应的客户端支持,对于当前讨论的版本和内容,这些内容不是必须的,这些内容的存在不会带来较大危害。
手动制作一个元数据文件
手动构造一个 BitTorrent 种子文件,在此以单个文件的元数据为例,还是使用 Chrome 安装程序 ChromeSetup.exe 作为例子。
假设 tracker 地址为 https: //www.example.com/announce,设置切片大小为 2097152(2M),确认文件大小为 1373744 字节,计算文件 SHA1 为3b4964c5f6aead8d2aee4818976c041cb485b81b ,根据内容完成数据结构:
{
"announce": "https: //www.example.com/announce",
"info": {
"length": 1373744,
"name": "ChromeSetup.exe",
"piece length": 2097152,
"pieces": b';Id\xc5\xf6\xae\xad\x8d*\xeeH\x18\x97l\x04\x1c\xb4\x85\xb8\x1b'
}
}使用如下程序进行编码:
def encode_bencode(data):
if isinstance(data, dict):
# 对字典进行编码
encoded_data = b'd'
for key in sorted(data.keys()):
encoded_data += encode_bencode(key) + encode_bencode(data[key])
encoded_data += b'e'
elif isinstance(data, list):
# 对列表进行编码
encoded_data = b'l'
for item in data:
encoded_data += encode_bencode(item)
encoded_data += b'e'
elif isinstance(data, int):
# 对整数进行编码
encoded_data = f"i{data}e".encode('utf-8')
elif isinstance(data, str):
# 对字符串进行编码
encoded_data = f"{len(data)}:{data}".encode('utf-8')
else:
raise ValueError("Unsupported data type")
return encoded_data将编码结果保存至文件,编码结果如下:
b'd8:announce32:https://www.example.com/announce4:infod6:lengthi1373744e4:name15:ChromeSetup.exe12:piece lengthi2097152e6:pieces20:;Id\xc5\xf6\xae\xad\x8d*\xeeH\x18\x97l\x04\x1c\xb4\x85\xb8\x1bee'
使用 qBittorrent 打开并进行校验,校验通过。
元数据文件-完
第一部分 元数据文件 暂时研究到这里,Tracker 通讯和节点通讯的内容在后续文章中补充,链接会放在这里:
最后,征文活动广告:
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。