网卡卸载(Nic Offload)-硬件卸载-DPU-智能网卡
原创网卡卸载(Nic Offload)-硬件卸载-DPU-智能网卡
原创
简介
为了降低CPU利用率, 将更多的CPU释放给业务使用, 大多数现代操作系统都支持某种形式的网络卸载,其中一些网络处理发生在网卡 NIC 而不是 CPU 上, 它可以释放系统其余部分的资源, 这样操作系统就能处理更多连接, 提高整体性能.
默认以太网最大传输单元 (MTU) 为 1500 字节,这是通常可以传输的最大帧大小。这可能会导致系统资源未得到充分利用,例如,如果有 3200 字节的数据需要传输,则意味着会生成三个较小的数据包。有几种称为卸载的选项,它们允许相关协议栈传输大于正常 MTU 的数据包。可以创建最大允许 64KiB 的数据包,并提供发送 (Tx) 和接收 (Rx) 选项。当发送或接收大量数据时,这可能意味着每发送或接收 64KiB 的数据处理一个大数据包,而不是处理多个较小的数据包。这意味着生成的中断请求更少,用于拆分或合并流量的处理开销更少,传输机会更多,从而导致吞吐量的整体增加。
卸载类型
- TCP 分段卸载 (TSO) - TCP Segmentation Offload 使用 TCP 协议发送大数据包。使用NIC来处理分段,然后将TCP、IP和数据链路层协议头添加到每个分段。
- UDP 碎片卸载 (UFO) - UDP Fragmentation Offload 使用UDP协议发送大数据包。使用 NIC 将大型 UDP 数据报的 IP 分段处理为 MTU 大小的数据包。
- 通用分段卸载 (GSO) - Generic Segmentation Offload 使用 TCP 或 UDP 协议发送大数据包。如果 NIC 无法处理分段/碎片,GSO 会绕过 NIC 硬件执行相同的操作。这是通过尽可能晚地延迟分段来实现的,例如,当数据包由设备驱动程序处理时。
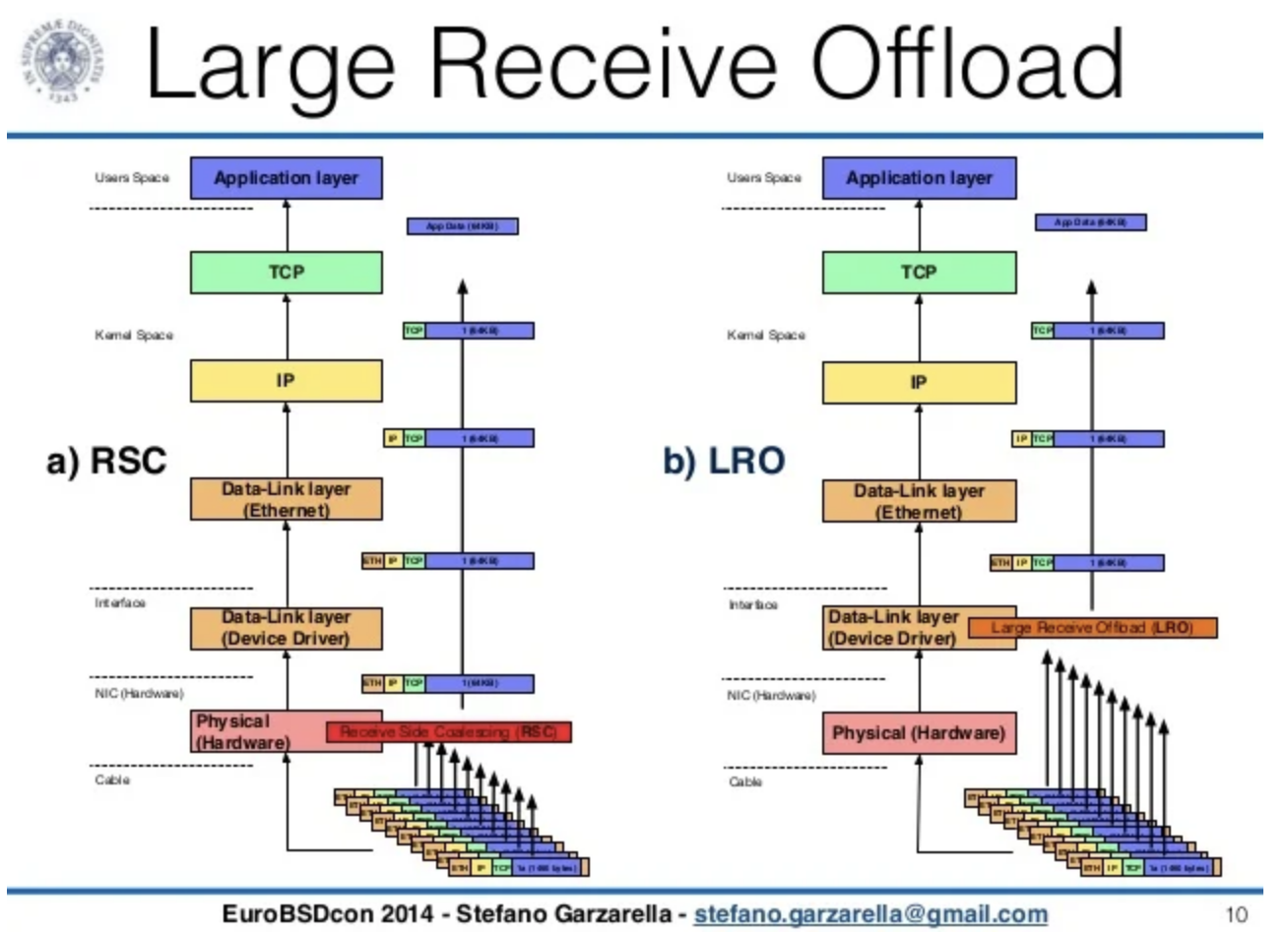
- 大量接收卸载 (LRO) - Large Receive Offload
使用 TCP 协议。所有传入数据包在收到时都会重新分段,从而减少系统必须处理的分段数量。它们可以在驱动程序中或使用 NIC 进行合并。LRO 的一个问题是它倾向于重新分段所有传入数据包,通常会忽略标头和其他可能导致错误的信息的差异。当启用 IP 转发时,通常无法使用 LRO。LRO 与 IP 转发相结合可能会导致校验和错误。
/proc/sys/net/ipv4/ip_forward如果设置为 1, 则启用转发。 - 通用接收卸载 (GRO) - Generic Receive Offload 使用 TCP 或 UDP 协议。在对数据包进行重新分段时,GRO 比 LRO 更加严格。例如,它检查每个数据包的 MAC 标头,这些标头必须匹配,只有有限数量的 TCP 或 IP 标头可以不同,并且 TCP 时间戳必须匹配。重新分段可以由 NIC 或 GSO 代码处理。
使用 NIC 卸载
卸载应该用在传输或接收大量数据的高速系统上,并且优先考虑吞吐量而不是延迟。由于使用卸载极大地增加了驱动程序队列的容量,因此延迟可能成为一个问题。一个例子是系统使用大数据包传输大量数据,但也运行大量交互式应用程序。由于交互式应用程序按时间间隔发送小数据包,因此存在非常现实的风险,即这些数据包可能会“陷入”缓冲区中,而同时处理它们前面的较大数据包,从而导致不可接受的延迟。
要检查当前卸载设置,请使用该ethtool命令。某些设备设置可能会列为fixed,这意味着它们无法更改。
命令语法:ethtool -k 以太网设备名称, 如: 检查当前网卡卸载设置:
ethtool -k em1
Features for em1:
rx-checksumming: on
tx-checksumming: on
tx-checksum-ipv4: off [fixed]
tx-checksum-ip-generic: on
tx-checksum-ipv6: off [fixed]
tx-checksum-fcoe-crc: off [fixed]
tx-checksum-sctp: off [fixed]
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: off [fixed]
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: off [fixed]
tx-tcp6-segmentation: on
udp-fragmentation-offload: off [fixed]
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
rx-vlan-offload: on
tx-vlan-offload: on
ntuple-filters: off [fixed]
receive-hashing: on
highdma: on [fixed]
rx-vlan-filter: off [fixed]
vlan-challenged: off [fixed]
tx-lockless: off [fixed]
netns-local: off [fixed]
tx-gso-robust: off [fixed]
tx-fcoe-segmentation: off [fixed]
tx-gre-segmentation: off [fixed]
tx-ipip-segmentation: off [fixed]
tx-sit-segmentation: off [fixed]
tx-udp_tnl-segmentation: off [fixed]
tx-mpls-segmentation: off [fixed]
fcoe-mtu: off [fixed]
tx-nocache-copy: off
loopback: off [fixed]
rx-fcs: off
rx-all: off
tx-vlan-stag-hw-insert: off [fixed]
rx-vlan-stag-hw-parse: off [fixed]
rx-vlan-stag-filter: off [fixed]
l2-fwd-offload: off [fixed]
busy-poll: off [fixed]
?
查看checksum卸载配置:
ethtool --show-offload ethX
?
禁用:
ethtool --offload ethX rx off tx off
或有些驱动加载的时候可以指定关闭参数, 如3Com 网卡:
rmmod 3c59x ; modprobe 3c59x hw_checksums=0谁能解释一下 TCP 中的 TSO/LRO 硬件功能是什么以及这些功能是否也负责确认机制
您首先必须了解的是,在网络性能提升技术方面,TSO 只是相当大的冰山的一角, 除此之外还有其他方式提升网络性能
让我们考虑一下基本的网络接口。您的操作系统使用 PIO(编程输入/输出,即一次一个字(通常为 32 位))将整个数据包发送到 NIC(网络接口卡),因为它应该仅出现在线路上,不包括帧检查序列。
以下是数据传输速度的提升的方式:
因此,第一个速度提升是使用 DMA(直接内存访问),这允许处理器在硬件复制数据包的同时做其他事情。但操作系统仍然必须将数据包数据复制到内存中并生成标头和校验和。
第二个提升是让硬件为数据包的数据部分生成校验和,操作系统仍会将数据复制到其内存空间并将标头放在其前面。当操作系统生成标头时,它也可能始终生成标头的校验和。这看起来很复杂,但机制其实很简单。硬件被告知在到达位置 XX 时开始校验和,并将校验和放置在数据包缓冲区中的位置 yy 处。
第三个提升是使用分散/聚集(SGL)。这基本上意味着操作系统不会将数据复制到内存中,而是将标头和数据部分的位置传递给驱动程序,并允许驱动程序收集数据以发送它。这需要硬件校验和,如果操作系统需要对数据包进行校验和,那么它需要首先将其复制到内存中。
第四个(也是 Linux 中原生支持的最高级别)是 TSO。通过 TSO,操作系统为硬件提供标头模板,然后为硬件提供大块数据(不超过 64K)以供其分割和校验和,这意味着操作系统需要生成更少的标头,并且设置 DMA 时的任何开销也将大幅减少。当数据包在线路上传输时,它们符合数据包的正常规则,并且与它们所经过的任何交换机或路由器兼容。
接受处理则是另一回事。硬件校验和在这里更多的是猜测而不是确定,因此应该发生的是硬件将数据包和校验和分别传递给操作系统,并允许操作系统决定数据包是否正常。
分散/聚集对于接收来说几乎是多余的。
LRO(大量接收卸载),硬件没有简单的方法知道这些数据包的含义,因此 LRO 目前只是一个软件构造,数据包被传递到操作系统,然后操作系统决定是否连接数据并将大块传递给应用程序或传递许多较小的块。
“TSO 导致网卡将较大的数据块划分为 TCP 段。”“LRO 将传入的网络数据包重新组装到更大的缓冲区中,并将生成的较大但较少的数据包传输到网络堆栈主机或虚拟机”
软件应始终生成 ACK 数据包。唯一的原因是您的 NIC 上是否有 TOE(TCP 卸载引擎)
具有支持 TSO 的硬件的主机将 TCP 数据发送到 NIC,而无需在软件中对数据进行分段。NIC 将执行 TCP 分段(读取 - 它将把大数据块分成段)。支持 LRO 的 NIC 接收数据包并重新组装它们,然后再将数据传递到本地软件。
LRO/TSO 不直接对 ack 机制负责(尽管它确实依赖于 GBN(回退N步-go-back-n))。请注意,只要涉及的所有接口都支持该技术,LRO/TSO 就可以安全地在路由器和网桥上使用
- 大型接收卸载LRO的工作原理是,在将多个传入数据包传递到网络堆栈的更高层之前,将来自单个流的多个传入数据包聚合到更大的缓冲区中。它只是将它们聚合起来,而没有任何方式验证数据是否正确发送。在另一层有解决这个问题的算法。
- 如果我要告诉你 1509GB 的数据,你至少应该意识到这一点并准备一个 1509GB 的缓冲区。这就是 LRO/TSO 的简单规则
参考
wireshark_offload_checksum: https://wiki.wireshark.org/CaptureSetup/Offloading
TOE: https://en.wikipedia.org/wiki/TCP_offload_engine
谁能解释一下 TCP 中的 TSO/LRO 硬件功能是什么: https://stackoverflow.com/questions/7377209/can-anybody-explain-what-are-the-tso-lro-hardware-functions-in-tcp
晓兵(ssbandjl)
博客: /developer/user/5060293/articles | https://logread.cn | https://blog.csdn.net/ssbandjl | https://www.zhihu.com/people/ssbandjl/posts
DPU专栏
晓兵技术杂谈(系列)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。