【ES三周年】Elasticsearch原理深入浅出 — RESTful/ 倒排索引/ BKD树
原创【ES三周年】Elasticsearch原理深入浅出 — RESTful/ 倒排索引/ BKD树
原创
Elasticsearch 是一个基于 Lucene 构建的分布式、RESTful 风格的搜索和数据分析引擎。它通过有限状态转换器实现了用于全文检索的倒排索引、用于存储数值数据和地理位置数据的 BKD 树,以及用于分析的列存储。
一、RESTful
REST:Representational State Transfer,表现层状态转化。是一种软件架构风格,没有严格的定义,侧重于识别资源。
REST 其实不难理解。简单来说,即表现层的 HTTP 动词和状态码发生变化,以 GET、POST、PUT、DELETE 等来明确描述对资源的操作,并能通过状态码获得请求的状态。
RESTful API 是遵循 REST 架构风格的 Web API。它使用 URI 来标识资源,且每个 URI 代表一种资源。
一般API:
POST /user/list ??// 获取列表
POST /user/get ??// 获取
POST /user/add ??// 添加
POST /user/edit ??// 编辑
POST /user/delete ?// 删除RESTful API:
GET /user // 获取列表
GET /user/{id} ?// 获取
POST /user // 添加
PUT /user/{id} // 编辑
DELETE /user/{id} // 删除实例,



其实这就是一种潜移默化的 API 设计风格,看了下知乎和腾讯云社区 API 都有 RESTful 的倾向。但 RESTful API 不适用于复杂请求逻辑,需选择性使用。
二、Inverted Index/ Lucene Finite State Transducers
1. Inverted Index
倒排索引
常规的索引是文档到关键词的映射:
文档 ——> 关键词
但这样检索关键词的时候很费力,要遍历文档。于是有了倒排索引。
倒排索引是关键词到文档的映射:
关键词 ——> 文档
举例,
① —> what is elasticsearch used for
② —> what is elasticsearch index
③ —> inverted index in elasticsearch
Inverted Index
Term | TF | Posting List |
|---|---|---|
what | 2 | [1, 2] |
is | 2 | [1, 2] |
elasticsearch | 3 | [1, 2, 3] |
used | 1 | [1] |
for | 1 | [1] |
index | 2 | [2, 3] |
inverted | 1 | [3] |
in | 1 | [3] |
注:
TF,Term Frequency
分词,即将一个文本拆分成单个Term
Posting List,倒排列表。记录了出现过某个单词的文档列表,及单词在该文档中的位置信息
如果这时候搜索 elasticsearch inverted index,先找到对应 term
Term | TF | Posting List |
|---|---|---|
elasticsearch | 3 | [1, 2, 3] |
index | 2 | [2, 3] |
inverted | 1 | [3] |
将 Posting List 转化成 Bitset
[1, 2, 3] —> 111
[2, 3] —> 011
[3] —> 001
然后按位与得到001,即 ③ inverted index in elasticsearch 匹配度更高。实际应用中,还会考虑单词大小写、同义词、拼写错误等问题。而这些是普通关系数据库很难做到的。
2. Lucene Finite State Transducers
有限状态转换器,Elasticsearch 通过有限状态转换器实现倒排索引。
主要作用:对单词前缀及后缀重复利用,压缩存储空间
区别:TRIE 树只共享前缀
一般来说,生成 FST 需要保证单词字典序顺序。
例:
he/0
hey/1
on/2
one/3
org/4
tag/5
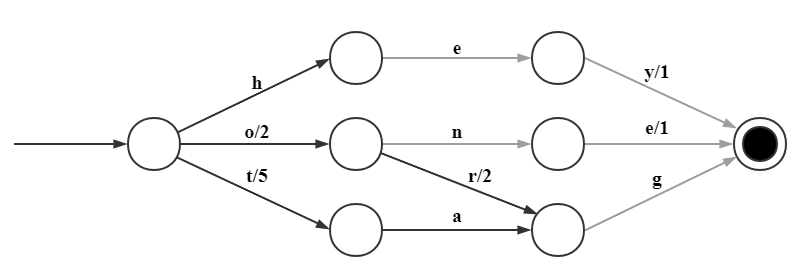
其中灰色边指向的节点为输出节点如 on。示例单词共享前缀 h、o,共享后缀 g。
推荐阅读:
Lucene FST_zouxiang_1993的博客-CSDN博客_fst lucene
关于Lucene的词典FST深入剖析 | 申艳超-博客 (shenyanchao.cn)
三、b-k-d tree
一种数据结构,用于存储数据并搜索处理等。
1. k-d tree
k-dimensional tree,k 维树,是一种 k 维空间分区数据结构。k-d 树是一个二叉树,其中每个节点都是一个 k 维点。
三维:
二维:
有多种方法构建 k-d 树,其中较为典型的是:层级按 k 维循环划分;子树由分割面中点的相对中位数进行拆分。
如:x —> y —> x —> y —> x ...
x —> y —> z —> x —> y —> z —> x ...
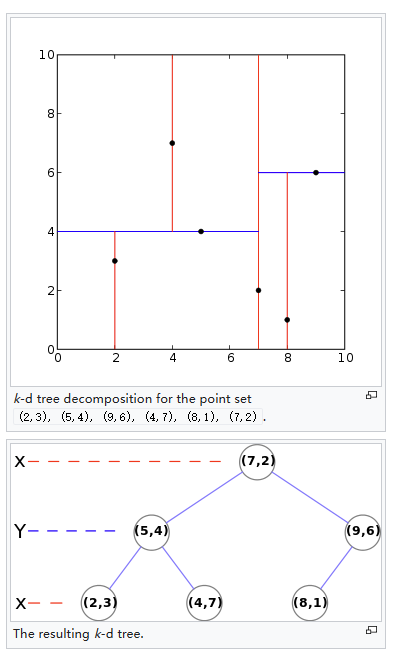
例:以上述二维 k-d 树举例
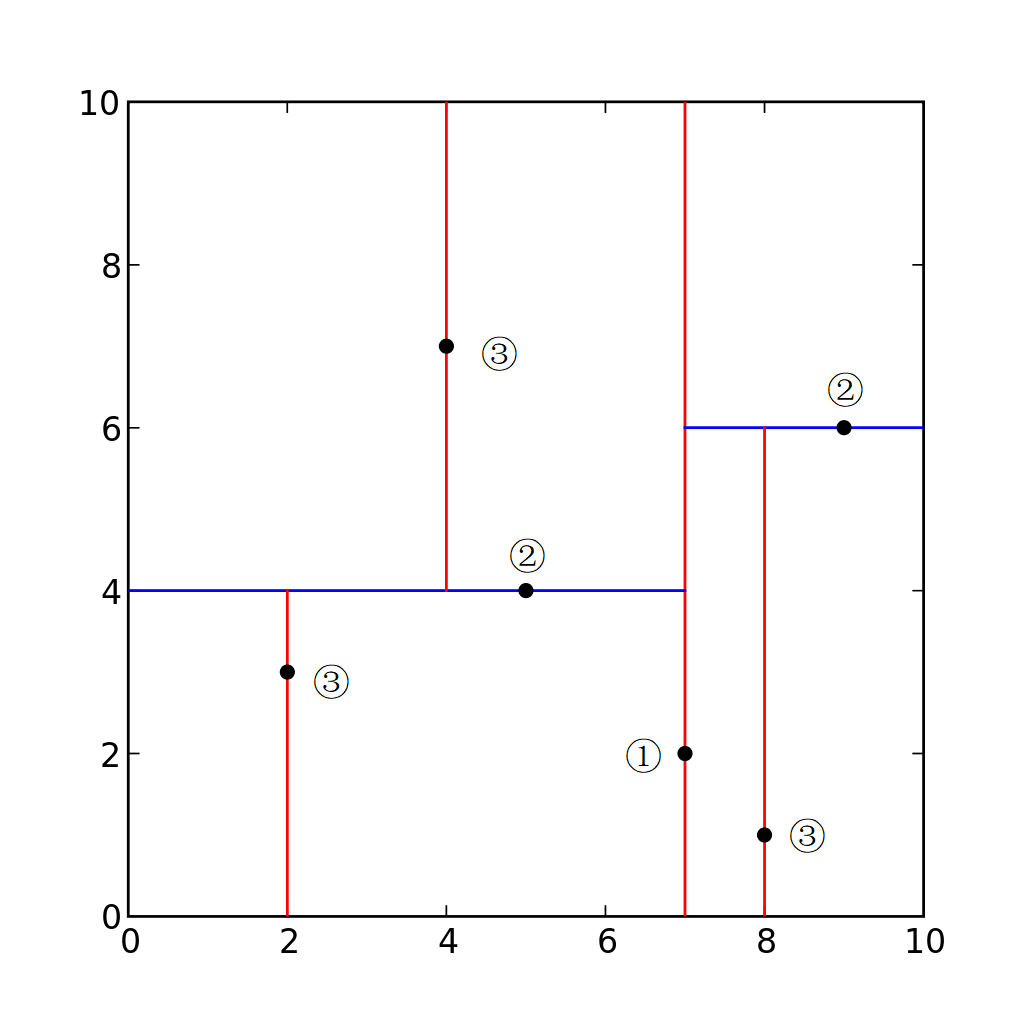
红线以 x 维度划分,蓝线以 y 维度划分。坐标:(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)
① 以 x 为维度,找到中间值作为根节点,即 (7,2)。此时平面以 x = 7 为分割线,分为两个平面

② 在 (7,2) 的两侧平面,以 y 为维度,找到相对中位数点,并放入左右子树
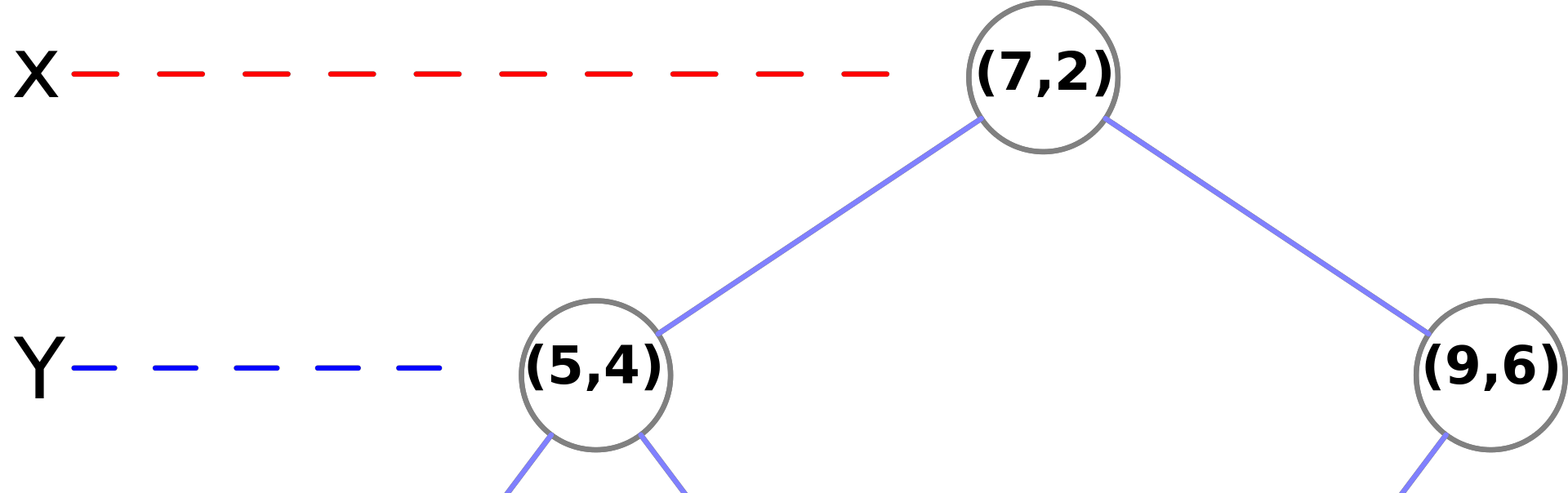
③ 再以 x 维度进行划分
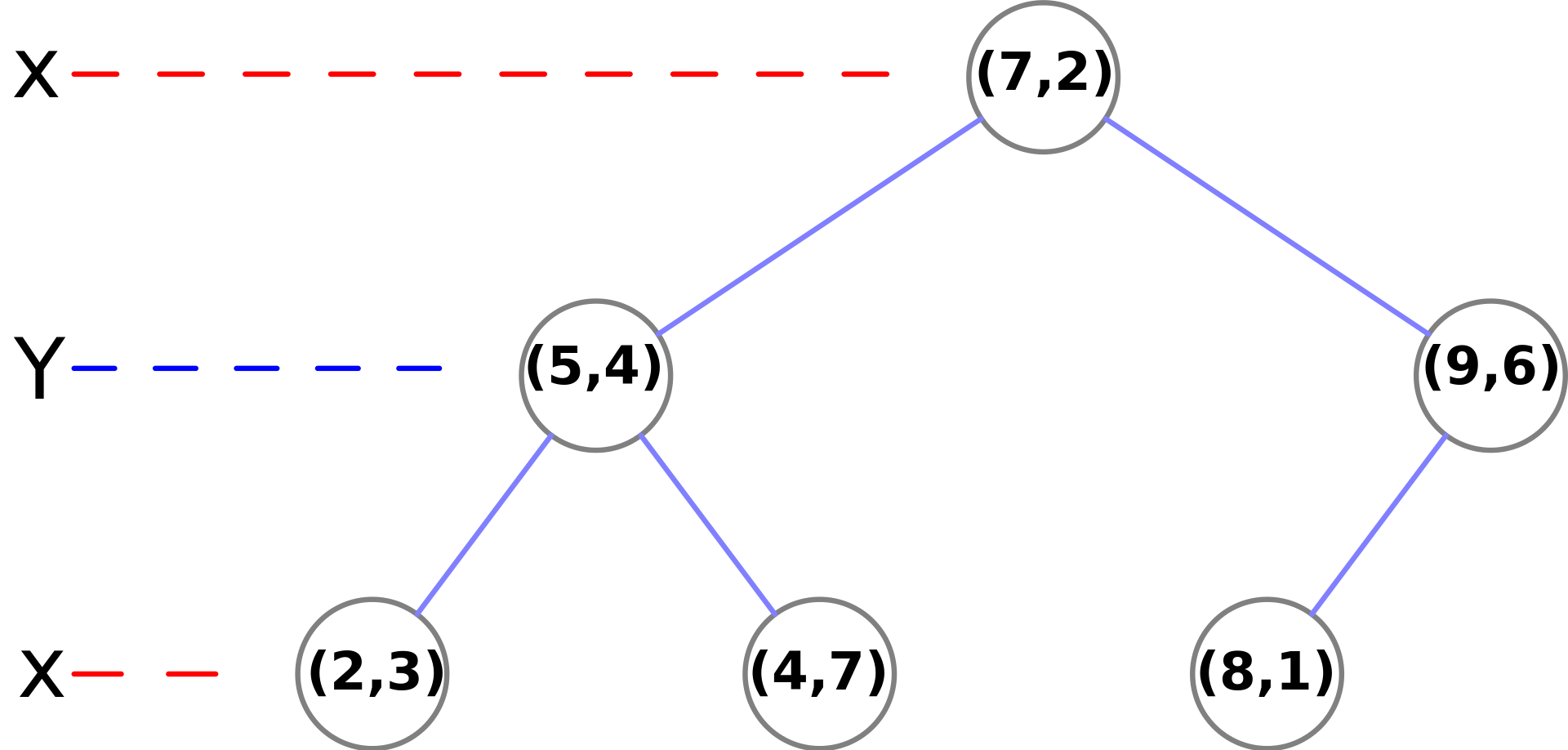
注:不是一定要选择子树中的中位数点进行平面拆分。如果未选择中位数点,则无法保证树平衡。一种常规做法是不对子树中的所有点进行排序,而是对固定数量的随机选择的点进行排序,并使用这些点的中位数作为拆分平面。在实践中,这种做法通常会产生较为平衡的树。
2. k-d-b tree
k-dimensional B-tree,k 维 B 树。k-d-b 树的目的是提供平衡的 k-d 树的搜索效率,同时提供 B 树的面向块的存储,以优化外部存储器访问。
k-d-b 树是 k-d 树和 B 树的结合。它将不同区域 k-d 树作为整体放在 B 树里。
kdb 树包含两种类型的页面:
Region pages:(区域、子树) 对的集合,其中包含区域边界的说明,以及该区域对应子页面的指针。
Point pages:(点、位置) 对的集合。
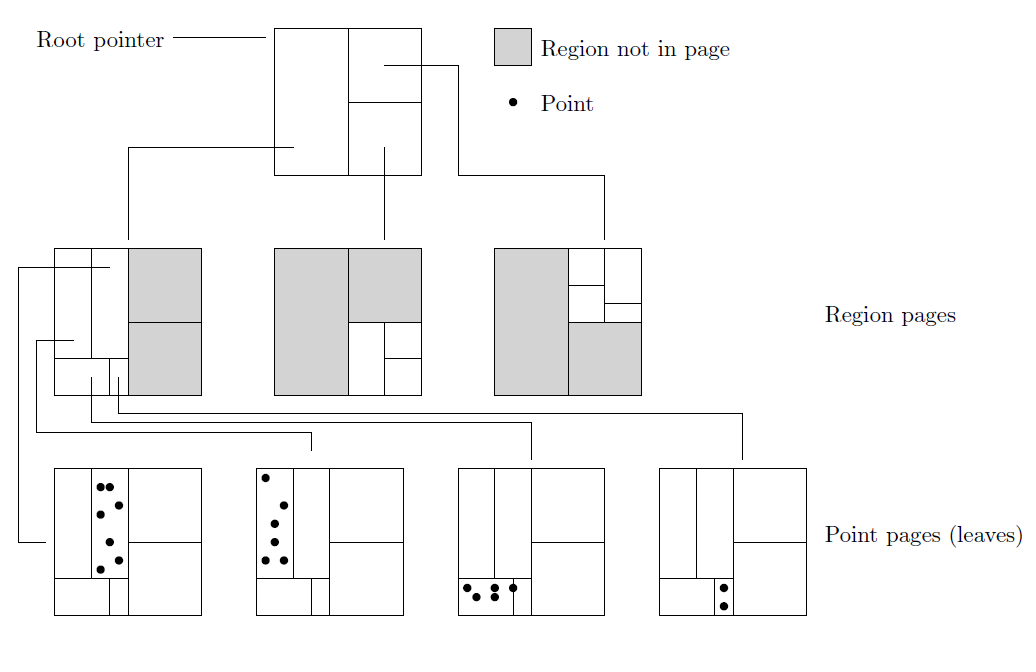
插入数据的过程中 k-d 树可能会不平衡,甚至出现二叉树退化成链表的情况。此时需要进行重建 k-d 树等操作,开销过大。

k-d-b树可以改善该问题,但局部区域k-d树仍可能退化,且拆分页面时很可能会涉及多个子区域。
故相比于k-d树,k-d-b树对于修改频繁的动态数据存储效率并没有多大改善。两者都较适用于分析静态数据。
3. b-k-d tree
设 N 是点的总数,B 是磁盘里的点数, K 是查询矩形中的点数。M 是内存缓冲区的容量,以点数表示
If N is the total number of points and B is the number of points that fit in a disk block.....Here K is the number of points in the query rectangle.
M is the capacity of the memory buffer, in number of points.
bkd 树由一组平衡的 kd 树组成。每个 kd 树在磁盘上的布局类似于 kdb 树的布局方式。
bkd 树和 kdb 树主要的不同主要存在于两个方面:批量构建 及 动态更新。
(1) 批量构建

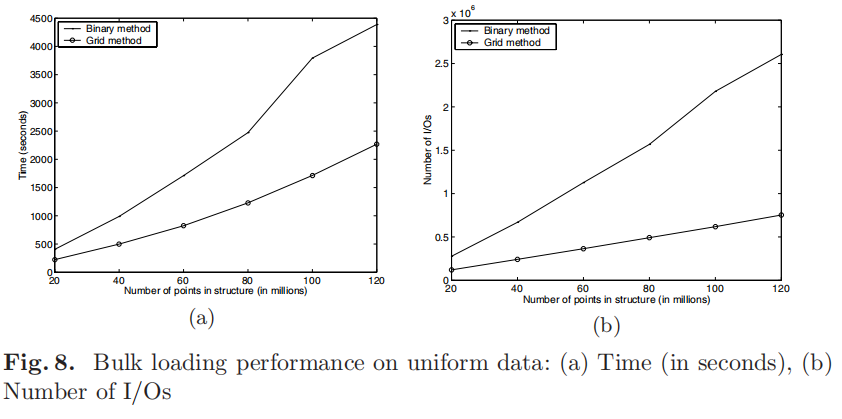
上图描述了两种批量构建 kd 树的算法,一般来说 kd 树是以二进制 binary 自上而下构建的。基于 x、y 维度创建排序列表,并以深度优先搜索插入每个节点。
但是 bkd 树采取了 grid 构建方式,基于论文 P. K. Agarwal, L . Arge, O. Procopiuc, and J. S. Vitter. A framework for index bulk loading and dynamization. In Proc. Intl. Colloq. Automata, Languages and Programming, pages 115–127, 2001.
它同样需要先创建排序列表,先构建 kd 树的 log_2t 层,其中 t = Θ(min{M/B, √M}).,然后递归构建。
最后发现 grid 的复杂度比 binary 好 Θ(log_2(M/B)) 。实验结果表明 gird I/Os 优于 binary 批量构建方式。
(2) 动态更新
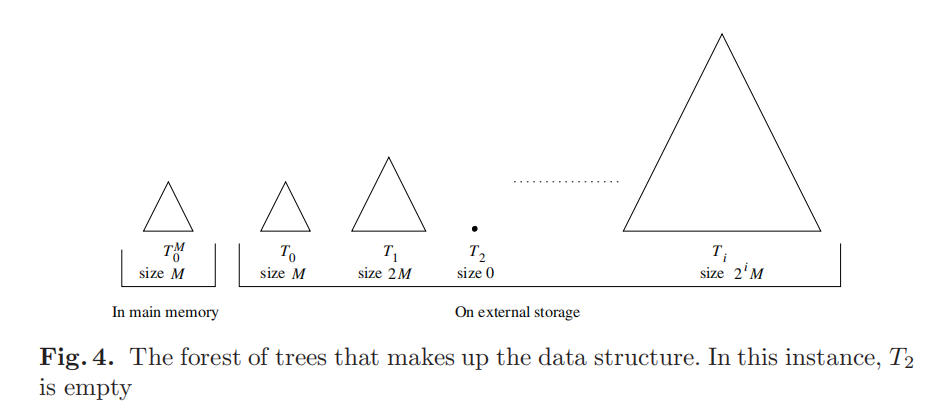
平面中 N 个点的 Bkd 树,由 log_2(N/M) 个 kd 树组成。内存中保存了这些最多包含 2^i M 个点的结构 T^M。而在外部存储中,第 T_i 个 kd 树要么是空的,要么恰好包含 2^i M 个点。

主要看一下插入算法。点插入 buffer 里的结构 T^M,若 T^M 未满,则直接插入。若 T^M 满,则找到外部存储的第一棵空 kd 树 T_k,将 T^M 和所有 T_i 中的点批量构建进去。最后清空 T^M 和 T_i,0 ≤ i < k.
清空了 T_i,那么下次重组可用的第一棵空树就是 T_i。比如要构建 T_2,那么他的前提是 T^M、T_0、T_1 都已经满了。而构建了 T_2 之后,会清空 T_0、T_1,下次重组又会从 T_0 重新开始。这样就可以实现树的大小以 2^i 的规律增长。
换句话说,点存储到内存中,并定时重组到外部存储。kd-tree 越大,需要重组的频率就越低。
这个数据结构被 Lucene6.0 之后版本用于索引多维数值类型的数据,具体代码可以查看 org.apache.lucene.util.bkd (Lucene 7.1.0 API)
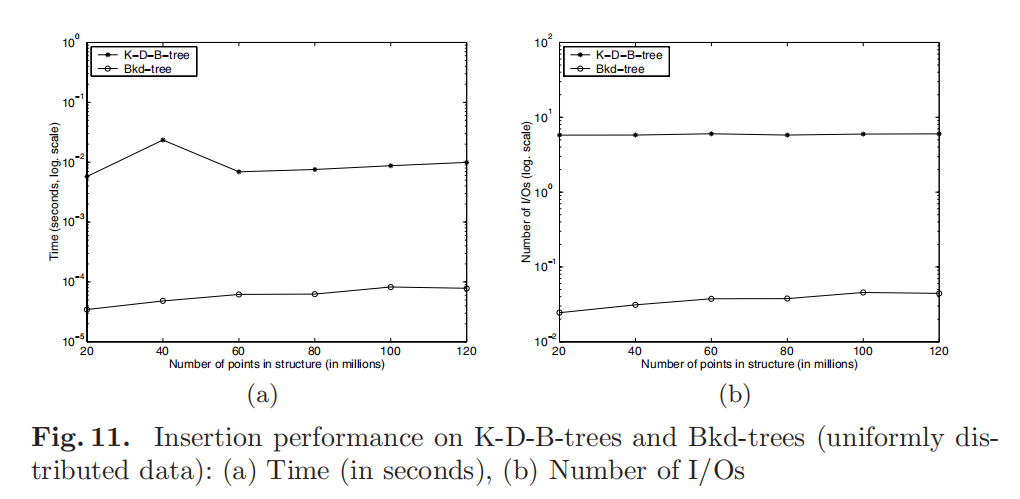
该论文的实验结果表明,Bkd?树的空间利用率高达 99%,而 KDB 树空间利用率只有 30%~50% 左右不等。Bkd?树中的插入比?KDB?树中的插入快?100?倍左右,查询等性能也表现更好。
四、总结
还是回到了文章的开头:
Elasticsearch 是一个基于 Lucene 构建的分布式、RESTful 风格的搜索和数据分析引擎。它通过有限状态转换器实现了用于全文检索的倒排索引、用于存储数值数据和地理位置数据的 BKD 树,以及用于分析的列存储。
参考:
Elasticsearch:官方分布式搜索和分析引擎 | Elastic
Api接口风格 - 腾讯云开发者社区-腾讯云 (tencent.com)
带你走进神一样的Elasticsearch索引机制 - 知乎 (zhihu.com)
elasticsearch 倒排索引原理 - 知乎 (zhihu.com)
倒排索引为什么叫倒排索引? - 知乎 (zhihu.com)
lucene字典实现原理 - zhanlijun - 博客园 (cnblogs.com)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。