[DuckDB] 多核算子并行的源码解析
[DuckDB] 多核算子并行的源码解析

DuckDB 是近年来颇受关注的OLAP数据库,号称是OLAP领域的SQLite,以精巧简单,性能优异而著称。笔者前段时间在调研Doris的Pipeline的算子并行方案,而DuckDB基于论文《Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age》实现SQL算子的高效并行化的Pipeline执行引擎,所以笔者花了一些时间进行了学习和总结,这里结合了Mark Raasveldt进行的分享和原始代码来一一剖析DuckDB在执行算子并行上的具体实现。
1. 基础知识
问题1:并行task的数目由什么决定 ?
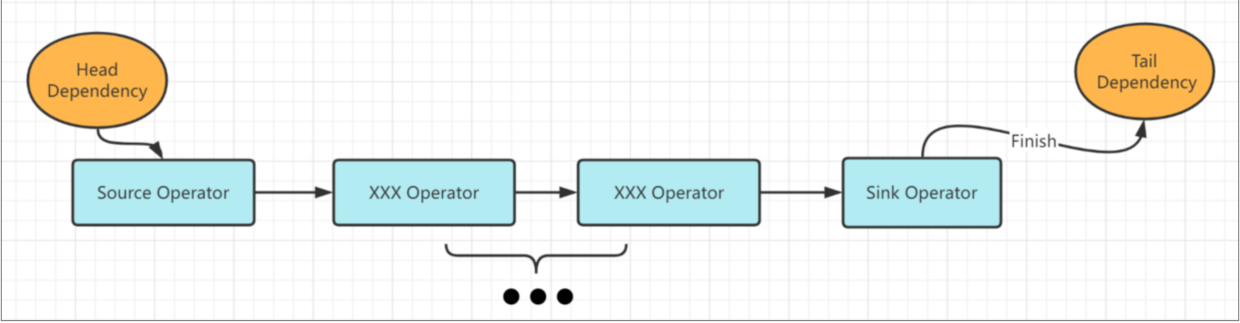
image.png
Pipeline的核心是:Morsel-Driven,数据是拆分成了小部分的数据。所以并行Task的核心是:能够利用多线程来处理数据,每一个数据拆分为小部分,所以拆分并行的数目由Source决定。
DuckDB在GlobalSource上实现了一个虚函数MaxThread来决定task数目:
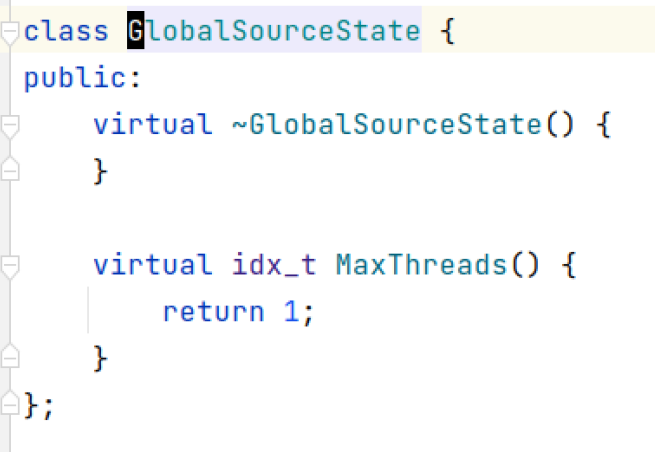
image.png
每一个算子的GlobalSource抽象了自己的并行度:
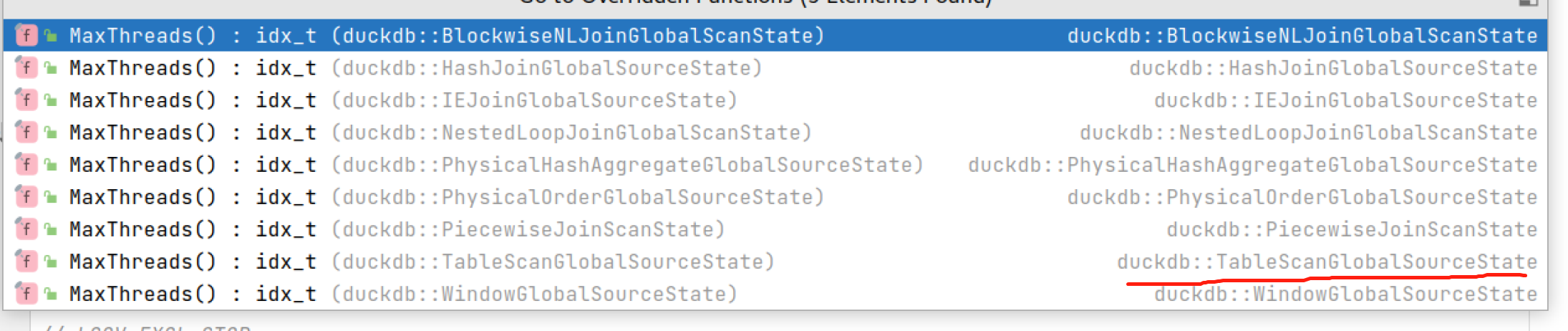
image.png
问题2:并行task的怎么样进行多线程同步:
- 多线程的竞争只会发生在SinkOperator上,也就是Pipeline的尾端。
- parallelism-aware的算法需要实现在Sink端
- 其他的非Sink operators (比如:Hash Join Probe, Projection, Filter等), 不需要感知多线程同步的问题
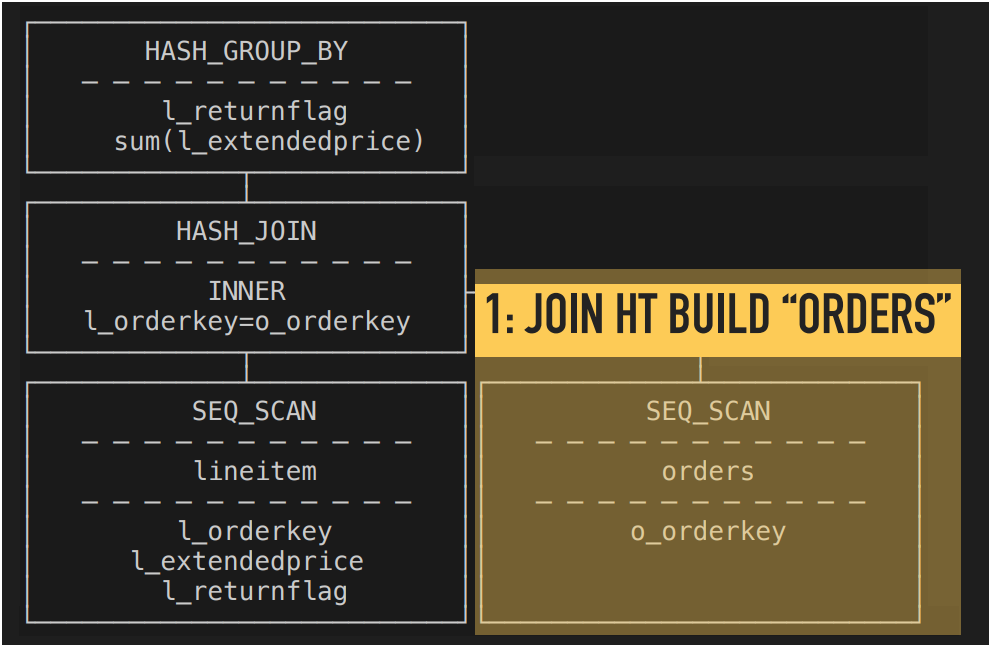
image.png
问题3:DuckDB的是如何抽象接口的:
Sink的Opeartor 定义了两种类型:GlobalState, LocalState
- GlobalState: 每个查询的Operator全局只有一个
GlobalSinkState,记录全局部分的信息
class PhysicalOperator {
public:
unique_ptr<GlobalSinkState> sink_state;- LocalState: 每个查询的PipelineExecutor都有一个
LocalSinkState,都是局部私有
//! The Pipeline class represents an execution pipeline
class PipelineExecutor {
private:
//! The local sink state (if any)
unique_ptr<LocalSinkState> local_sink_state;后续会详细解析不同的sink之间的LocalState和GlobalState如何配合的,核心部分如下:
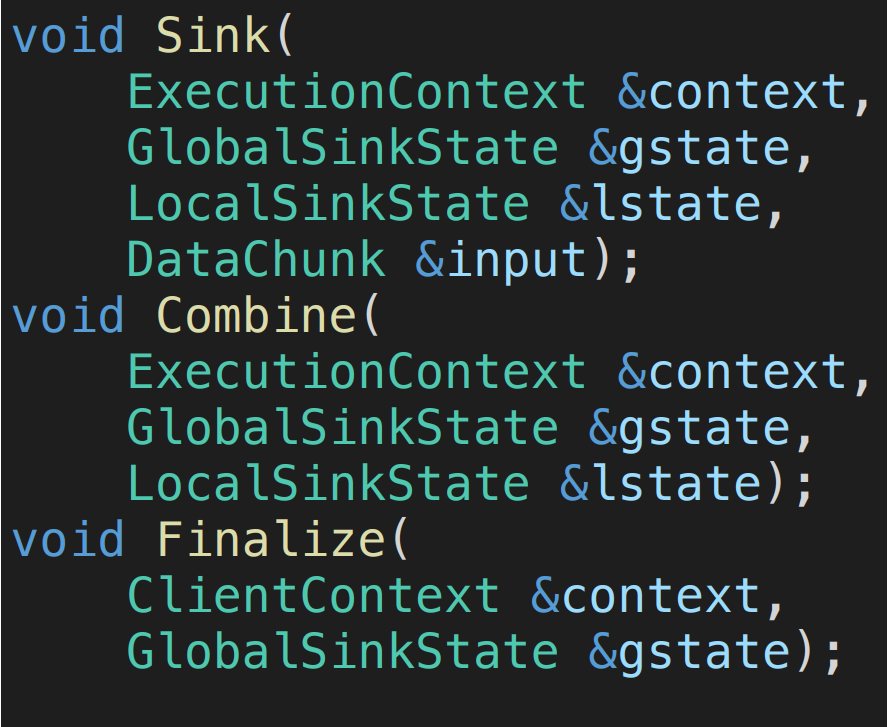
image.png
Sink :处理LocalState的数据
Combine:合并LocalState到GlobalState之中
2. 核心算子的并行
这部分进行各个算子的源码剖析,笔者在源码的关键部分加上了中文注释,以方便大家的理解
Sort算子
- Sink接口:这里需要注意的是DuckDB排序是进行了列转行的工作的,后续读取时需要行转列。Sink这部分相当于实现了部分数据的排序工作。
SinkResultType PhysicalOrder::Sink(ExecutionContext &context, GlobalSinkState &gstate_p, LocalSinkState &lstate_p,
DataChunk &input) const {
auto &lstate = (OrderLocalSinkState &)lstate_p;
// keys 是排序的列block,payload是输出的排序后数据,这里调用LocalState的SinkChunk,进行数据的转行,
local_sort_state.SinkChunk(keys, payload);
// 数据达到内存阈值的时候进行基数排序处理,排序之后的结果存入LocalState的本地的SortedBlock中
if (local_sort_state.SizeInBytes() >= gstate.memory_per_thread) {
local_sort_state.Sort(global_sort_state, true);
}
return SinkResultType::NEED_MORE_INPUT;
}- Combine接口: 加锁,拷贝sorted block到Global State
void PhysicalOrder::Combine(ExecutionContext &context, GlobalSinkState &gstate_p, LocalSinkState &lstate_p) const {
auto &gstate = (OrderGlobalSinkState &)gstate_p;
auto &lstate = (OrderLocalSinkState &)lstate_p;
// 排序剩余内存中不满的数据
local_sort_state.Sort(*this, external || !local_sort_state.sorted_blocks.empty());
// Append local state sorted data to this global state
lock_guard<mutex> append_guard(lock);
for (auto &sb : local_sort_state.sorted_blocks) {
sorted_blocks.push_back(move(sb));
}
}- MergeTask:启动核数相同的task来进行Merge (这里可以看出DuckDB对于多线程的使用是很激进的), 这里是通过Event的机制实现的
void Schedule() override {
auto &context = pipeline->GetClientContext();
idx_t num_threads = ts.NumberOfThreads();
vector<unique_ptr<Task>> merge_tasks;
for (idx_t tnum = 0; tnum < num_threads; tnum++) {
merge_tasks.push_back(make_unique<PhysicalOrderMergeTask>(shared_from_this(), context, gstate));
}
SetTasks(move(merge_tasks));
}
class PhysicalOrderMergeTask : public ExecutorTask {
public:
TaskExecutionResult ExecuteTask(TaskExecutionMode mode) override {
// Initialize merge sorted and iterate until done
auto &global_sort_state = state.global_sort_state;
MergeSorter merge_sorter(global_sort_state, BufferManager::GetBufferManager(context));
// 加锁,获取两路,不断进行两路归并,最终完成全局排序。
while (true) {
{
lock_guard<mutex> pair_guard(state.lock);
if (state.pair_idx == state.num_pairs) {
break;
}
GetNextPartition();
}
MergePartition();
}
event->FinishTask();
return TaskExecutionResult::TASK_FINISHED;
}聚合算子(这里分析的是Prefetch Agg Operator算子)
- Sink接口:和Sort算子一样,这里拆分为
Group Chunk和Aggregate Input Chunk,可以理解为代表聚合时的key与value列。注意此时Sink接口上的聚合是在LocalSinkState上完成的。
SinkResultType PhysicalPerfectHashAggregate::Sink(ExecutionContext &context, GlobalSinkState &state,
LocalSinkState &lstate_p, DataChunk &input) const {
lstate.ht->AddChunk(group_chunk, aggregate_input_chunk);
}
void PerfectAggregateHashTable::AddChunk(DataChunk &groups, DataChunk &payload) {
auto address_data = FlatVector::GetData<uintptr_t>(addresses);
memset(address_data, 0, groups.size() * sizeof(uintptr_t));
D_ASSERT(groups.ColumnCount() == group_minima.size());
// 计算group key列对应的entry的位置
idx_t current_shift = total_required_bits;
for (idx_t i = 0; i < groups.ColumnCount(); i++) {
current_shift -= required_bits[i];
ComputeGroupLocation(groups.data[i], group_minima[i], address_data, current_shift, groups.size());
}
// 通过data加上面的entry位置 + tuple的偏移量,计算出对应的内存地址,并进行init
idx_t needs_init = 0;
for (idx_t i = 0; i < groups.size(); i++) {
D_ASSERT(address_data[i] < total_groups);
const auto group = address_data[i];
address_data[i] = uintptr_t(data) + address_data[i] * tuple_size;
}
RowOperations::InitializeStates(layout, addresses, sel, needs_init);
// after finding the group location we update the aggregates
idx_t payload_idx = 0;
auto &aggregates = layout.GetAggregates();
for (idx_t aggr_idx = 0; aggr_idx < aggregates.size(); aggr_idx++) {
auto &aggregate = aggregates[aggr_idx];
auto input_count = (idx_t)aggregate.child_count;
// 进行聚合的Update操作
RowOperations::UpdateStates(aggregate, addresses, payload, payload_idx, payload.size());
}
}- Combine接口: 加锁,merge
local hash table与global hash table
void PhysicalPerfectHashAggregate::Combine(ExecutionContext &context, GlobalSinkState &gstate_p,
LocalSinkState &lstate_p) const {
auto &lstate = (PerfectHashAggregateLocalState &)lstate_p;
auto &gstate = (PerfectHashAggregateGlobalState &)gstate_p;
lock_guard<mutex> l(gstate.lock);
gstate.ht->Combine(*lstate.ht);
} // local state的地址vector
Vector source_addresses(LogicalType::POINTER);
// global state的地址vector
Vector target_addresses(LogicalType::POINTER);
auto source_addresses_ptr = FlatVector::GetData<data_ptr_t>(source_addresses);
auto target_addresses_ptr = FlatVector::GetData<data_ptr_t>(target_addresses);
// 遍历所有hash table的表,然后进行合并对应能够合并的key
data_ptr_t source_ptr = other.data;
data_ptr_t target_ptr = data;
idx_t combine_count = 0;
idx_t reinit_count = 0;
const auto &reinit_sel = *FlatVector::IncrementalSelectionVector();
for (idx_t i = 0; i < total_groups; i++) {
auto has_entry_source = other.group_is_set[i];
// we only have any work to do if the source has an entry for this group
if (has_entry_source) {
auto has_entry_target = group_is_set[i];
if (has_entry_target) {
// both source and target have an entry: need to combine
source_addresses_ptr[combine_count] = source_ptr;
target_addresses_ptr[combine_count] = target_ptr;
combine_count++;
if (combine_count == STANDARD_VECTOR_SIZE) {
RowOperations::CombineStates(layout, source_addresses, target_addresses, combine_count);
combine_count = 0;
}
} else {
group_is_set[i] = true;
// only source has an entry for this group: we can just memcpy it over
memcpy(target_ptr, source_ptr, tuple_size);
// we clear this entry in the other HT as we "consume" the entry here
other.group_is_set[i] = false;
}
}
source_ptr += tuple_size;
target_ptr += tuple_size;
}
// 做对应的merge操作
RowOperations::CombineStates(layout, source_addresses, target_addresses, combine_count);Join算子
- Sink接口:和Sort算子一样,注意此时Sink接口上的hash 表是在LocalSinkState上完成的。
SinkResultType PhysicalHashJoin::Sink(ExecutionContext &context, GlobalSinkState &gstate_p, LocalSinkState &lstate_p,
DataChunk &input) const {
auto &gstate = (HashJoinGlobalSinkState &)gstate_p;
auto &lstate = (HashJoinLocalSinkState &)lstate_p;
lstate.join_keys.Reset();
lstate.build_executor.Execute(input, lstate.join_keys);
// build the HT
auto &ht = *lstate.hash_table;
if (!right_projection_map.empty()) {
// there is a projection map: fill the build chunk with the projected columns
lstate.build_chunk.Reset();
lstate.build_chunk.SetCardinality(input);
for (idx_t i = 0; i < right_projection_map.size(); i++) {
lstate.build_chunk.data[i].Reference(input.data[right_projection_map[i]]);
}
// 构建local state的hash 表
ht.Build(lstate.join_keys, lstate.build_chunk)
return SinkResultType::NEED_MORE_INPUT;
}- Combine接口: 加锁,拷贝local state的hash表到global state
void PhysicalHashJoin::Combine(ExecutionContext &context, GlobalSinkState &gstate_p, LocalSinkState &lstate_p) const {
auto &gstate = (HashJoinGlobalSinkState &)gstate_p;
auto &lstate = (HashJoinLocalSinkState &)lstate_p;
if (lstate.hash_table) {
lock_guard<mutex> local_ht_lock(gstate.lock);
gstate.local_hash_tables.push_back(move(lstate.hash_table));
}
}- MergeTask:启动核数相同的task来进行Hash table的Merge (这里可以看出DuckDB对于多线程的使用是很激进的), 每个任务merge一部分Block(DuckDB之中的行数据,落盘使用)
void Schedule() override {
auto &context = pipeline->GetClientContext();
vector<unique_ptr<Task>> finalize_tasks;
auto &ht = *sink.hash_table;
const auto &block_collection = ht.GetBlockCollection();
const auto &blocks = block_collection.blocks;
const auto num_blocks = blocks.size();
if (block_collection.count < PARALLEL_CONSTRUCT_THRESHOLD && !context.config.verify_parallelism) {
// Single-threaded finalize
finalize_tasks.push_back(
make_unique<HashJoinFinalizeTask>(shared_from_this(), context, sink, 0, num_blocks, false));
} else {
// Parallel finalize
idx_t num_threads = TaskScheduler::GetScheduler(context).NumberOfThreads();
auto blocks_per_thread = MaxValue<idx_t>((num_blocks + num_threads - 1) / num_threads, 1);
idx_t block_idx = 0;
for (idx_t thread_idx = 0; thread_idx < num_threads; thread_idx++) {
auto block_idx_start = block_idx;
auto block_idx_end = MinValue<idx_t>(block_idx_start + blocks_per_thread, num_blocks);
finalize_tasks.push_back(make_unique<HashJoinFinalizeTask>(shared_from_this(), context, sink,
block_idx_start, block_idx_end, true));
block_idx = block_idx_end;
if (block_idx == num_blocks) {
break;
}
}
}
SetTasks(move(finalize_tasks));
}
template <bool PARALLEL>
static inline void InsertHashesLoop(atomic<data_ptr_t> pointers[], const hash_t indices[], const idx_t count,
const data_ptr_t key_locations[], const idx_t pointer_offset) {
for (idx_t i = 0; i < count; i++) {
auto index = indices[i];
if (PARALLEL) {
data_ptr_t head;
do {
head = pointers[index];
Store<data_ptr_t>(head, key_locations[i] + pointer_offset);
} while (!std::atomic_compare_exchange_weak(&pointers[index], &head, key_locations[i]));
} else {
// set prev in current key to the value (NOTE: this will be nullptr if there is none)
Store<data_ptr_t>(pointers[index], key_locations[i] + pointer_offset);
// set pointer to current tuple
pointers[index] = key_locations[i];
}
}
}- 并行扫描hash表,进行outer数据的处理:
void PhysicalHashJoin::GetData(ExecutionContext &context, DataChunk &chunk, GlobalSourceState &gstate_p,
LocalSourceState &lstate_p) const {
auto &sink = (HashJoinGlobalSinkState &)*sink_state;
auto &gstate = (HashJoinGlobalSourceState &)gstate_p;
auto &lstate = (HashJoinLocalSourceState &)lstate_p;
sink.scanned_data = true;
if (!sink.external) {
if (IsRightOuterJoin(join_type)) {
{
lock_guard<mutex> guard(gstate.lock);
// 拆解扫描部分hash表的数据
lstate.ScanFullOuter(sink, gstate);
}
// 扫描hash表读取数据
sink.hash_table->GatherFullOuter(chunk, lstate.addresses, lstate.full_outer_found_entries);
}
return;
}
}
void HashJoinLocalSourceState::ScanFullOuter(HashJoinGlobalSinkState &sink, HashJoinGlobalSourceState &gstate) {
auto &fo_ss = gstate.full_outer_scan;
idx_t scan_index_before = fo_ss.scan_index;
full_outer_found_entries = sink.hash_table->ScanFullOuter(fo_ss, addresses);
idx_t scanned = fo_ss.scan_index - scan_index_before;
full_outer_in_progress = scanned;
}小结
- DuckDB在多线程同步,核心就是在Combine的时候:加锁,并发是通过原子变量的方式实现并发写入hash表的操作
- 通过
local/global拆分私有内存和公共内存,并发的基础是在私有内存上进行运算,同步的部分主要在公有内存的更新
3. Spill To Disk的实现
DuckDB并没有如笔者预期的实现异步IO, 所以任意的执行线程是有可能Stall在系统的I/O调度上的,我想大概率是DuckDB本身的定位对于高并发场景的支持不是那么敏感所导致的。这里他们也作为了后续TODO的计划之一。

image.png