【ES三周年】一亿数据写入 ES :耗时 512 秒
原创
一、前言
本文目的: 实践亿级数据集群规划。
心路历程:百万数据压测 -> 优化参数 -> 推测亿级数据容量 -> 规划集群规模。
先来了解下,ES 集群规划: 3 个节点,ES 内存 -Xms8g -Xmx8g,剩下内存要预留给 PageCache
集群名 | 节点名称 | 端口 | 机器配置 |
|---|---|---|---|
escluster | esnode-1 | 9300 9800 | 8C16G |
escluster | esnode-2 | 9300 9800 | 8C16G |
escluster | esnode-3 | 9300 9800 | 8C16G |
kibana | 9000 | 2C4G | |
es-service | 8080 | 4C8G |
磁盘容量规划
根据前文压测 100W 数据结果可知: 主分片总共占用了 200MB 的磁盘空间。
- 这样,我们可以计算出每个文档占用的磁盘空间大概是:
0.2048 KB - 然后可以推算出 1 亿个文档占用的磁盘空间大概是:
20000 MB ≈ 19.5 GB - 如果每个分片 1 个副本, 那么就是
19.5 * 2 = 39GB(大概值)
有三个实例,每个实例磁盘 40GB,总共 120GB,对于 1亿 数据量的场景完全够用。
ES 写入优化
根据 官网文档 写入优化有:
Use bulk requests:使用批量bulk上传。Use multiple workers/threads to send data to Elasticsearch:使用多线程。Unset or increase the refresh interval:<font color=red>设置refresh_interval值,默认 1s。 </font>
ES的近实时搜索: 写入后 1s 就能搜索到。即默认每秒刷新一下。为了优化写入速度,可提高该值,从而减少频繁的
refresh和lucene段合并。
配置项 | 默认值 | 优化 |
|---|---|---|
| 1s | 30s(官方推荐),120s |
Disable replicas fo initial loads:<font color=red>初始时将副本数改为 0,数据写入完成后再改回来。</font> (提升巨大),此配置可以 动态调整 。
配置项 | 默认值 | 优化 |
|---|---|---|
| 1 | 0 |
Disable swapping:关闭交换区。Give memory to the filesystem cache:给PageCache足够的内存。 (写入数据和读取数据都需要)Use auto-generated ids:使用自动生成的id。Use faster hardware:云主机有限制,当前云盘是性能最低的PL0性能级别的ESSD云盘。Indexing buffer size: 索引缓冲大小 ,默认 10%,即JVM10GB、索引缓冲区 1GB。
配置项 | 默认值 | 优化 |
|---|---|---|
| 10% | 30% |
| 48MB | 128MB |
| 无限制 | 无限制 |
其他优化点:
translog:来记录两次flush(fsync) 之间所有的操作,当机器从故障中恢复或者重启,可以根据此还原
- 对应官方文档
translog是文件,存在于内存中,如果掉电一样会丢失。- <font color=red>默认每隔 5s 刷一次到磁盘中</font>
配置项 | 默认值 | 优化 |
|---|---|---|
| request | async |
| 5s | 120s |
| 512MB | 2048MB |
二、亿级数据写入
写入步骤如下:
- 创建索引 (优化后)
PUT /sku_index
{
"settings":{
"number_of_shards":3,
"number_of_replicas":0,
"index.refresh_interval": "120s",
"index.translog.durability": "async",
"index.translog.sync_interval": "120s",
"index.translog.flush_threshold_size": "2048mb"
},
"mappings":{
"properties":{
"skuId":{
"type":"keyword"
},
"skuName":{
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"category":{
"type":"keyword"
},
"basePrice":{
"type":"integer"
},
"vipPrice":{
"type":"integer"
},
"saleCount":{
"type":"integer"
},
"commentCount":{
"type":"integer"
},
"skuImgUrl":{
"type":"keyword",
"index":false
},
"createTime":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss"
},
"updateTime":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss"
}
}
}
}可以使用 Kibana 来创建:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "sku_index"
}- 接口请求
- 操作索引:
sku_index索引 - 每次批量插入 1000 条商品
- 一共执行 100000 次批量插入
- 60 个线程
POST http://47.99.221.206:8080/api/mockData/mockData2
{
"indexName": "sku_index",
"batchSize": 1000,
"batchTimes": 100000,
"threadCount": 60
}
响应内容:
{
"success": true,
"data": {
"startTime": "2022-04-09 18:17:07",
"endTime": "2022-04-09 18:25:39",
"totalCount": 100000000,
"elapsedSeconds": 512,
"perSecond": 195312
},
"errorCode": null,
"errorMessage": null
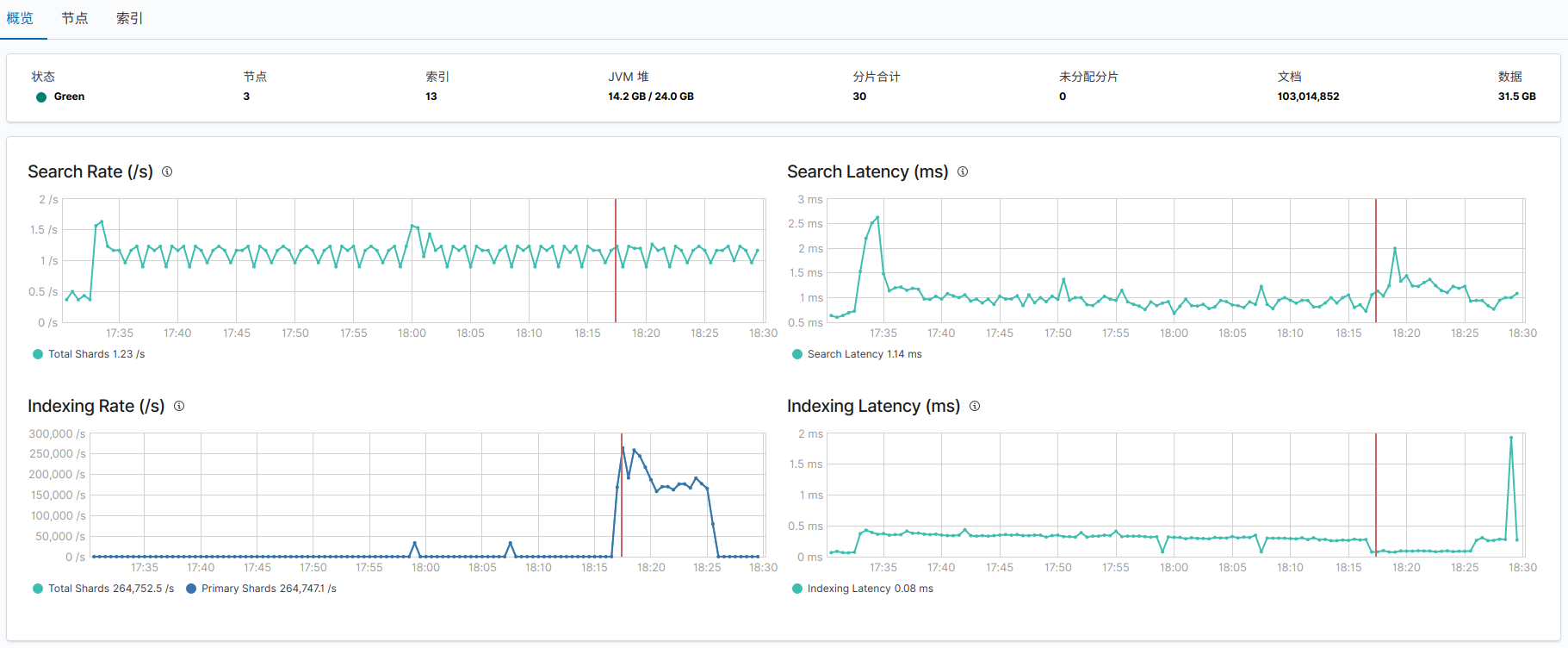
}- 查看索引信息
# 查看索引下文档的个数
GET /_cat/count/sku_index?v&h=count
count
100000000
# 查看索引下文档的个数,索引占用的磁盘空间等
GET /_cat/indices/sku_index?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open sku_index Wv9u23BLQueI7R0dYQjv5w 3 0 100000000 0 27.3gb 27.3gb- 服务端日志:
2022-04-09 18:25:40.077 INFO 1650 --- [nio-8080-exec-7] c.c.e.controller.MockDataController : 此次共导入[100000000]条商品数据,耗时[512]秒,平均每秒导入[195312]条数据
此次共导入[100000000]条商品数据,耗时[512]秒,平均每秒导入[195312]条数据- 机器监控
线程数 | 导入数据量 | 耗时 | QPS | CPU使用率 | 网络带宽使用率 | 云盘带宽使用率 |
|---|---|---|---|---|---|---|
1 | 100000000 | 512S | 195312条/s | 42.52% | 699.89 Mbit/s | 12.12 次/s |
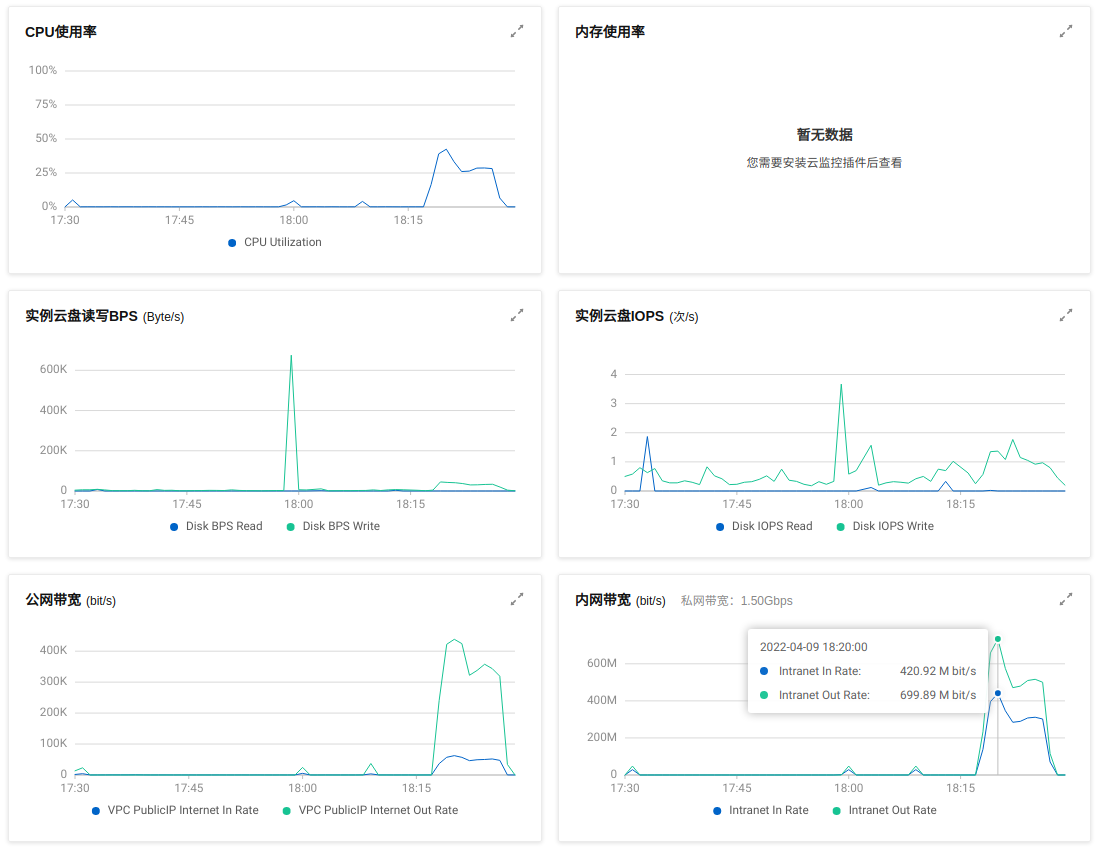
- 把副本数从 0 设置为 1
修改方式,参考文档:官方文档
PUT /sku_index/_settings
{
"settings": {
"number_of_replicas": 1
}
}
响应:
{
"acknowledged" : true
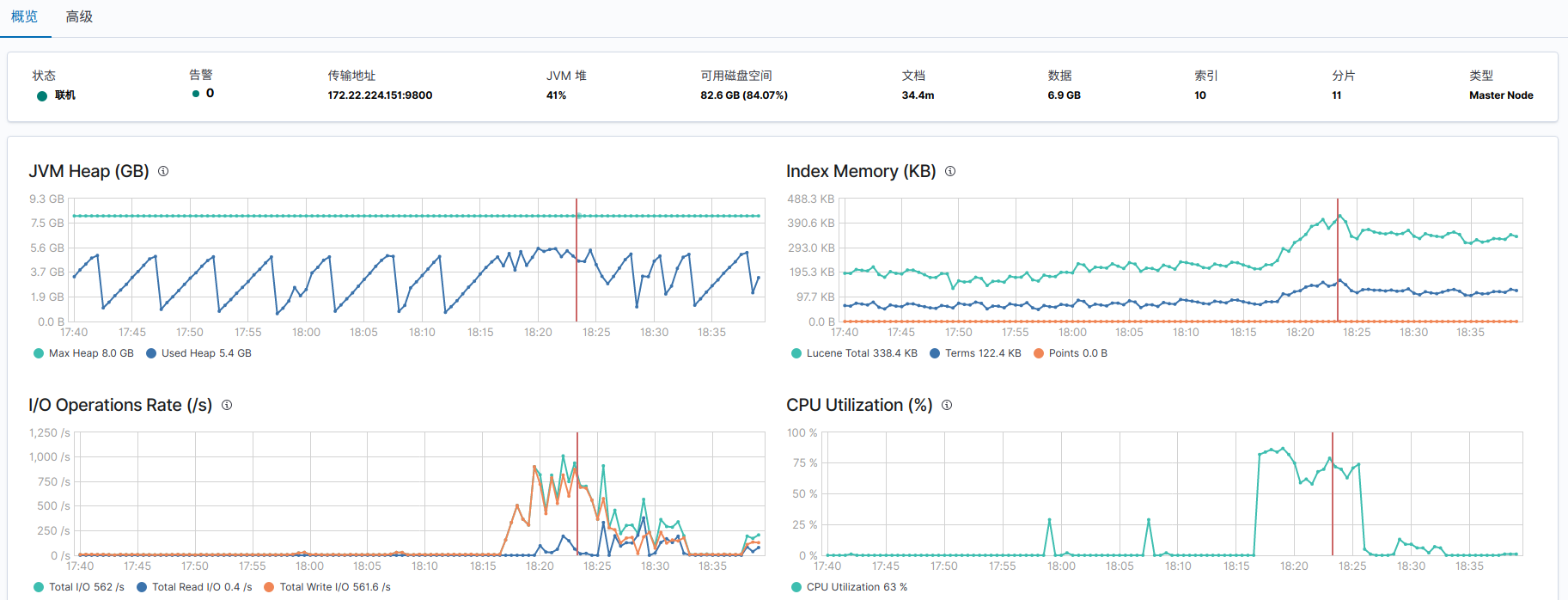
}此时,索引状态变为 yellow 状态。
通过 Kibana 查看:堆栈检测 -> 索引
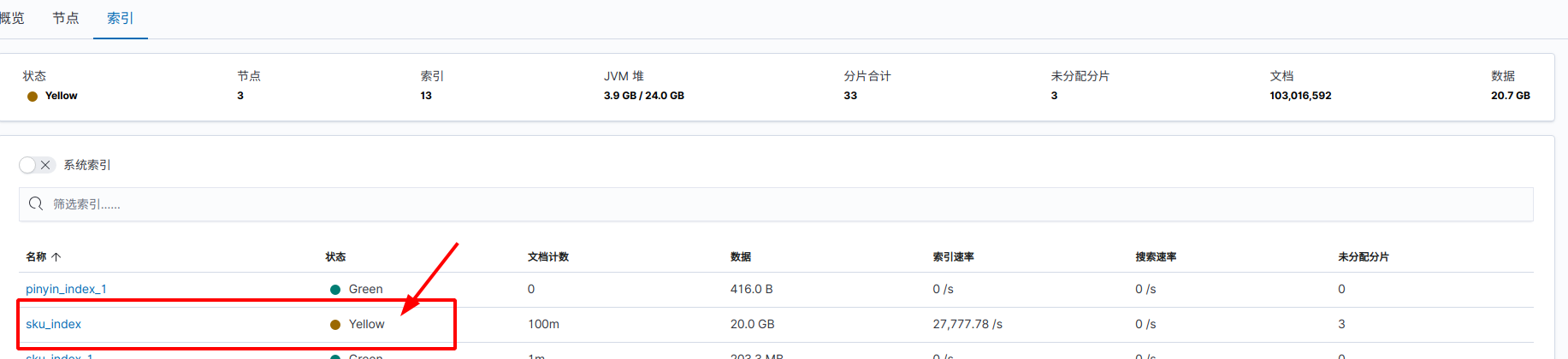
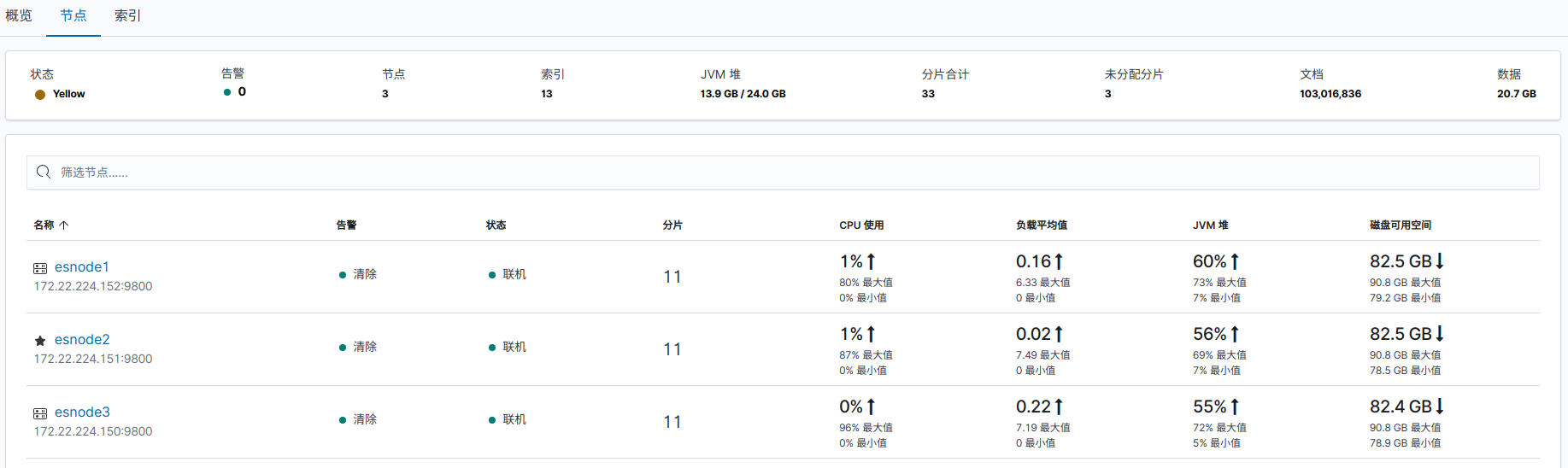

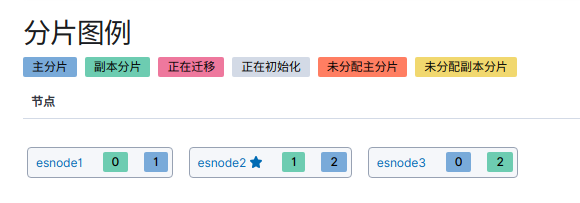
分配完后:
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。